 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Benefits of Bad Advice: Autocontrastive Decoding across Model Layers
May 02, 2023



Applying language models to natural language processing tasks typically relies on the representations in the final model layer, as intermediate hidden layer representations are presumed to be less informative. In this work, we argue that due to the gradual improvement across model layers, additional information can be gleaned from the contrast between higher and lower layers during inference. Specifically, in choosing between the probable next token predictions of a generative model, the predictions of lower layers can be used to highlight which candidates are best avoided. We propose a novel approach that utilizes the contrast between layers to improve text generation outputs, and show that it mitigates degenerative behaviors of the model in open-ended generation, significantly improving the quality of generated texts. Furthermore, our results indicate that contrasting between model layers at inference time can yield substantial benefits to certain aspects of general language model capabilities, more effectively extracting knowledge during inference from a given set of model parameters.
VIRATrustData: A Trust-Annotated Corpus of Human-Chatbot Conversations About COVID-19 Vaccines
May 24, 2022
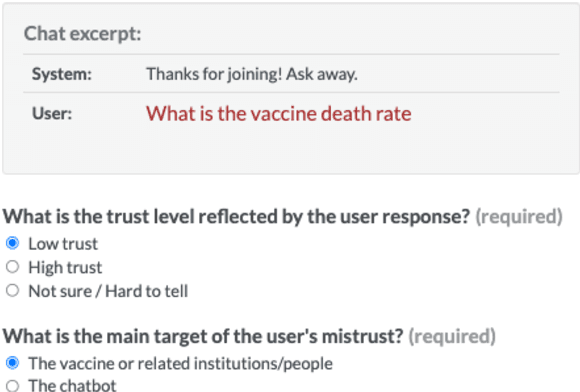
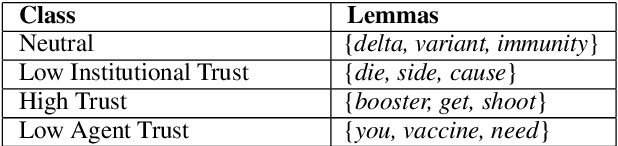
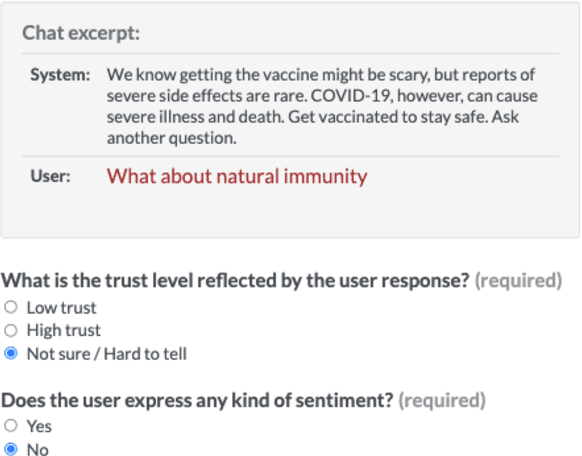
Public trust in medical information is crucial for successful application of public health policies such as vaccine uptake. This is especially true when the information is offered remotely, by chatbots, which have become increasingly popular in recent years. Here, we explore the challenging task of human-bot turn-level trust classification. We rely on a recently released data of observationally-collected (rather than crowdsourced) dialogs with VIRA chatbot, a COVID-19 Vaccine Information Resource Assistant. These dialogs are centered around questions and concerns about COVID-19 vaccines, where trust is particularly acute. We annotated $3k$ VIRA system-user conversational turns for Low Institutional Trust or Low Agent Trust vs. Neutral or High Trust. We release the labeled dataset, VIRATrustData, the first of its kind to the best of our knowledge. We demonstrate how this task is non-trivial and compare several models that predict the different levels of trust.
