 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnitxt: Flexible, Shareable and Reusable Data Preparation and Evaluation for Generative AI
Jan 25, 2024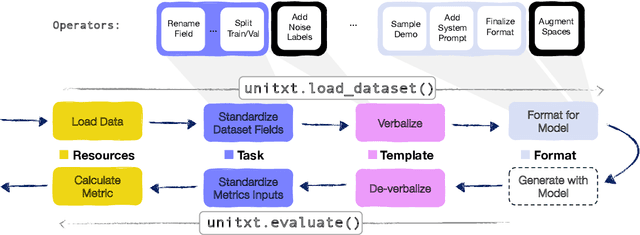

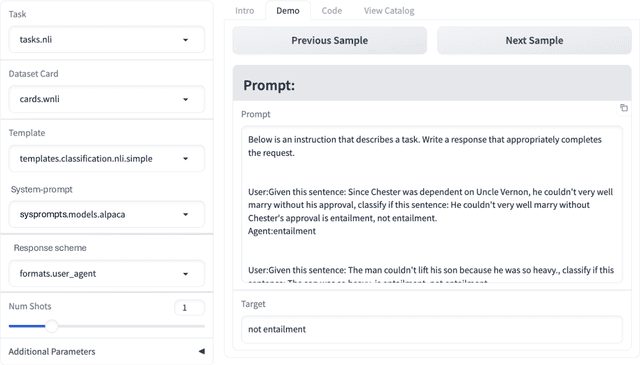

In the dynamic landscape of generative NLP, traditional text processing pipelines limit research flexibility and reproducibility, as they are tailored to specific dataset, task, and model combinations. The escalating complexity, involving system prompts, model-specific formats, instructions, and more, calls for a shift to a structured, modular, and customizable solution. Addressing this need, we present Unitxt, an innovative library for customizable textual data preparation and evaluation tailored to generative language models. Unitxt natively integrates with common libraries like HuggingFace and LM-eval-harness and deconstructs processing flows into modular components, enabling easy customization and sharing between practitioners. These components encompass model-specific formats, task prompts, and many other comprehensive dataset processing definitions. The Unitxt-Catalog centralizes these components, fostering collaboration and exploration in modern textual data workflows. Beyond being a tool, Unitxt is a community-driven platform, empowering users to build, share, and advance their pipelines collaboratively. Join the Unitxt community at https://github.com/IBM/unitxt!
Knowledge is a Region in Weight Space for Fine-tuned Language Models
Feb 12, 2023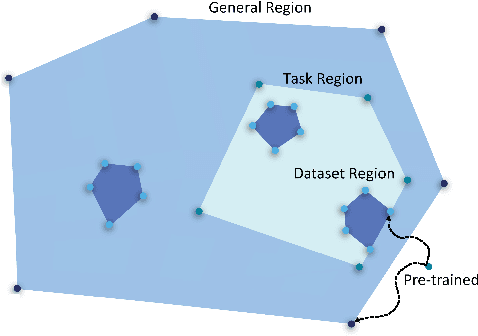

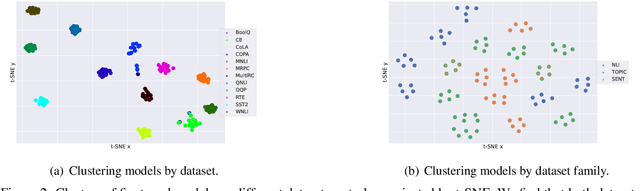

Research on neural networks has largely focused on understanding a single model trained on a single dataset. However, relatively little is known about the relationships between different models, especially those trained or tested on different datasets. We address this by studying how the weight space and underlying loss landscape of different models are interconnected. Specifically, we demonstrate that fine-tuned models that were optimized for high performance, reside in well-defined regions in weight space, and vice versa -- that any model that resides anywhere in those regions also has high performance. Specifically, we show that language models that have been fine-tuned on the same dataset form a tight cluster in the weight space and that models fine-tuned on different datasets from the same underlying task form a looser cluster. Moreover, traversing around the region between the models reaches new models that perform comparably or even better than models found via fine-tuning, even on tasks that the original models were not fine-tuned on. Our findings provide insight into the relationships between models, demonstrating that a model positioned between two similar models can acquire the knowledge of both. We leverage this finding and design a method to pick a better model for efficient fine-tuning. Specifically, we show that starting from the center of the region is as good or better than the pre-trained model in 11 of 12 datasets and improves accuracy by 3.06 on average.
