 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWill it Merge? On The Causes of Model Mergeability
Jan 10, 2026Model merging has emerged as a promising technique for combining multiple fine-tuned models into a single multitask model without retraining. However, the factors that determine whether merging will succeed or fail remain poorly understood. In this work, we investigate why specific models are merged better than others. To do so, we propose a concrete, measurable definition of mergeability. We investigate several potential causes for high or low mergeability, highlighting the base model knowledge as a dominant factor: Models fine-tuned on instances that the base model knows better are more mergeable than models fine-tuned on instances that the base model struggles with. Based on our mergeability definition, we explore a simple weighted merging technique that better preserves weak knowledge in the base model.
Fine-Grained Detection of Context-Grounded Hallucinations Using LLMs
Sep 26, 2025Context-grounded hallucinations are cases where model outputs contain information not verifiable against the source text. We study the applicability of LLMs for localizing such hallucinations, as a more practical alternative to existing complex evaluation pipelines. In the absence of established benchmarks for meta-evaluation of hallucinations localization, we construct one tailored to LLMs, involving a challenging human annotation of over 1,000 examples. We complement the benchmark with an LLM-based evaluation protocol, verifying its quality in a human evaluation. Since existing representations of hallucinations limit the types of errors that can be expressed, we propose a new representation based on free-form textual descriptions, capturing the full range of possible errors. We conduct a comprehensive study, evaluating four large-scale LLMs, which highlights the benchmark's difficulty, as the best model achieves an F1 score of only 0.67. Through careful analysis, we offer insights into optimal prompting strategies for the task and identify the main factors that make it challenging for LLMs: (1) a tendency to incorrectly flag missing details as inconsistent, despite being instructed to check only facts in the output; and (2) difficulty with outputs containing factually correct information absent from the source - and thus not verifiable - due to alignment with the model's parametric knowledge.
Genie: Achieving Human Parity in Content-Grounded Datasets Generation
Jan 25, 2024The lack of high-quality data for content-grounded generation tasks has been identified as a major obstacle to advancing these tasks. To address this gap, we propose Genie, a novel method for automatically generating high-quality content-grounded data. It consists of three stages: (a) Content Preparation, (b) Generation: creating task-specific examples from the content (e.g., question-answer pairs or summaries). (c) Filtering mechanism aiming to ensure the quality and faithfulness of the generated data. We showcase this methodology by generating three large-scale synthetic data, making wishes, for Long-Form Question-Answering (LFQA), summarization, and information extraction. In a human evaluation, our generated data was found to be natural and of high quality. Furthermore, we compare models trained on our data with models trained on human-written data -- ELI5 and ASQA for LFQA and CNN-DailyMail for Summarization. We show that our models are on par with or outperforming models trained on human-generated data and consistently outperforming them in faithfulness. Finally, we applied our method to create LFQA data within the medical domain and compared a model trained on it with models trained on other domains.
QAID: Question Answering Inspired Few-shot Intent Detection
Mar 21, 2023Intent detection with semantically similar fine-grained intents is a challenging task. To address it, we reformulate intent detection as a question-answering retrieval task by treating utterances and intent names as questions and answers. To that end, we utilize a question-answering retrieval architecture and adopt a two stages training schema with batch contrastive loss. In the pre-training stage, we improve query representations through self-supervised training. Then, in the fine-tuning stage, we increase contextualized token-level similarity scores between queries and answers from the same intent. Our results on three few-shot intent detection benchmarks achieve state-of-the-art performance.
Conversational Search with Mixed-Initiative -- Asking Good Clarification Questions backed-up by Passage Retrieval
Dec 14, 2021
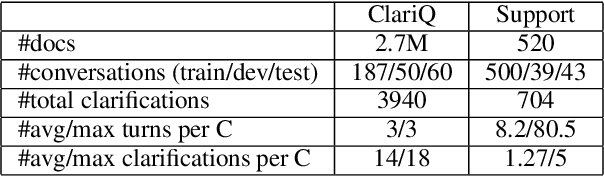
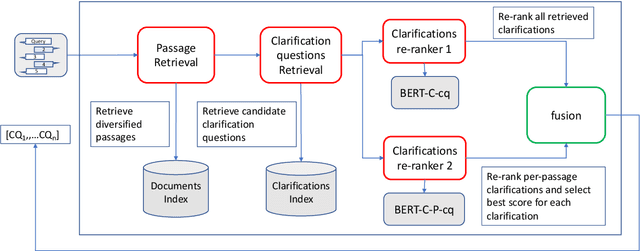
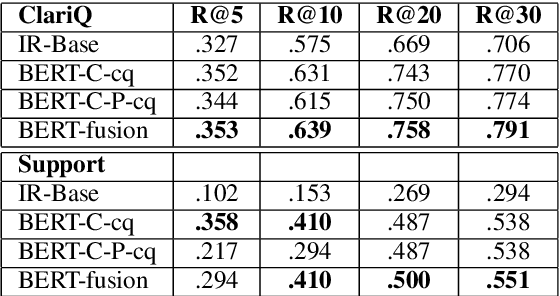
We deal with a scenario of conversational search with mixed-initiative: namely user-asks system-answers, as well as system-asks (clarification questions) and user-answers. We focus on the task of selecting the next clarification question, given conversation context. Our method leverages passage retrieval that is used both for an initial selection of relevant candidate clarification questions, as well as for fine-tuning two deep-learning models for re-ranking these candidates. We evaluated our method on two different use-cases. The first is an open domain conversational search in a large web collection. The second is a task-oriented customer-support setup. We show that our method performs well on both use-cases.
