 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDebatable Intelligence: Benchmarking LLM Judges via Debate Speech Evaluation
Jun 05, 2025We introduce Debate Speech Evaluation as a novel and challenging benchmark for assessing LLM judges. Evaluating debate speeches requires a deep understanding of the speech at multiple levels, including argument strength and relevance, the coherence and organization of the speech, the appropriateness of its style and tone, and so on. This task involves a unique set of cognitive abilities that have previously received limited attention in systematic LLM benchmarking. To explore such skills, we leverage a dataset of over 600 meticulously annotated debate speeches and present the first in-depth analysis of how state-of-the-art LLMs compare to human judges on this task. Our findings reveal a nuanced picture: while larger models can approximate individual human judgments in some respects, they differ substantially in their overall judgment behavior. We also investigate the ability of frontier LLMs to generate persuasive, opinionated speeches, showing that models may perform at a human level on this task.
Survey on Evaluation of LLM-based Agents
Mar 20, 2025The emergence of LLM-based agents represents a paradigm shift in AI, enabling autonomous systems to plan, reason, use tools, and maintain memory while interacting with dynamic environments. This paper provides the first comprehensive survey of evaluation methodologies for these increasingly capable agents. We systematically analyze evaluation benchmarks and frameworks across four critical dimensions: (1) fundamental agent capabilities, including planning, tool use, self-reflection, and memory; (2) application-specific benchmarks for web, software engineering, scientific, and conversational agents; (3) benchmarks for generalist agents; and (4) frameworks for evaluating agents. Our analysis reveals emerging trends, including a shift toward more realistic, challenging evaluations with continuously updated benchmarks. We also identify critical gaps that future research must address-particularly in assessing cost-efficiency, safety, and robustness, and in developing fine-grained, and scalable evaluation methods. This survey maps the rapidly evolving landscape of agent evaluation, reveals the emerging trends in the field, identifies current limitations, and proposes directions for future research.
JuStRank: Benchmarking LLM Judges for System Ranking
Dec 12, 2024



Given the rapid progress of generative AI, there is a pressing need to systematically compare and choose between the numerous models and configurations available. The scale and versatility of such evaluations make the use of LLM-based judges a compelling solution for this challenge. Crucially, this approach requires first to validate the quality of the LLM judge itself. Previous work has focused on instance-based assessment of LLM judges, where a judge is evaluated over a set of responses, or response pairs, while being agnostic to their source systems. We argue that this setting overlooks critical factors affecting system-level ranking, such as a judge's positive or negative bias towards certain systems. To address this gap, we conduct the first large-scale study of LLM judges as system rankers. System scores are generated by aggregating judgment scores over multiple system outputs, and the judge's quality is assessed by comparing the resulting system ranking to a human-based ranking. Beyond overall judge assessment, our analysis provides a fine-grained characterization of judge behavior, including their decisiveness and bias.
CHAMP: Efficient Annotation and Consolidation of Cluster Hierarchies
Nov 19, 2023Various NLP tasks require a complex hierarchical structure over nodes, where each node is a cluster of items. Examples include generating entailment graphs, hierarchical cross-document coreference resolution, annotating event and subevent relations, etc. To enable efficient annotation of such hierarchical structures, we release CHAMP, an open source tool allowing to incrementally construct both clusters and hierarchy simultaneously over any type of texts. This incremental approach significantly reduces annotation time compared to the common pairwise annotation approach and also guarantees maintaining transitivity at the cluster and hierarchy levels. Furthermore, CHAMP includes a consolidation mode, where an adjudicator can easily compare multiple cluster hierarchy annotations and resolve disagreements.
From Key Points to Key Point Hierarchy: Structured and Expressive Opinion Summarization
Jun 06, 2023Key Point Analysis (KPA) has been recently proposed for deriving fine-grained insights from collections of textual comments. KPA extracts the main points in the data as a list of concise sentences or phrases, termed key points, and quantifies their prevalence. While key points are more expressive than word clouds and key phrases, making sense of a long, flat list of key points, which often express related ideas in varying levels of granularity, may still be challenging. To address this limitation of KPA, we introduce the task of organizing a given set of key points into a hierarchy, according to their specificity. Such hierarchies may be viewed as a novel type of Textual Entailment Graph. We develop ThinkP, a high quality benchmark dataset of key point hierarchies for business and product reviews, obtained by consolidating multiple annotations. We compare different methods for predicting pairwise relations between key points, and for inferring a hierarchy from these pairwise predictions. In particular, for the task of computing pairwise key point relations, we achieve significant gains over existing strong baselines by applying directional distributional similarity methods to a novel distributional representation of key points, and further boost performance via weak supervision.