ColD Fusion: Collaborative Descent for Distributed Multitask Finetuning
Dec 02, 2022Pretraining has been shown to scale well with compute, data size and data diversity. Multitask learning trains on a mixture of supervised datasets and produces improved performance compared to self-supervised pretraining. Until now, massively multitask learning required simultaneous access to all datasets in the mixture and heavy compute resources that are only available to well-resourced teams. In this paper, we propose ColD Fusion, a method that provides the benefits of multitask learning but leverages distributed computation and requires limited communication and no sharing of data. Consequentially, ColD Fusion can create a synergistic loop, where finetuned models can be recycled to continually improve the pretrained model they are based on. We show that ColD Fusion yields comparable benefits to multitask pretraining by producing a model that (a) attains strong performance on all of the datasets it was multitask trained on and (b) is a better starting point for finetuning on unseen datasets. We find ColD Fusion outperforms RoBERTa and even previous multitask models. Specifically, when training and testing on 35 diverse datasets, ColD Fusion-based model outperforms RoBERTa by 2.45 points in average without any changes to the architecture.
Where to start? Analyzing the potential value of intermediate models
Nov 10, 2022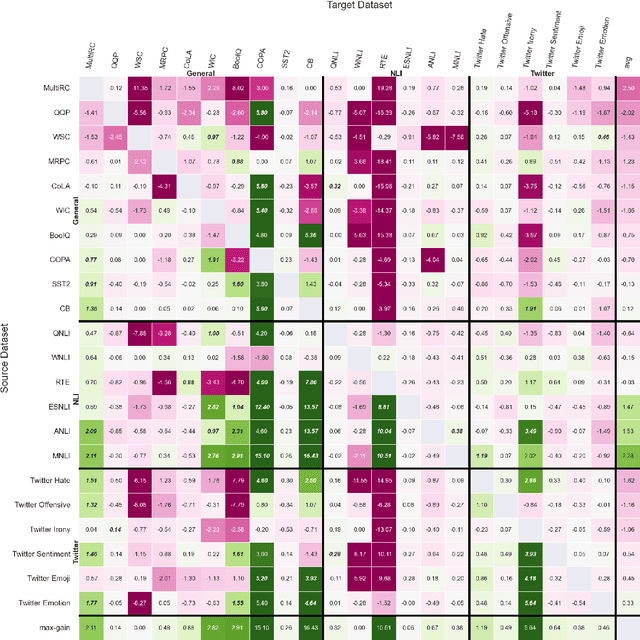



Previous studies observed that finetuned models may be better base models than the vanilla pretrained model. Such a model, finetuned on some source dataset, may provide a better starting point for a new finetuning process on a desired target dataset. Here, we perform a systematic analysis of this intertraining scheme, over a wide range of English classification tasks. Surprisingly, our analysis suggests that the potential intertraining gain can be analyzed independently for the target dataset under consideration, and for a base model being considered as a starting point. This is in contrast to current perception that the alignment between the target dataset and the source dataset used to generate the base model is a major factor in determining intertraining success. We analyze different aspects that contribute to each. Furthermore, we leverage our analysis to propose a practical and efficient approach to determine if and how to select a base model in real-world settings. Last, we release an updating ranking of best models in the HuggingFace hub per architecture https://ibm.github.io/model-recycling/.
