 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExperiment Based Crafting and Analyzing of Machine Learning Solutions
Jan 02, 2022
The crafting of machine learning (ML) based systems requires statistical control throughout its life cycle. Careful quantification of business requirements and identification of key factors that impact the business requirements reduces the risk of a project failure. The quantification of business requirements results in the definition of random variables representing the system key performance indicators that need to be analyzed through statistical experiments. In addition, available data for training and experiment results impact the design of the system. Once the system is developed, it is tested and continually monitored to ensure it meets its business requirements. This is done through the continued application of statistical experiments to analyze and control the key performance indicators. This book teaches the art of crafting and developing ML based systems. It advocates an "experiment first" approach stressing the need to define statistical experiments from the beginning of the project life cycle. It also discusses in detail how to apply statistical control on the ML based system throughout its lifecycle.
Broadly Applicable Targeted Data Sample Omission Attacks
May 05, 2021



We introduce a novel clean-label targeted poisoning attack on learning mechanisms. While classical poisoning attacks typically corrupt data via addition, modification and omission, our attack focuses on data omission only. Our attack misclassifies a single, targeted test sample of choice, without manipulating that sample. We demonstrate the effectiveness of omission attacks against a large variety of learners including deep neural networks, SVM and decision trees, using several datasets including MNIST, IMDB and CIFAR. The focus of our attack on data omission only is beneficial as well, as it is simpler to implement and analyze. We show that, with a low attack budget, our attack's success rate is above 80%, and in some cases 100%, for white-box learning. It is systematically above the reference benchmark for black-box learning. For both white-box and black-box cases, changes in model accuracy are negligible, regardless of the specific learner and dataset. We also prove theoretically in a simplified agnostic PAC learning framework that, subject to dataset size and distribution, our omission attack succeeds with high probability against any successful simplified agnostic PAC learner.
Anytime Coalition Structure Generation with Worst Case Guarantees
Oct 05, 1998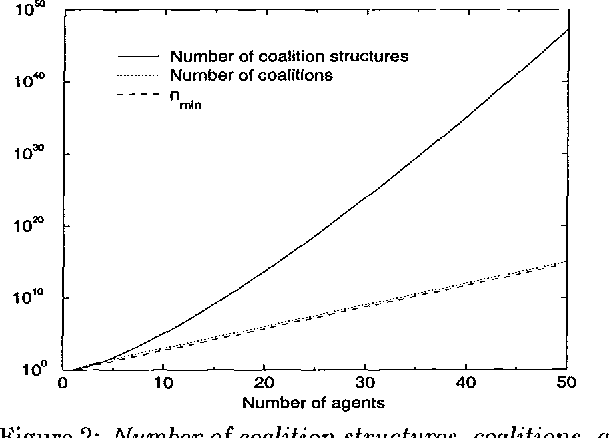
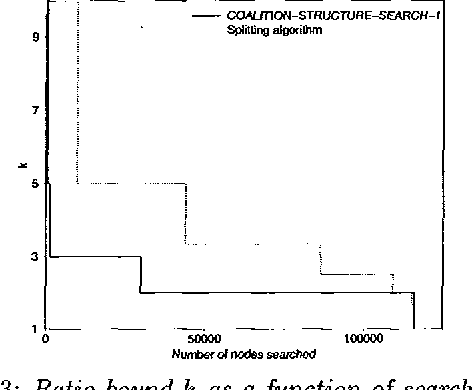
Coalition formation is a key topic in multiagent systems. One would prefer a coalition structure that maximizes the sum of the values of the coalitions, but often the number of coalition structures is too large to allow exhaustive search for the optimal one. But then, can the coalition structure found via a partial search be guaranteed to be within a bound from optimum? We show that none of the previous coalition structure generation algorithms can establish any bound because they search fewer nodes than a threshold that we show necessary for establishing a bound. We present an algorithm that establishes a tight bound within this minimal amount of search, and show that any other algorithm would have to search strictly more. The fraction of nodes needed to be searched approaches zero as the number of agents grows. If additional time remains, our anytime algorithm searches further, and establishes a progressively lower tight bound. Surprisingly, just searching one more node drops the bound in half. As desired, our algorithm lowers the bound rapidly early on, and exhibits diminishing returns to computation. It also drastically outperforms its obvious contenders. Finally, we show how to distribute the desired search across self-interested manipulative agents.