Benchmark Data and Evaluation Framework for Intent Discovery Around COVID-19 Vaccine Hesitancy
May 24, 2022
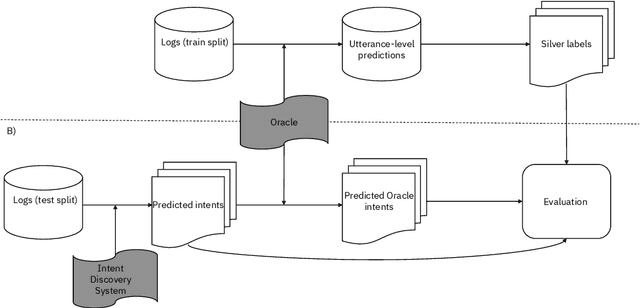

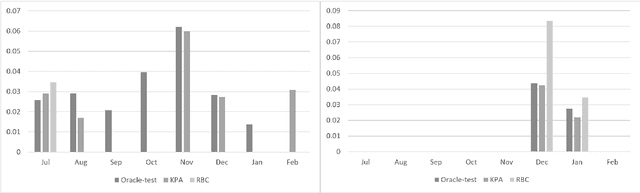
The COVID-19 pandemic has made a huge global impact and cost millions of lives. As COVID-19 vaccines were rolled out, they were quickly met with widespread hesitancy. To address the concerns of hesitant people, we launched VIRA, a public dialogue system aimed at addressing questions and concerns surrounding the COVID-19 vaccines. Here, we release VIRADialogs, a dataset of over 8k dialogues conducted by actual users with VIRA, providing a unique real-world conversational dataset. In light of rapid changes in users' intents, due to updates in guidelines or as a response to new information, we highlight the important task of intent discovery in this use-case. We introduce a novel automatic evaluation framework for intent discovery, leveraging the existing intent classifier of a given dialogue system. We use this framework to report baseline intent-discovery results over VIRADialogs, that highlight the difficulty of this task.
Overview of the 2021 Key Point Analysis Shared Task
Oct 20, 2021
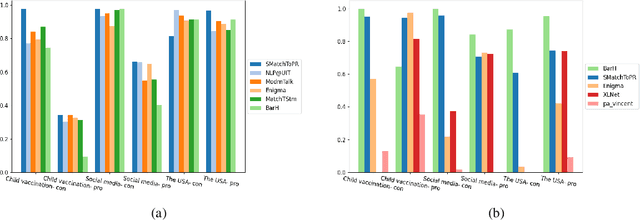
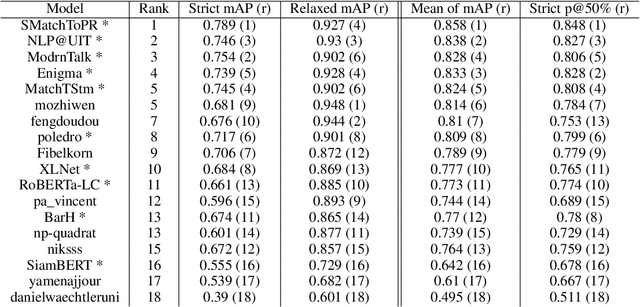
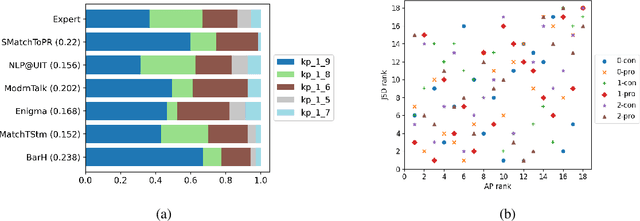
We describe the 2021 Key Point Analysis (KPA-2021) shared task on key point analysis that we organized as a part of the 8th Workshop on Argument Mining (ArgMining 2021) at EMNLP 2021. We outline various approaches and discuss the results of the shared task. We expect the task and the findings reported in this paper to be relevant for researchers working on text summarization and argument mining.