Fusing finetuned models for better pretraining
Apr 06, 2022
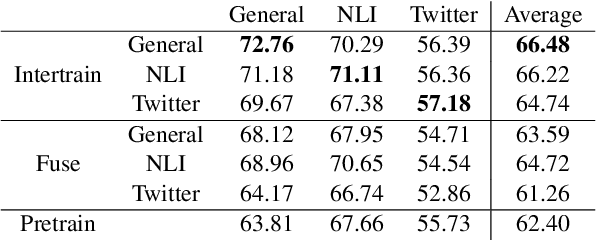


Pretrained models are the standard starting point for training. This approach consistently outperforms the use of a random initialization. However, pretraining is a costly endeavour that few can undertake. In this paper, we create better base models at hardly any cost, by fusing multiple existing fine tuned models into one. Specifically, we fuse by averaging the weights of these models. We show that the fused model results surpass the pretrained model ones. We also show that fusing is often better than intertraining. We find that fusing is less dependent on the target task. Furthermore, weight decay nullifies intertraining effects but not those of fusing.
Project Debater APIs: Decomposing the AI Grand Challenge
Oct 03, 2021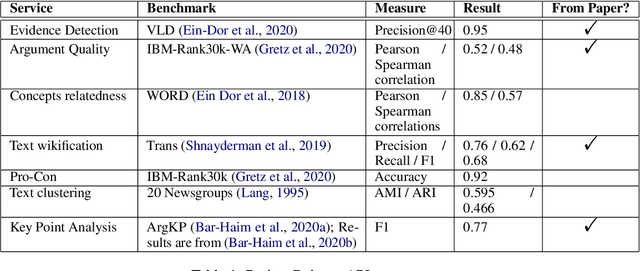
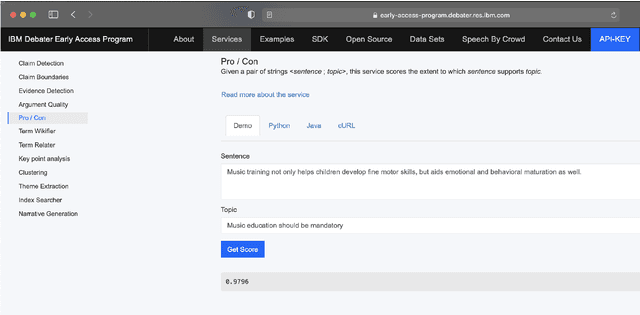

Project Debater was revealed in 2019 as the first AI system that can debate human experts on complex topics. Engaging in a live debate requires a diverse set of skills, and Project Debater has been developed accordingly as a collection of components, each designed to perform a specific subtask. Project Debater APIs provide access to many of these capabilities, as well as to more recently developed ones. This diverse set of web services, publicly available for academic use, includes core NLP services, argument mining and analysis capabilities, and higher-level services for content summarization. We describe these APIs and their performance, and demonstrate how they can be used for building practical solutions. In particular, we will focus on Key Point Analysis, a novel technology that identifies the main points and their prevalence in a collection of texts such as survey responses and user reviews.