Conversational Document Prediction to Assist Customer Care Agents
Oct 05, 2020
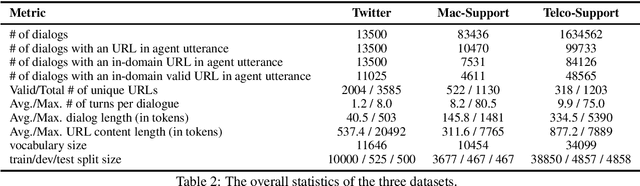

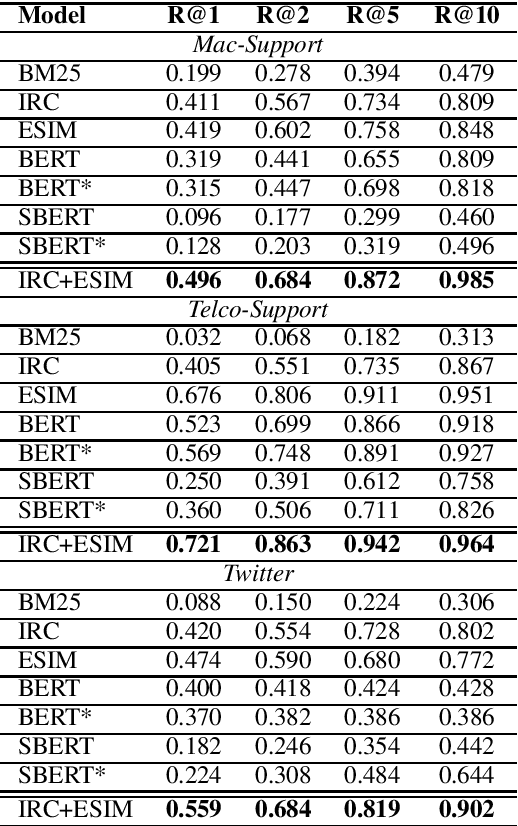
A frequent pattern in customer care conversations is the agents responding with appropriate webpage URLs that address users' needs. We study the task of predicting the documents that customer care agents can use to facilitate users' needs. We also introduce a new public dataset which supports the aforementioned problem. Using this dataset and two others, we investigate state-of-the art deep learning (DL) and information retrieval (IR) models for the task. Additionally, we analyze the practicality of such systems in terms of inference time complexity. Our show that an hybrid IR+DL approach provides the best of both worlds.
A Summarization System for Scientific Documents
Aug 29, 2019

We present a novel system providing summaries for Computer Science publications. Through a qualitative user study, we identified the most valuable scenarios for discovery, exploration and understanding of scientific documents. Based on these findings, we built a system that retrieves and summarizes scientific documents for a given information need, either in form of a free-text query or by choosing categorized values such as scientific tasks, datasets and more. Our system ingested 270,000 papers, and its summarization module aims to generate concise yet detailed summaries. We validated our approach with human experts.
Fast End-to-End Wikification
Aug 19, 2019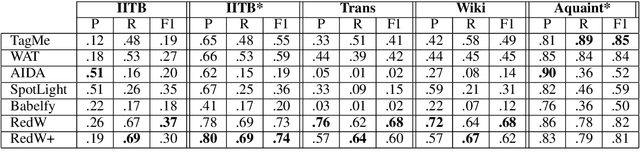
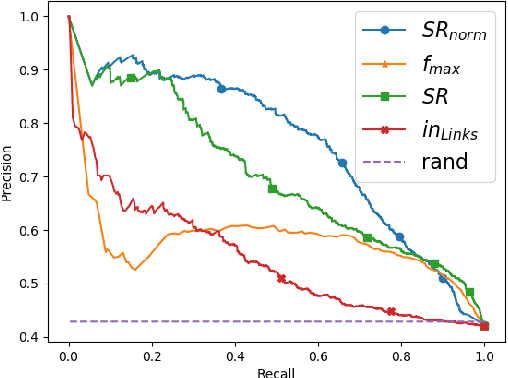

Wikification of large corpora is beneficial for various NLP applications. Existing methods focus on quality performance rather than run-time, and are therefore non-feasible for large data. Here, we introduce RedW, a run-time oriented Wikification solution, based on Wikipedia redirects, that can Wikify massive corpora with competitive performance. We further propose an efficient method for estimating RedW confidence, opening the door for applying more demanding methods only on top of RedW lower-confidence results. Our experimental results support the validity of the proposed approach.