Every Bite Is an Experience: Key Point Analysis of Business Reviews
Jun 12, 2021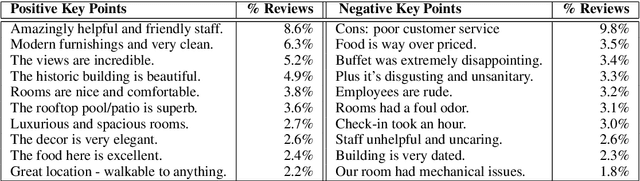
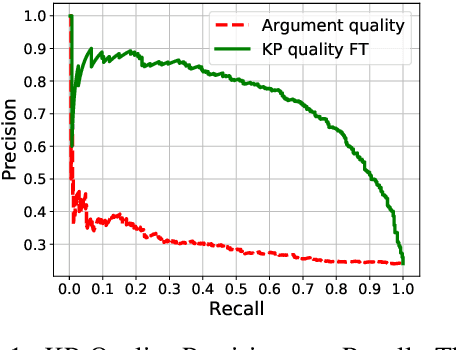

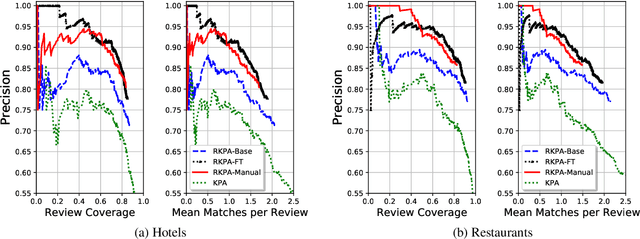
Previous work on review summarization focused on measuring the sentiment toward the main aspects of the reviewed product or business, or on creating a textual summary. These approaches provide only a partial view of the data: aspect-based sentiment summaries lack sufficient explanation or justification for the aspect rating, while textual summaries do not quantify the significance of each element, and are not well-suited for representing conflicting views. Recently, Key Point Analysis (KPA) has been proposed as a summarization framework that provides both textual and quantitative summary of the main points in the data. We adapt KPA to review data by introducing Collective Key Point Mining for better key point extraction; integrating sentiment analysis into KPA; identifying good key point candidates for review summaries; and leveraging the massive amount of available reviews and their metadata. We show empirically that these novel extensions of KPA substantially improve its performance. We demonstrate that promising results can be achieved without any domain-specific annotation, while human supervision can lead to further improvement.
Quantitative Argument Summarization and Beyond: Cross-Domain Key Point Analysis
Oct 11, 2020

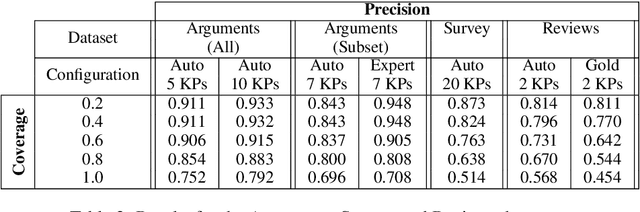
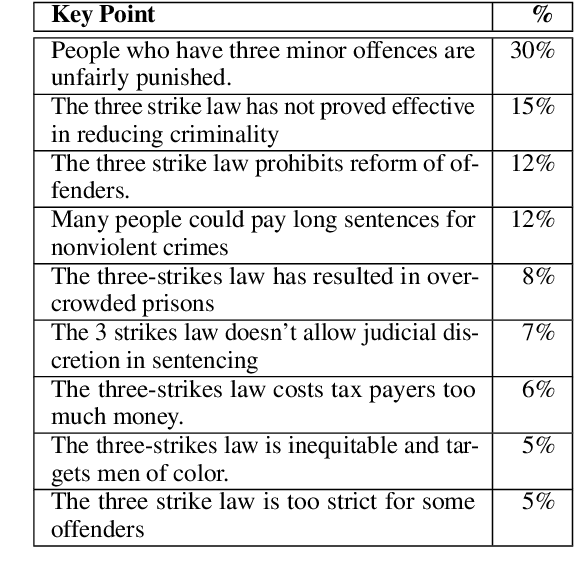
When summarizing a collection of views, arguments or opinions on some topic, it is often desirable not only to extract the most salient points, but also to quantify their prevalence. Work on multi-document summarization has traditionally focused on creating textual summaries, which lack this quantitative aspect. Recent work has proposed to summarize arguments by mapping them to a small set of expert-generated key points, where the salience of each key point corresponds to the number of its matching arguments. The current work advances key point analysis in two important respects: first, we develop a method for automatic extraction of key points, which enables fully automatic analysis, and is shown to achieve performance comparable to a human expert. Second, we demonstrate that the applicability of key point analysis goes well beyond argumentation data. Using models trained on publicly available argumentation datasets, we achieve promising results in two additional domains: municipal surveys and user reviews. An additional contribution is an in-depth evaluation of argument-to-key point matching models, where we substantially outperform previous results.