Automatic Argument Quality Assessment -- New Datasets and Methods
Sep 03, 2019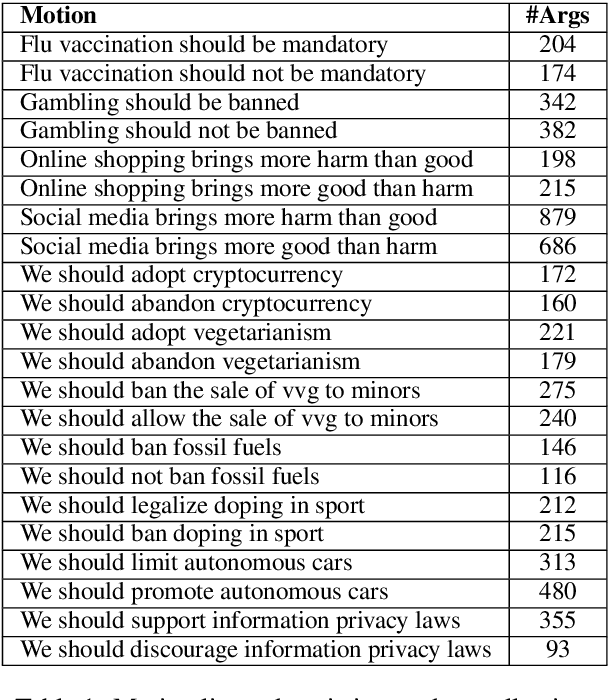
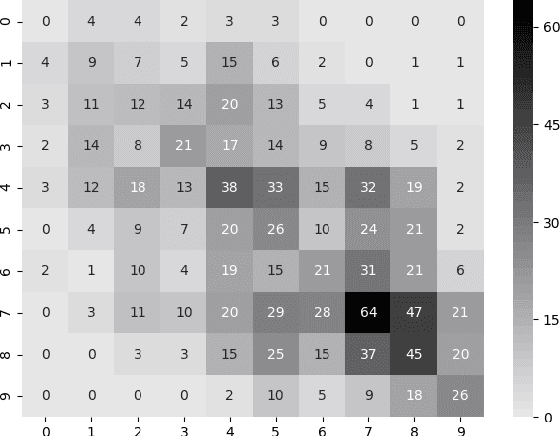
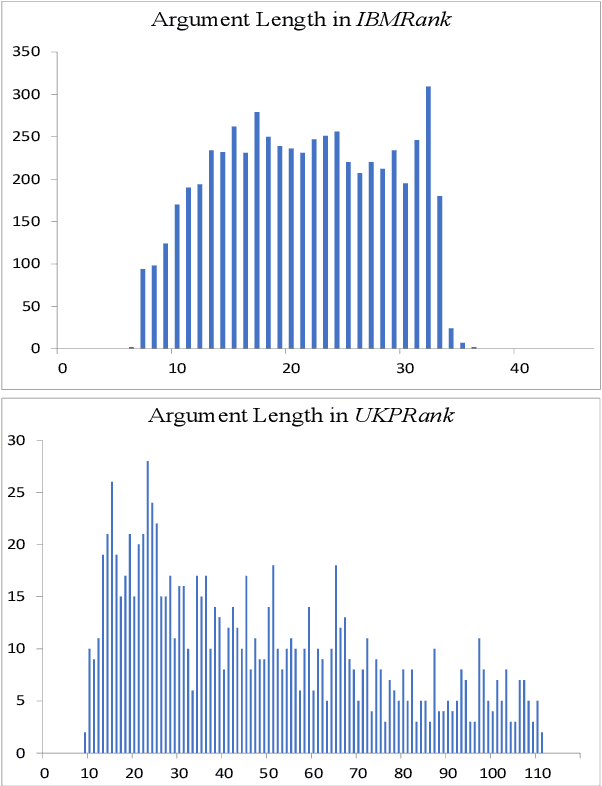
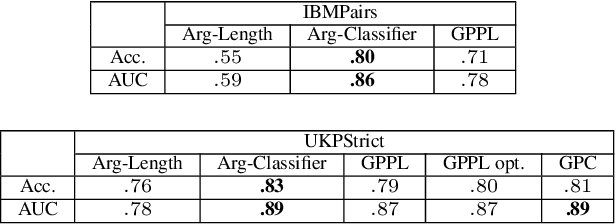
We explore the task of automatic assessment of argument quality. To that end, we actively collected 6.3k arguments, more than a factor of five compared to previously examined data. Each argument was explicitly and carefully annotated for its quality. In addition, 14k pairs of arguments were annotated independently, identifying the higher quality argument in each pair. In spite of the inherent subjective nature of the task, both annotation schemes led to surprisingly consistent results. We release the labeled datasets to the community. Furthermore, we suggest neural methods based on a recently released language model, for argument ranking as well as for argument-pair classification. In the former task, our results are comparable to state-of-the-art; in the latter task our results significantly outperform earlier methods.