Project Debater APIs: Decomposing the AI Grand Challenge
Oct 03, 2021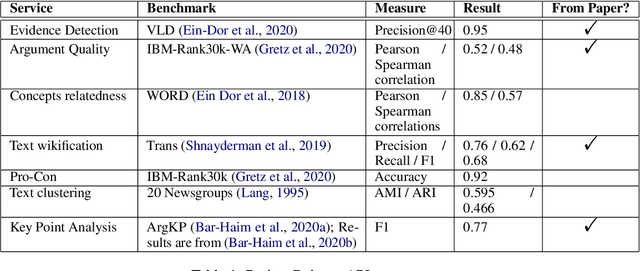

Project Debater was revealed in 2019 as the first AI system that can debate human experts on complex topics. Engaging in a live debate requires a diverse set of skills, and Project Debater has been developed accordingly as a collection of components, each designed to perform a specific subtask. Project Debater APIs provide access to many of these capabilities, as well as to more recently developed ones. This diverse set of web services, publicly available for academic use, includes core NLP services, argument mining and analysis capabilities, and higher-level services for content summarization. We describe these APIs and their performance, and demonstrate how they can be used for building practical solutions. In particular, we will focus on Key Point Analysis, a novel technology that identifies the main points and their prevalence in a collection of texts such as survey responses and user reviews.
Every Bite Is an Experience: Key Point Analysis of Business Reviews
Jun 12, 2021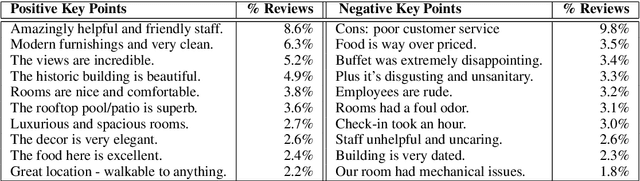
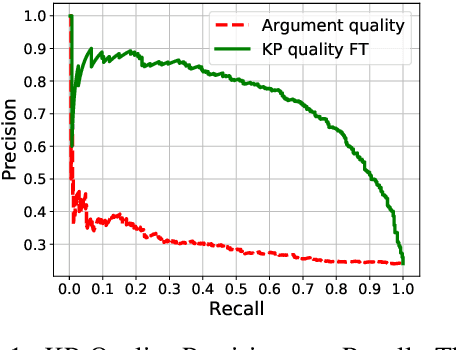

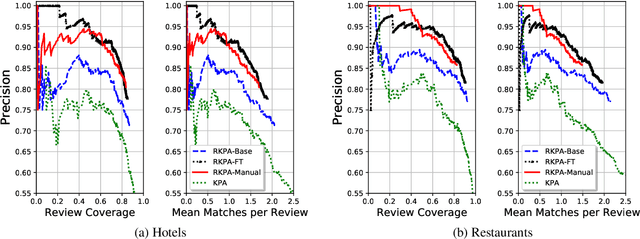
Previous work on review summarization focused on measuring the sentiment toward the main aspects of the reviewed product or business, or on creating a textual summary. These approaches provide only a partial view of the data: aspect-based sentiment summaries lack sufficient explanation or justification for the aspect rating, while textual summaries do not quantify the significance of each element, and are not well-suited for representing conflicting views. Recently, Key Point Analysis (KPA) has been proposed as a summarization framework that provides both textual and quantitative summary of the main points in the data. We adapt KPA to review data by introducing Collective Key Point Mining for better key point extraction; integrating sentiment analysis into KPA; identifying good key point candidates for review summaries; and leveraging the massive amount of available reviews and their metadata. We show empirically that these novel extensions of KPA substantially improve its performance. We demonstrate that promising results can be achieved without any domain-specific annotation, while human supervision can lead to further improvement.
