 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePACIFIC: a framework for generating benchmarks to check Precise Automatically Checked Instruction Following In Code
Dec 22, 2025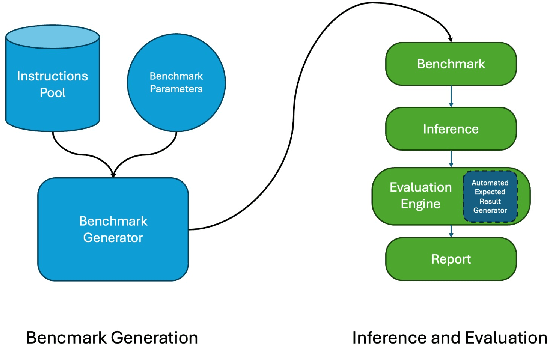
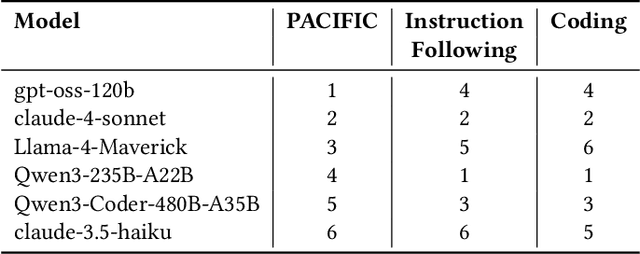
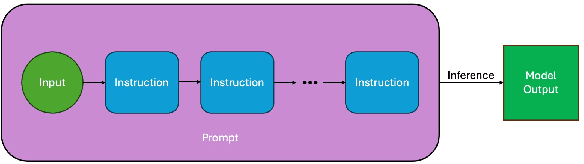
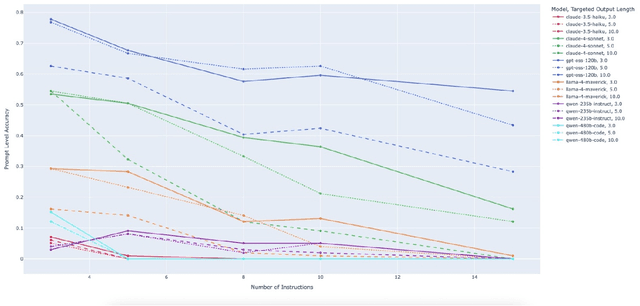
Large Language Model (LLM)-based code assistants have emerged as a powerful application of generative AI, demonstrating impressive capabilities in code generation and comprehension. A key requirement for these systems is their ability to accurately follow user instructions. We present Precise Automatically Checked Instruction Following In Code (PACIFIC), a novel framework designed to automatically generate benchmarks that rigorously assess sequential instruction-following and code dry-running capabilities in LLMs, while allowing control over benchmark difficulty. PACIFIC produces benchmark variants with clearly defined expected outputs, enabling straightforward and reliable evaluation through simple output comparisons. In contrast to existing approaches that often rely on tool usage or agentic behavior, our work isolates and evaluates the LLM's intrinsic ability to reason through code behavior step-by-step without execution (dry running) and to follow instructions. Furthermore, our framework mitigates training data contamination by facilitating effortless generation of novel benchmark variations. We validate our framework by generating a suite of benchmarks spanning a range of difficulty levels and evaluating multiple state-of-the-art LLMs. Our results demonstrate that PACIFIC can produce increasingly challenging benchmarks that effectively differentiate instruction-following and dry running capabilities, even among advanced models. Overall, our framework offers a scalable, contamination-resilient methodology for assessing core competencies of LLMs in code-related tasks.