From Arguments to Key Points: Towards Automatic Argument Summarization
May 04, 2020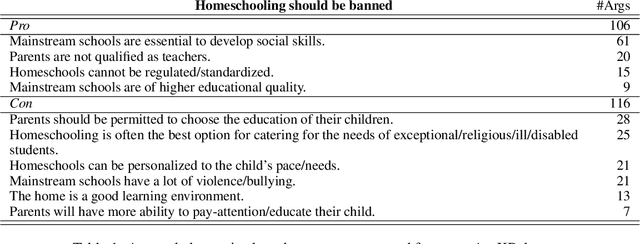
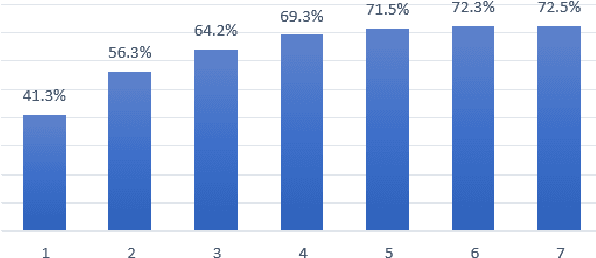
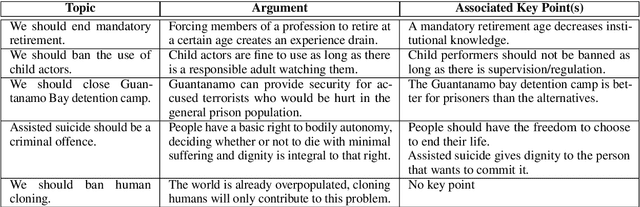
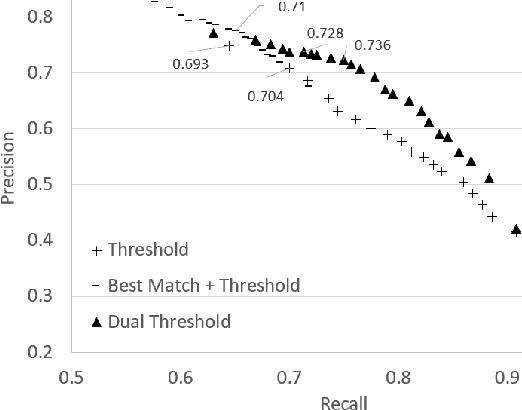
Generating a concise summary from a large collection of arguments on a given topic is an intriguing yet understudied problem. We propose to represent such summaries as a small set of talking points, termed "key points", each scored according to its salience. We show, by analyzing a large dataset of crowd-contributed arguments, that a small number of key points per topic is typically sufficient for covering the vast majority of the arguments. Furthermore, we found that a domain expert can often predict these key points in advance. We study the task of argument-to-key point mapping, and introduce a novel large-scale dataset for this task. We report empirical results for an extensive set of experiments with this dataset, showing promising performance.
