 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNear-Miss: Latent Policy Failure Detection in Agentic Workflows
Mar 31, 2026Agentic systems for business process automation often require compliance with policies governing conditional updates to the system state. Evaluation of policy adherence in LLM-based agentic workflows is typically performed by comparing the final system state against a predefined ground truth. While this approach detects explicit policy violations, it may overlook a more subtle class of issues in which agents bypass required policy checks, yet reach a correct outcome due to favorable circumstances. We refer to such cases as $\textit{near-misses}$ or $\textit{latent failures}$. In this work, we introduce a novel metric for detecting latent policy failures in agent conversations traces. Building on the ToolGuard framework, which converts natural-language policies into executable guard code, our method analyzes agent trajectories to determine whether agent's tool-calling decisions where sufficiently informed. We evaluate our approach on the $τ^2$-verified Airlines benchmark across several contemporary open and proprietary LLMs acting as agents. Our results show that latent failures occur in 8-17% of trajectories involving mutating tool calls, even when the final outcome matches the expected ground-truth state. These findings reveal a blind spot in current evaluation methodologies and highlight the need for metrics that assess not only final outcomes but also the decision process leading to them.
Towards Enforcing Company Policy Adherence in Agentic Workflows
Jul 22, 2025Large Language Model (LLM) agents hold promise for a flexible and scalable alternative to traditional business process automation, but struggle to reliably follow complex company policies. In this study we introduce a deterministic, transparent, and modular framework for enforcing business policy adherence in agentic workflows. Our method operates in two phases: (1) an offline buildtime stage that compiles policy documents into verifiable guard code associated with tool use, and (2) a runtime integration where these guards ensure compliance before each agent action. We demonstrate our approach on the challenging $\tau$-bench Airlines domain, showing encouraging preliminary results in policy enforcement, and further outline key challenges for real-world deployments.
SpeCrawler: Generating OpenAPI Specifications from API Documentation Using Large Language Models