Statistical multi-metric evaluation and visualization of LLM system predictive performance
Jan 30, 2025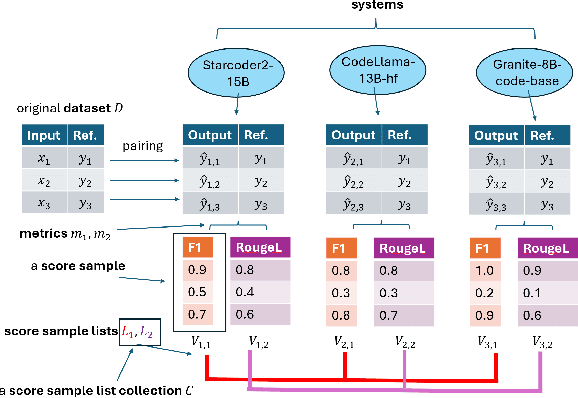

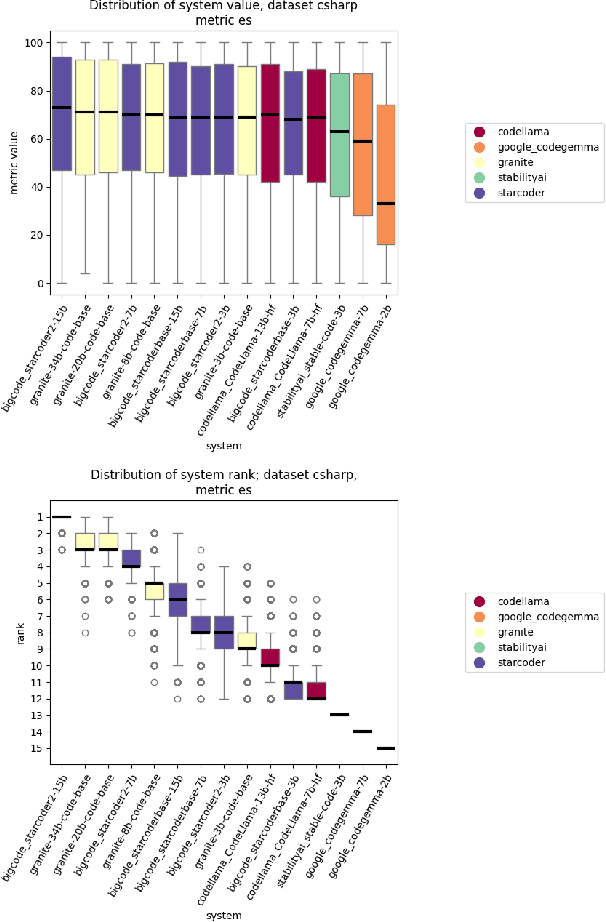
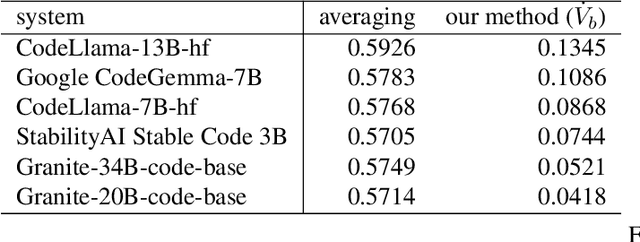
The evaluation of generative or discriminative large language model (LLM)-based systems is often a complex multi-dimensional problem. Typically, a set of system configuration alternatives are evaluated on one or more benchmark datasets, each with one or more evaluation metrics, which may differ between datasets. We often want to evaluate -- with a statistical measure of significance -- whether systems perform differently either on a given dataset according to a single metric, on aggregate across metrics on a dataset, or across datasets. Such evaluations can be done to support decision-making, such as deciding whether a particular system component change (e.g., choice of LLM or hyperparameter values) significantly improves performance over the current system configuration, or, more generally, whether a fixed set of system configurations (e.g., a leaderboard list) have significantly different performances according to metrics of interest. We present a framework implementation that automatically performs the correct statistical tests, properly aggregates the statistical results across metrics and datasets (a nontrivial task), and can visualize the results. The framework is demonstrated on the multi-lingual code generation benchmark CrossCodeEval, for several state-of-the-art LLMs.
A Novel Metric for Measuring the Robustness of Large Language Models in Non-adversarial Scenarios
Aug 04, 2024We evaluate the robustness of several large language models on multiple datasets. Robustness here refers to the relative insensitivity of the model's answers to meaning-preserving variants of their input. Benchmark datasets are constructed by introducing naturally-occurring, non-malicious perturbations, or by generating semantically equivalent paraphrases of input questions or statements. We further propose a novel metric for assessing a model robustness, and demonstrate its benefits in the non-adversarial scenario by empirical evaluation of several models on the created datasets.