A Large-scale Dataset for Argument Quality Ranking: Construction and Analysis
Nov 26, 2019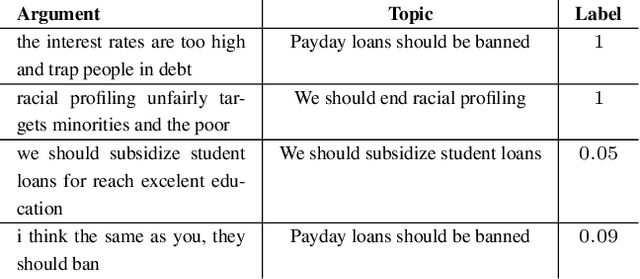
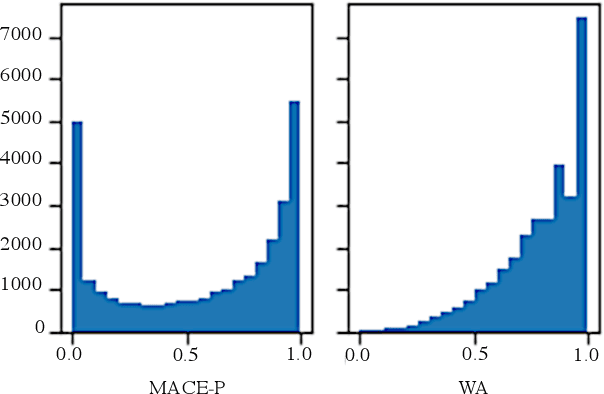

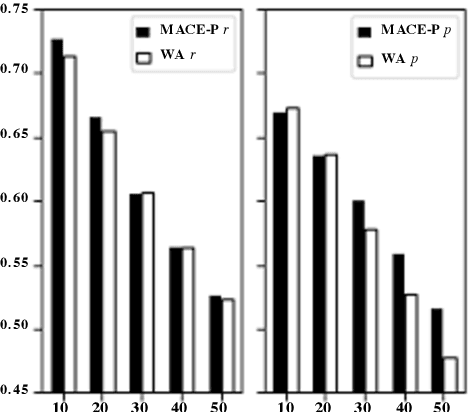
Identifying the quality of free-text arguments has become an important task in the rapidly expanding field of computational argumentation. In this work, we explore the challenging task of argument quality ranking. To this end, we created a corpus of 30,497 arguments carefully annotated for point-wise quality, released as part of this work. To the best of our knowledge, this is the largest dataset annotated for point-wise argument quality, larger by a factor of five than previously released datasets. Moreover, we address the core issue of inducing a labeled score from crowd annotations by performing a comprehensive evaluation of different approaches to this problem. In addition, we analyze the quality dimensions that characterize this dataset. Finally, we present a neural method for argument quality ranking, which outperforms several baselines on our own dataset, as well as previous methods published for another dataset.