Feb 18, 2024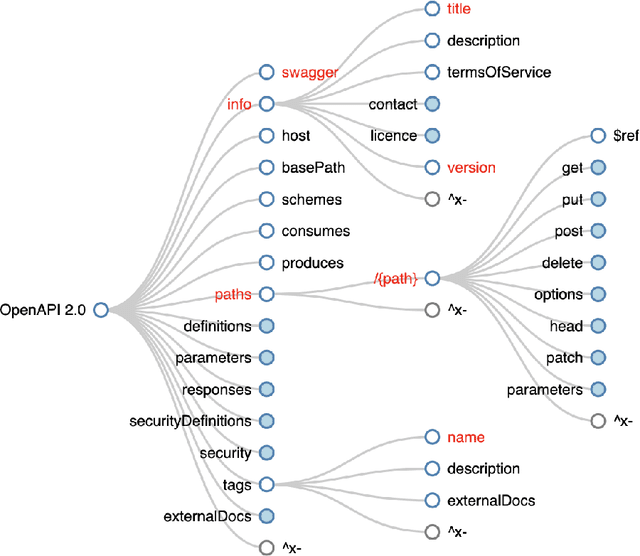

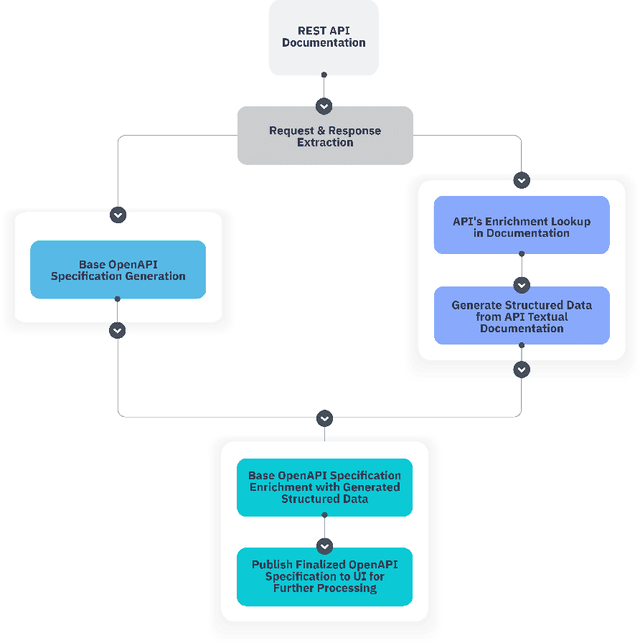
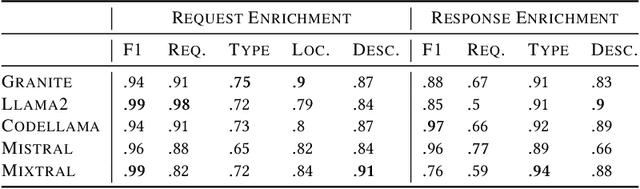
In the digital era, the widespread use of APIs is evident. However, scalable utilization of APIs poses a challenge due to structure divergence observed in online API documentation. This underscores the need for automatic tools to facilitate API consumption. A viable approach involves the conversion of documentation into an API Specification format. While previous attempts have been made using rule-based methods, these approaches encountered difficulties in generalizing across diverse documentation. In this paper we introduce SpeCrawler, a comprehensive system that utilizes large language models (LLMs) to generate OpenAPI Specifications from diverse API documentation through a carefully crafted pipeline. By creating a standardized format for numerous APIs, SpeCrawler aids in streamlining integration processes within API orchestrating systems and facilitating the incorporation of tools into LLMs. The paper explores SpeCrawler's methodology, supported by empirical evidence and case studies, demonstrating its efficacy through LLM capabilities.
Gaining Insights into Unrecognized User Utterances in Task-Oriented Dialog Systems
Apr 11, 2022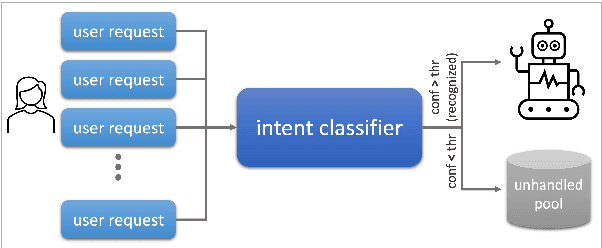

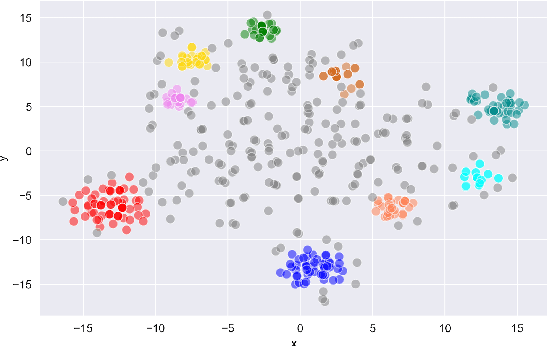
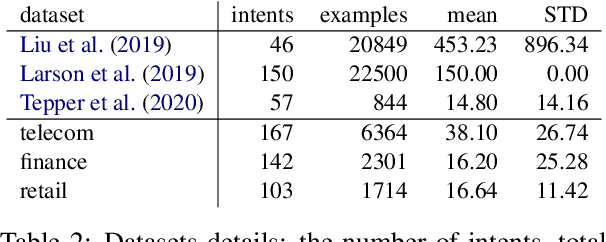
The rapidly growing market demand for dialogue agents capable of goal-oriented behavior has caused many tech-industry leaders to invest considerable efforts into task-oriented dialog systems. The performance and success of these systems is highly dependent on the accuracy of their intent identification -- the process of deducing the goal or meaning of the user's request and mapping it to one of the known intents for further processing. Gaining insights into unrecognized utterances -- user requests the systems fails to attribute to a known intent -- is therefore a key process in continuous improvement of goal-oriented dialog systems. We present an end-to-end pipeline for processing unrecognized user utterances, including a specifically-tailored clustering algorithm, a novel approach to cluster representative extraction, and cluster naming. We evaluated the proposed clustering algorithm and compared its performance to out-of-the-box SOTA solutions, demonstrating its benefits in the analysis of unrecognized user requests.