Using Combinatorial Optimization to Design a High quality LLM Solution
May 15, 2024We introduce a novel LLM based solution design approach that utilizes combinatorial optimization and sampling. Specifically, a set of factors that influence the quality of the solution are identified. They typically include factors that represent prompt types, LLM inputs alternatives, and parameters governing the generation and design alternatives. Identifying the factors that govern the LLM solution quality enables the infusion of subject matter expert knowledge. Next, a set of interactions between the factors are defined and combinatorial optimization is used to create a small subset $P$ that ensures all desired interactions occur in $P$. Each element $p \in P$ is then developed into an appropriate benchmark. Applying the alternative solutions on each combination, $p \in P$ and evaluating the results facilitate the design of a high quality LLM solution pipeline. The approach is especially applicable when the design and evaluation of each benchmark in $P$ is time-consuming and involves manual steps and human evaluation. Given its efficiency the approach can also be used as a baseline to compare and validate an autoML approach that searches over the factors governing the solution.
Predicting Question-Answering Performance of Large Language Models through Semantic Consistency
Nov 02, 2023



Semantic consistency of a language model is broadly defined as the model's ability to produce semantically-equivalent outputs, given semantically-equivalent inputs. We address the task of assessing question-answering (QA) semantic consistency of contemporary large language models (LLMs) by manually creating a benchmark dataset with high-quality paraphrases for factual questions, and release the dataset to the community. We further combine the semantic consistency metric with additional measurements suggested in prior work as correlating with LLM QA accuracy, for building and evaluating a framework for factual QA reference-less performance prediction -- predicting the likelihood of a language model to accurately answer a question. Evaluating the framework on five contemporary LLMs, we demonstrate encouraging, significantly outperforming baselines, results.
Characterizing how 'distributional' NLP corpora distance metrics are
Oct 23, 2023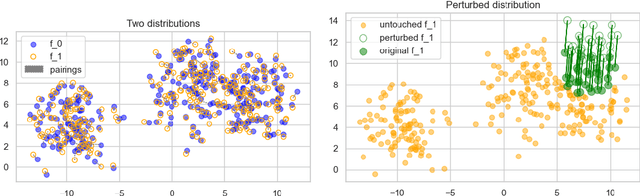
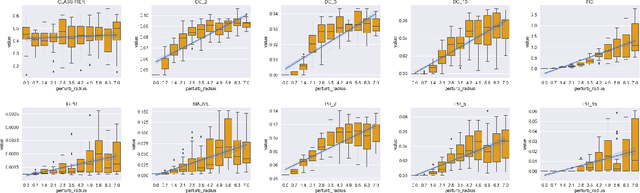
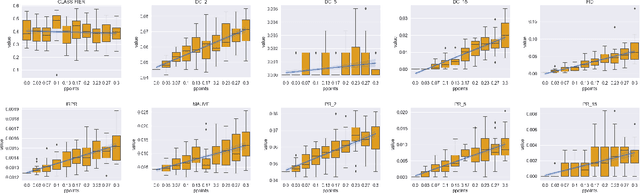
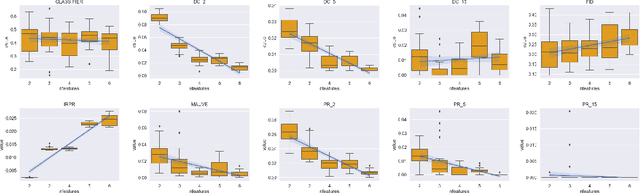
A corpus of vector-embedded text documents has some empirical distribution. Given two corpora, we want to calculate a single metric of distance (e.g., Mauve, Frechet Inception) between them. We describe an abstract quality, called `distributionality', of such metrics. A non-distributional metric tends to use very local measurements, or uses global measurements in a way that does not fully reflect the distributions' true distance. For example, if individual pairwise nearest-neighbor distances are low, it may judge the two corpora to have low distance, even if their two distributions are in fact far from each other. A more distributional metric will, in contrast, better capture the distributions' overall distance. We quantify this quality by constructing a Known-Similarity Corpora set from two paraphrase corpora and calculating the distance between paired corpora from it. The distances' trend shape as set element separation increases should quantify the distributionality of the metric. We propose that Average Hausdorff Distance and energy distance between corpora are representative examples of non-distributional and distributional distance metrics, to which other metrics can be compared, to evaluate how distributional they are.