Quantitative Argument Summarization and Beyond: Cross-Domain Key Point Analysis
Oct 11, 2020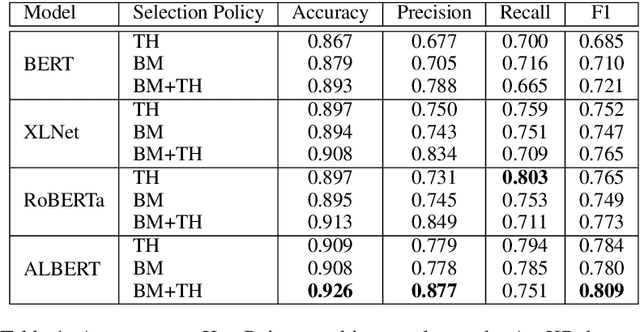

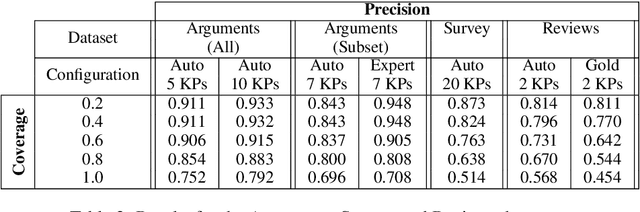
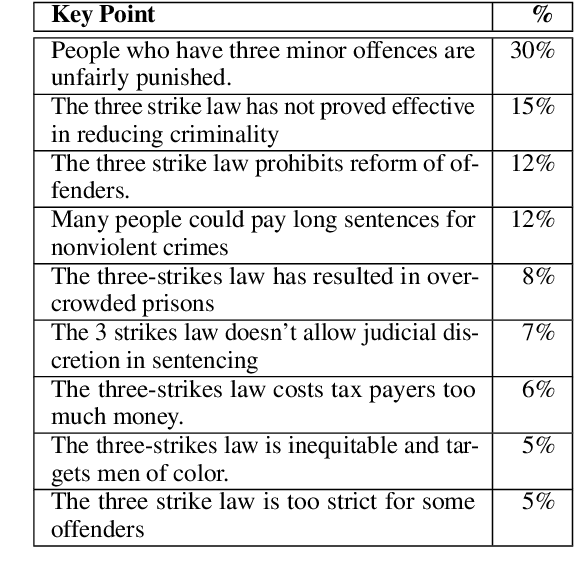
When summarizing a collection of views, arguments or opinions on some topic, it is often desirable not only to extract the most salient points, but also to quantify their prevalence. Work on multi-document summarization has traditionally focused on creating textual summaries, which lack this quantitative aspect. Recent work has proposed to summarize arguments by mapping them to a small set of expert-generated key points, where the salience of each key point corresponds to the number of its matching arguments. The current work advances key point analysis in two important respects: first, we develop a method for automatic extraction of key points, which enables fully automatic analysis, and is shown to achieve performance comparable to a human expert. Second, we demonstrate that the applicability of key point analysis goes well beyond argumentation data. Using models trained on publicly available argumentation datasets, we achieve promising results in two additional domains: municipal surveys and user reviews. An additional contribution is an in-depth evaluation of argument-to-key point matching models, where we substantially outperform previous results.
From Arguments to Key Points: Towards Automatic Argument Summarization
May 04, 2020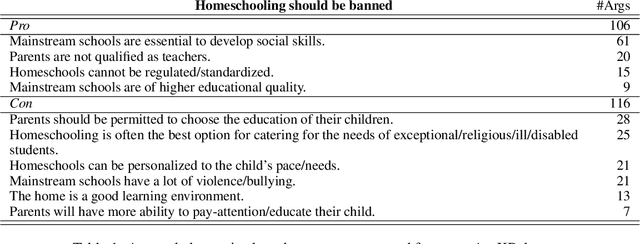
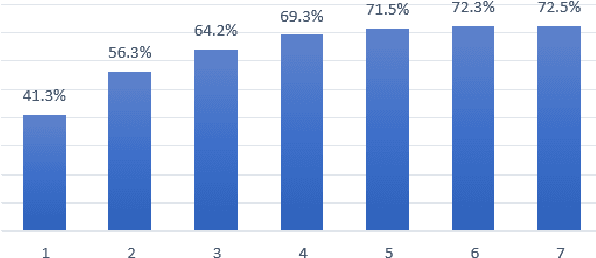
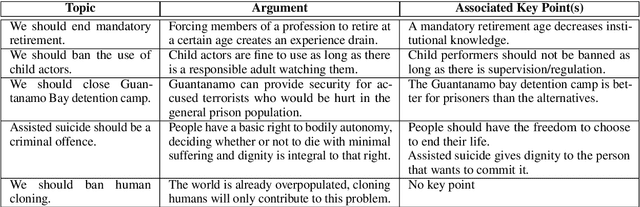
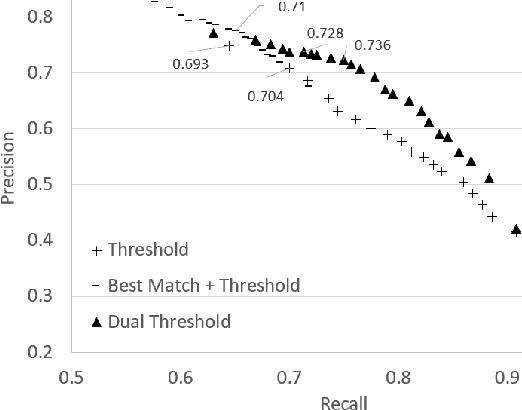
Generating a concise summary from a large collection of arguments on a given topic is an intriguing yet understudied problem. We propose to represent such summaries as a small set of talking points, termed "key points", each scored according to its salience. We show, by analyzing a large dataset of crowd-contributed arguments, that a small number of key points per topic is typically sufficient for covering the vast majority of the arguments. Furthermore, we found that a domain expert can often predict these key points in advance. We study the task of argument-to-key point mapping, and introduce a novel large-scale dataset for this task. We report empirical results for an extensive set of experiments with this dataset, showing promising performance.