 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEffective Red-Teaming of Policy-Adherent Agents
Jun 11, 2025Task-oriented LLM-based agents are increasingly used in domains with strict policies, such as refund eligibility or cancellation rules. The challenge lies in ensuring that the agent consistently adheres to these rules and policies, appropriately refusing any request that would violate them, while still maintaining a helpful and natural interaction. This calls for the development of tailored design and evaluation methodologies to ensure agent resilience against malicious user behavior. We propose a novel threat model that focuses on adversarial users aiming to exploit policy-adherent agents for personal benefit. To address this, we present CRAFT, a multi-agent red-teaming system that leverages policy-aware persuasive strategies to undermine a policy-adherent agent in a customer-service scenario, outperforming conventional jailbreak methods such as DAN prompts, emotional manipulation, and coercive. Building upon the existing tau-bench benchmark, we introduce tau-break, a complementary benchmark designed to rigorously assess the agent's robustness against manipulative user behavior. Finally, we evaluate several straightforward yet effective defense strategies. While these measures provide some protection, they fall short, highlighting the need for stronger, research-driven safeguards to protect policy-adherent agents from adversarial attacks
SpeCrawler: Generating OpenAPI Specifications from API Documentation Using Large Language Models
Feb 18, 2024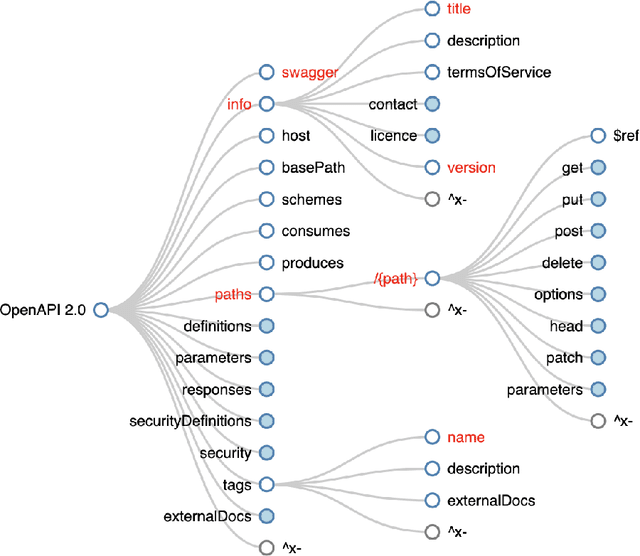

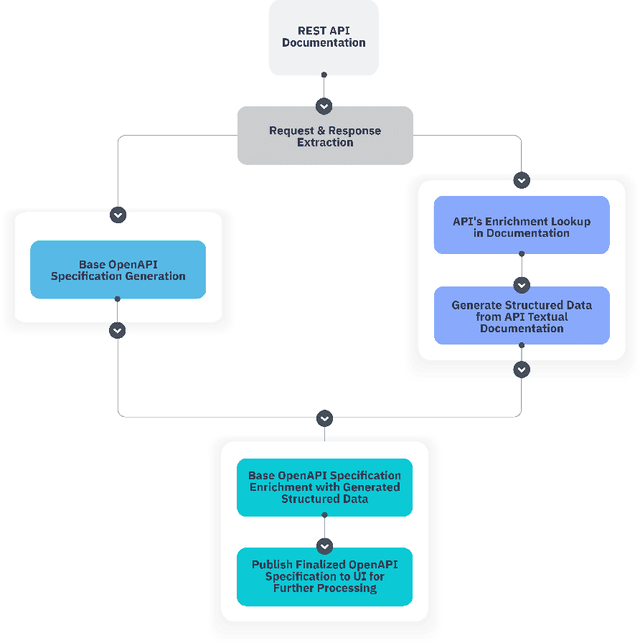
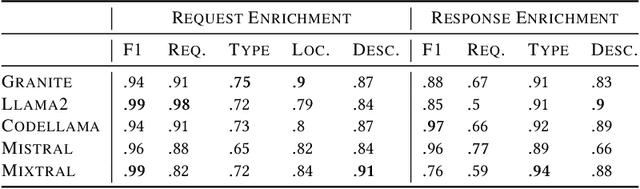
In the digital era, the widespread use of APIs is evident. However, scalable utilization of APIs poses a challenge due to structure divergence observed in online API documentation. This underscores the need for automatic tools to facilitate API consumption. A viable approach involves the conversion of documentation into an API Specification format. While previous attempts have been made using rule-based methods, these approaches encountered difficulties in generalizing across diverse documentation. In this paper we introduce SpeCrawler, a comprehensive system that utilizes large language models (LLMs) to generate OpenAPI Specifications from diverse API documentation through a carefully crafted pipeline. By creating a standardized format for numerous APIs, SpeCrawler aids in streamlining integration processes within API orchestrating systems and facilitating the incorporation of tools into LLMs. The paper explores SpeCrawler's methodology, supported by empirical evidence and case studies, demonstrating its efficacy through LLM capabilities.