Data Drift Monitoring for Log Anomaly Detection Pipelines
Oct 17, 2023
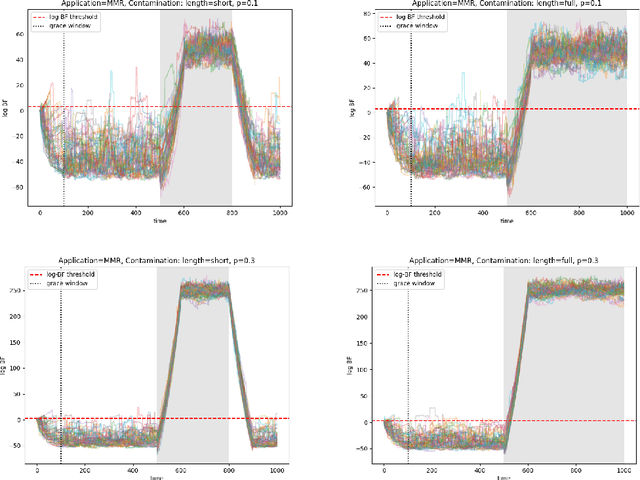
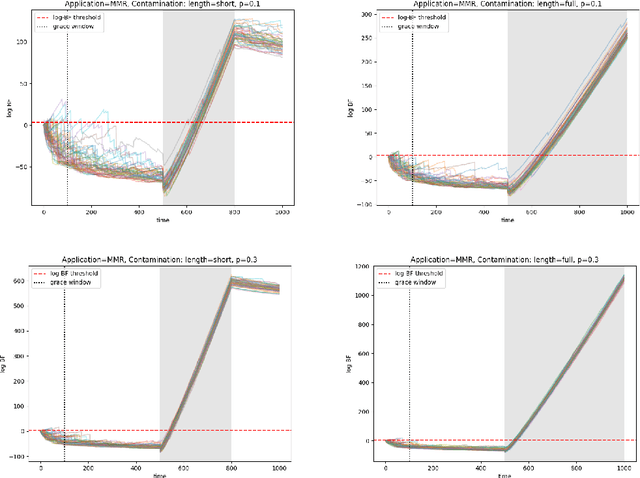
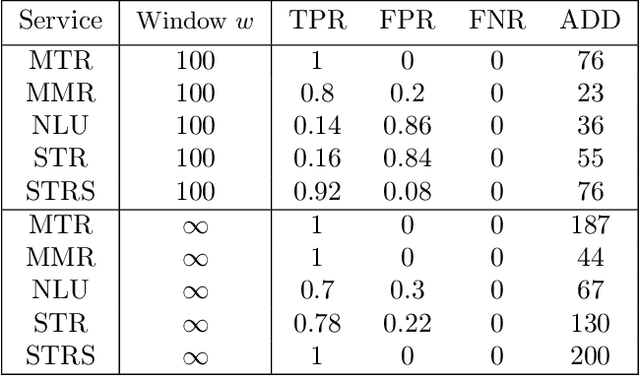
Logs enable the monitoring of infrastructure status and the performance of associated applications. Logs are also invaluable for diagnosing the root causes of any problems that may arise. Log Anomaly Detection (LAD) pipelines automate the detection of anomalies in logs, providing assistance to site reliability engineers (SREs) in system diagnosis. Log patterns change over time, necessitating updates to the LAD model defining the `normal' log activity profile. In this paper, we introduce a Bayes Factor-based drift detection method that identifies when intervention, retraining, and updating of the LAD model are required with human involvement. We illustrate our method using sequences of log activity, both from unaltered data, and simulated activity with controlled levels of anomaly contamination, based on real collected log data.
Reliable and Interpretable Drift Detection in Streams of Short Texts
May 28, 2023Data drift is the change in model input data that is one of the key factors leading to machine learning models performance degradation over time. Monitoring drift helps detecting these issues and preventing their harmful consequences. Meaningful drift interpretation is a fundamental step towards effective re-training of the model. In this study we propose an end-to-end framework for reliable model-agnostic change-point detection and interpretation in large task-oriented dialog systems, proven effective in multiple customer deployments. We evaluate our approach and demonstrate its benefits with a novel variant of intent classification training dataset, simulating customer requests to a dialog system. We make the data publicly available.