Automatic Argument Quality Assessment -- New Datasets and Methods
Sep 03, 2019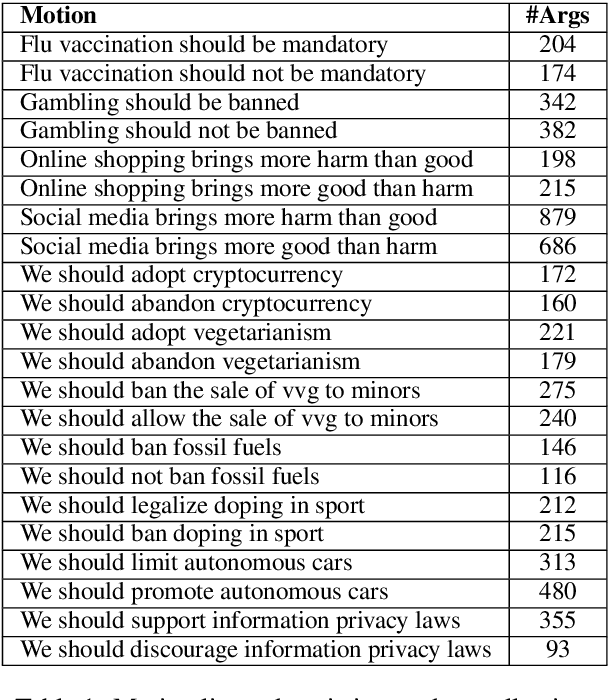
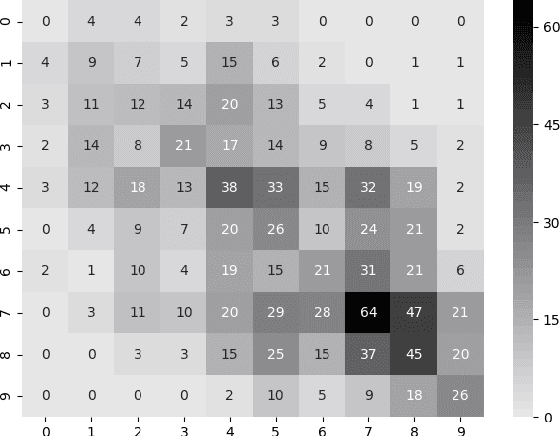
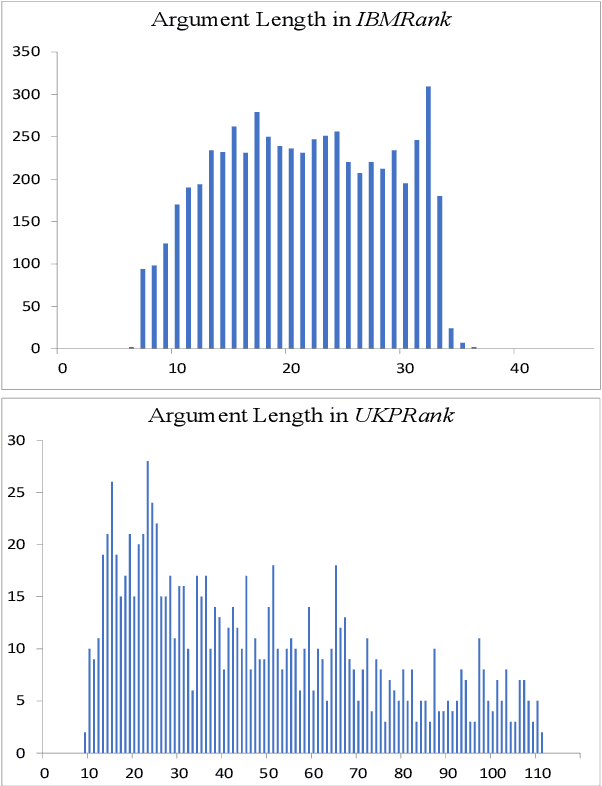
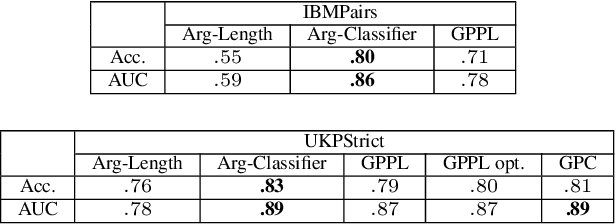
We explore the task of automatic assessment of argument quality. To that end, we actively collected 6.3k arguments, more than a factor of five compared to previously examined data. Each argument was explicitly and carefully annotated for its quality. In addition, 14k pairs of arguments were annotated independently, identifying the higher quality argument in each pair. In spite of the inherent subjective nature of the task, both annotation schemes led to surprisingly consistent results. We release the labeled datasets to the community. Furthermore, we suggest neural methods based on a recently released language model, for argument ranking as well as for argument-pair classification. In the former task, our results are comparable to state-of-the-art; in the latter task our results significantly outperform earlier methods.