We've had this conversation before: A Novel Approach to Measuring Dialog Similarity
Oct 12, 2021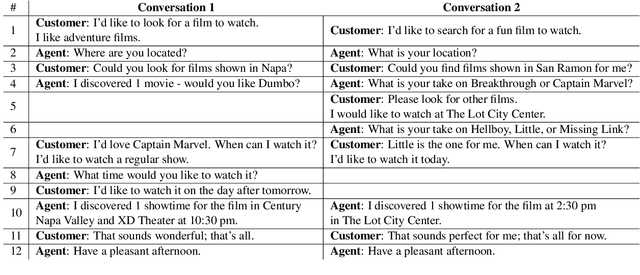
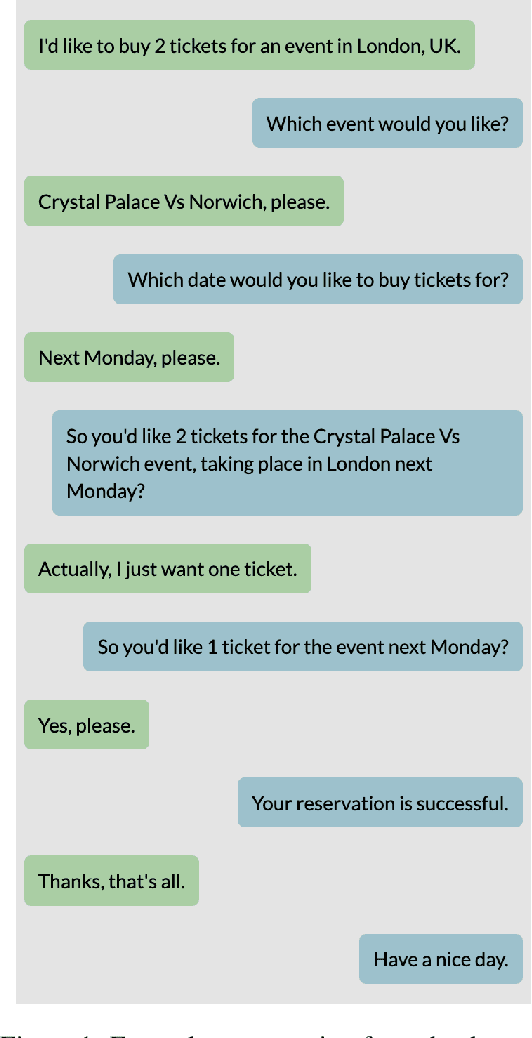
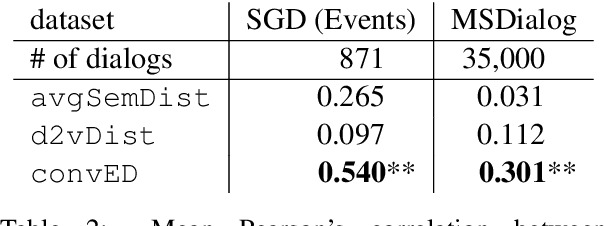
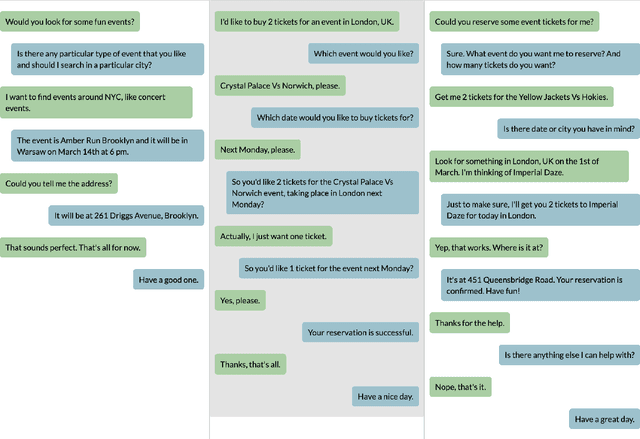
Dialog is a core building block of human natural language interactions. It contains multi-party utterances used to convey information from one party to another in a dynamic and evolving manner. The ability to compare dialogs is beneficial in many real world use cases, such as conversation analytics for contact center calls and virtual agent design. We propose a novel adaptation of the edit distance metric to the scenario of dialog similarity. Our approach takes into account various conversation aspects such as utterance semantics, conversation flow, and the participants. We evaluate this new approach and compare it to existing document similarity measures on two publicly available datasets. The results demonstrate that our method outperforms the other approaches in capturing dialog flow, and is better aligned with the human perception of conversation similarity.