Automatic Generation of Attention Rules For Containment of Machine Learning Model Errors
May 14, 2023


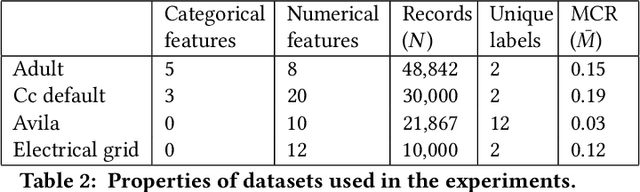
Machine learning (ML) solutions are prevalent in many applications. However, many challenges exist in making these solutions business-grade. For instance, maintaining the error rate of the underlying ML models at an acceptably low level. Typically, the true relationship between feature inputs and the target feature to be predicted is uncertain, and hence statistical in nature. The approach we propose is to separate the observations that are the most likely to be predicted incorrectly into 'attention sets'. These can directly aid model diagnosis and improvement, and be used to decide on alternative courses of action for these problematic observations. We present several algorithms (`strategies') for determining optimal rules to separate these observations. In particular, we prefer strategies that use feature-based slicing because they are human-interpretable, model-agnostic, and require minimal supplementary inputs or knowledge. In addition, we show that these strategies outperform several common baselines, such as selecting observations with prediction confidence below a threshold. To evaluate strategies, we introduce metrics to measure various desired qualities, such as their performance, stability, and generalizability to unseen data; the strategies are evaluated on several publicly-available datasets. We use TOPSIS, a Multiple Criteria Decision Making method, to aggregate these metrics into a single quality score for each strategy, to allow comparison.
Measuring the Measuring Tools: An Automatic Evaluation of Semantic Metrics for Text Corpora
Nov 29, 2022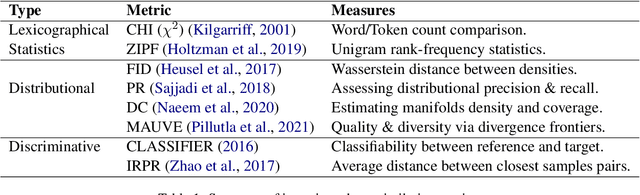
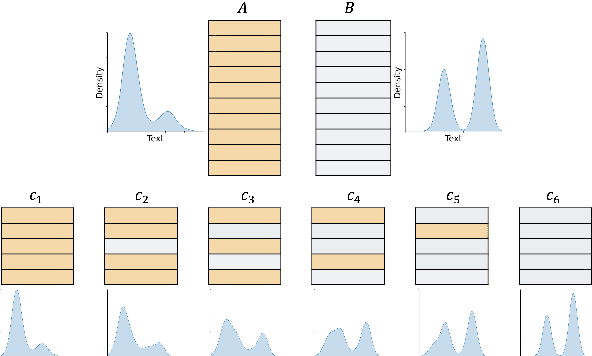
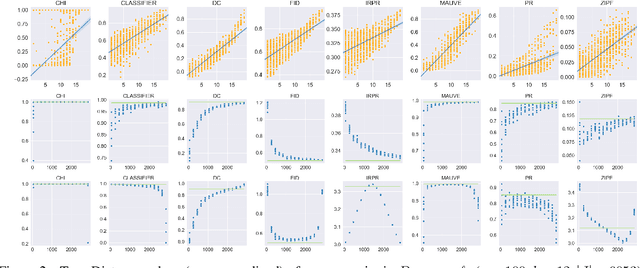
The ability to compare the semantic similarity between text corpora is important in a variety of natural language processing applications. However, standard methods for evaluating these metrics have yet to be established. We propose a set of automatic and interpretable measures for assessing the characteristics of corpus-level semantic similarity metrics, allowing sensible comparison of their behavior. We demonstrate the effectiveness of our evaluation measures in capturing fundamental characteristics by evaluating them on a collection of classical and state-of-the-art metrics. Our measures revealed that recently-developed metrics are becoming better in identifying semantic distributional mismatch while classical metrics are more sensitive to perturbations in the surface text levels.