A Study of BERT for Non-Factoid Question-Answering under Passage Length Constraints
Aug 19, 2019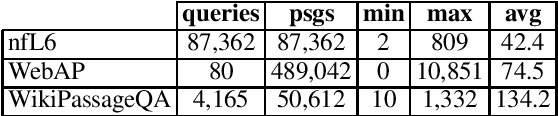
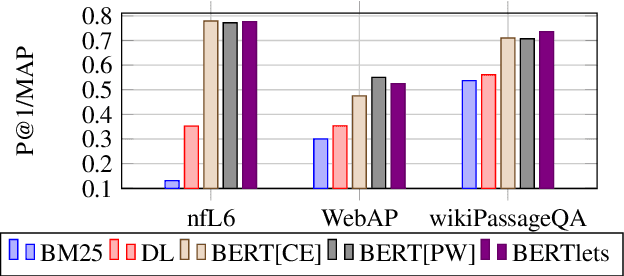
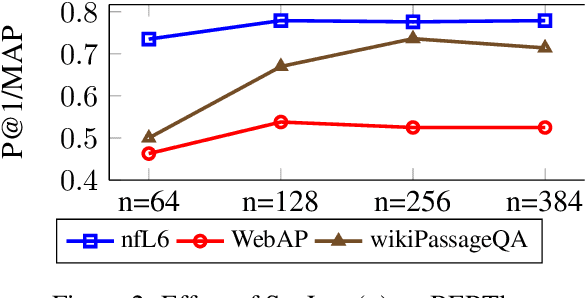
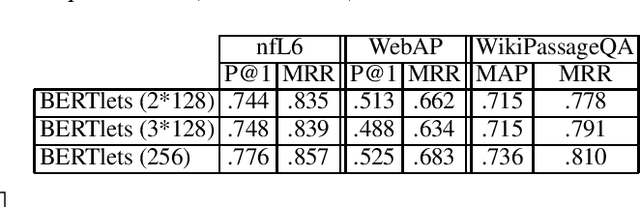
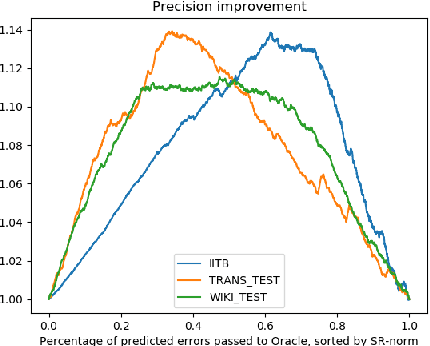
We study the use of BERT for non-factoid question-answering, focusing on the passage re-ranking task under varying passage lengths. To this end, we explore the fine-tuning of BERT in different learning-to-rank setups, comprising both point-wise and pair-wise methods, resulting in substantial improvements over the state-of-the-art. We then analyze the effectiveness of BERT for different passage lengths and suggest how to cope with large passages.
What did you Mention? A Large Scale Mention Detection Benchmark for Spoken and Written Text
Jan 25, 2018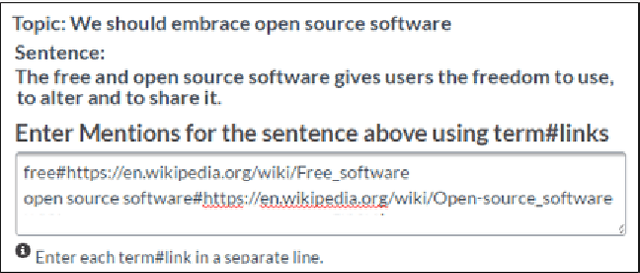
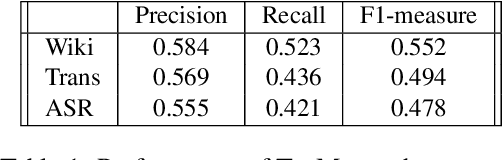
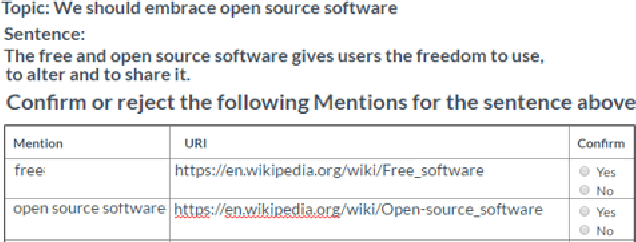
We describe a large, high-quality benchmark for the evaluation of Mention Detection tools. The benchmark contains annotations of both named entities as well as other types of entities, annotated on different types of text, ranging from clean text taken from Wikipedia, to noisy spoken data. The benchmark was built through a highly controlled crowd sourcing process to ensure its quality. We describe the benchmark, the process and the guidelines that were used to build it. We then demonstrate the results of a state-of-the-art system running on that benchmark.