A Recorded Debating Dataset
Mar 27, 2018
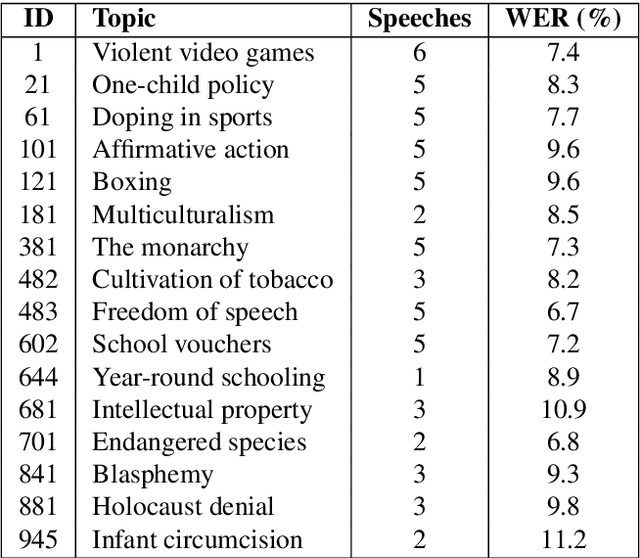
This paper describes an English audio and textual dataset of debating speeches, a unique resource for the growing research field of computational argumentation and debating technologies. We detail the process of speech recording by professional debaters, the transcription of the speeches with an Automatic Speech Recognition (ASR) system, their consequent automatic processing to produce a text that is more "NLP-friendly", and in parallel -- the manual transcription of the speeches in order to produce gold-standard "reference" transcripts. We release 60 speeches on various controversial topics, each in five formats corresponding to the different stages in the production of the data. The intention is to allow utilizing this resource for multiple research purposes, be it the addition of in-domain training data for a debate-specific ASR system, or applying argumentation mining on either noisy or clean debate transcripts. We intend to make further releases of this data in the future.
What did you Mention? A Large Scale Mention Detection Benchmark for Spoken and Written Text
Jan 25, 2018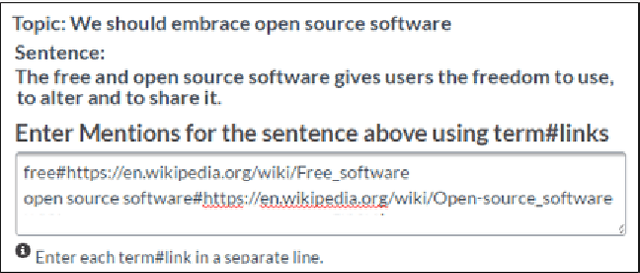
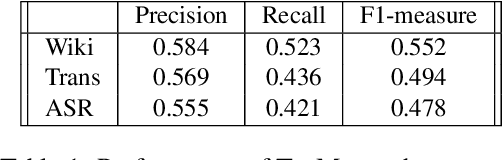
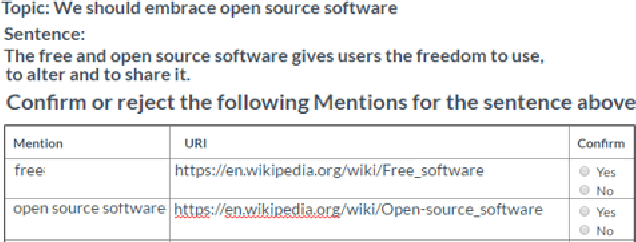
We describe a large, high-quality benchmark for the evaluation of Mention Detection tools. The benchmark contains annotations of both named entities as well as other types of entities, annotated on different types of text, ranging from clean text taken from Wikipedia, to noisy spoken data. The benchmark was built through a highly controlled crowd sourcing process to ensure its quality. We describe the benchmark, the process and the guidelines that were used to build it. We then demonstrate the results of a state-of-the-art system running on that benchmark.