NERetrieve: Dataset for Next Generation Named Entity Recognition and Retrieval
Oct 22, 2023Recognizing entities in texts is a central need in many information-seeking scenarios, and indeed, Named Entity Recognition (NER) is arguably one of the most successful examples of a widely adopted NLP task and corresponding NLP technology. Recent advances in large language models (LLMs) appear to provide effective solutions (also) for NER tasks that were traditionally handled with dedicated models, often matching or surpassing the abilities of the dedicated models. Should NER be considered a solved problem? We argue to the contrary: the capabilities provided by LLMs are not the end of NER research, but rather an exciting beginning. They allow taking NER to the next level, tackling increasingly more useful, and increasingly more challenging, variants. We present three variants of the NER task, together with a dataset to support them. The first is a move towards more fine-grained -- and intersectional -- entity types. The second is a move towards zero-shot recognition and extraction of these fine-grained types based on entity-type labels. The third, and most challenging, is the move from the recognition setup to a novel retrieval setup, where the query is a zero-shot entity type, and the expected result is all the sentences from a large, pre-indexed corpus that contain entities of these types, and their corresponding spans. We show that all of these are far from being solved. We provide a large, silver-annotated corpus of 4 million paragraphs covering 500 entity types, to facilitate research towards all of these three goals.
Reliable and Interpretable Drift Detection in Streams of Short Texts
May 28, 2023Data drift is the change in model input data that is one of the key factors leading to machine learning models performance degradation over time. Monitoring drift helps detecting these issues and preventing their harmful consequences. Meaningful drift interpretation is a fundamental step towards effective re-training of the model. In this study we propose an end-to-end framework for reliable model-agnostic change-point detection and interpretation in large task-oriented dialog systems, proven effective in multiple customer deployments. We evaluate our approach and demonstrate its benefits with a novel variant of intent classification training dataset, simulating customer requests to a dialog system. We make the data publicly available.
QAID: Question Answering Inspired Few-shot Intent Detection
Mar 21, 2023Intent detection with semantically similar fine-grained intents is a challenging task. To address it, we reformulate intent detection as a question-answering retrieval task by treating utterances and intent names as questions and answers. To that end, we utilize a question-answering retrieval architecture and adopt a two stages training schema with batch contrastive loss. In the pre-training stage, we improve query representations through self-supervised training. Then, in the fine-tuning stage, we increase contextualized token-level similarity scores between queries and answers from the same intent. Our results on three few-shot intent detection benchmarks achieve state-of-the-art performance.
Gaining Insights into Unrecognized User Utterances in Task-Oriented Dialog Systems
Apr 11, 2022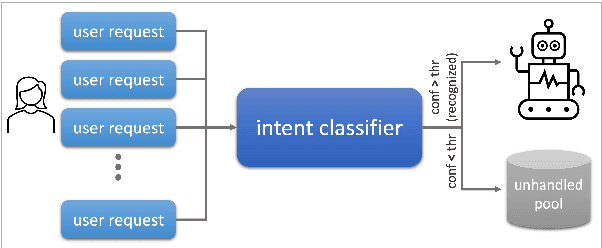

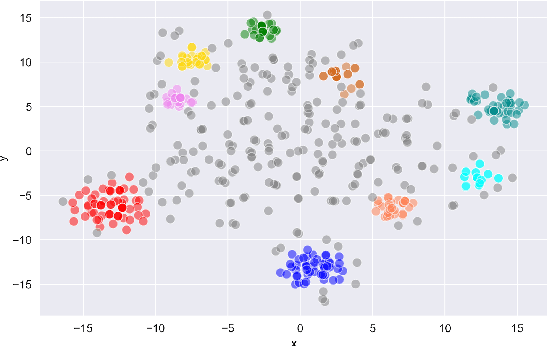
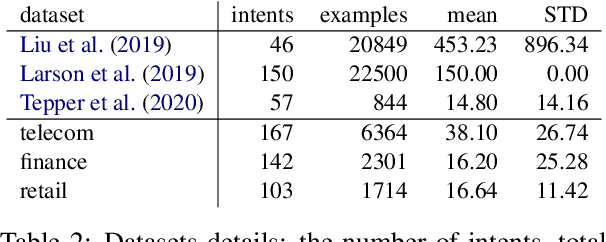
The rapidly growing market demand for dialogue agents capable of goal-oriented behavior has caused many tech-industry leaders to invest considerable efforts into task-oriented dialog systems. The performance and success of these systems is highly dependent on the accuracy of their intent identification -- the process of deducing the goal or meaning of the user's request and mapping it to one of the known intents for further processing. Gaining insights into unrecognized utterances -- user requests the systems fails to attribute to a known intent -- is therefore a key process in continuous improvement of goal-oriented dialog systems. We present an end-to-end pipeline for processing unrecognized user utterances, including a specifically-tailored clustering algorithm, a novel approach to cluster representative extraction, and cluster naming. We evaluated the proposed clustering algorithm and compared its performance to out-of-the-box SOTA solutions, demonstrating its benefits in the analysis of unrecognized user requests.