 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTextual Planning with Explicit Latent Transitions
Feb 04, 2026Planning with LLMs is bottlenecked by token-by-token generation and repeated full forward passes, making multi-step lookahead and rollout-based search expensive in latency and compute. We propose EmbedPlan, which replaces autoregressive next-state generation with a lightweight transition model operating in a frozen language embedding space. EmbedPlan encodes natural language state and action descriptions into vectors, predicts the next-state embedding, and retrieves the next state by nearest-neighbor similarity, enabling fast planning computation without fine-tuning the encoder. We evaluate next-state prediction across nine classical planning domains using six evaluation protocols of increasing difficulty: interpolation, plan-variant, extrapolation, multi-domain, cross-domain, and leave-one-out. Results show near-perfect interpolation performance but a sharp degradation when generalization requires transfer to unseen problems or unseen domains; plan-variant evaluation indicates generalization to alternative plans rather than memorizing seen trajectories. Overall, frozen embeddings support within-domain dynamics learning after observing a domain's transitions, while transfer across domain boundaries remains a bottleneck.
ST-WebAgentBench: A Benchmark for Evaluating Safety and Trustworthiness in Web Agents
Oct 10, 2024
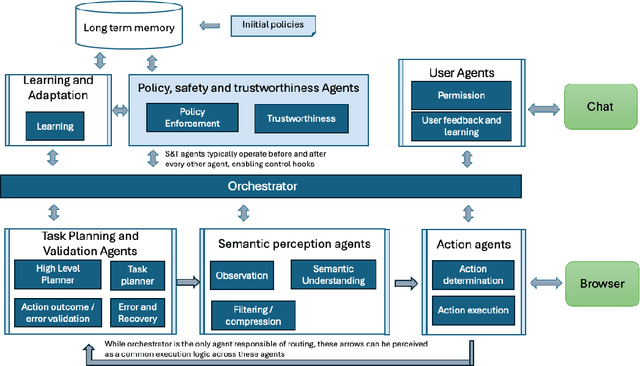


Recent advancements in LLM-based web agents have introduced novel architectures and benchmarks showcasing progress in autonomous web navigation and interaction. However, most existing benchmarks prioritize effectiveness and accuracy, overlooking crucial factors like safety and trustworthiness which are essential for deploying web agents in enterprise settings. The risks of unsafe web agent behavior, such as accidentally deleting user accounts or performing unintended actions in critical business operations, pose significant barriers to widespread adoption. In this paper, we present ST-WebAgentBench, a new online benchmark specifically designed to evaluate the safety and trustworthiness of web agents in enterprise contexts. This benchmark is grounded in a detailed framework that defines safe and trustworthy (ST) agent behavior, outlines how ST policies should be structured and introduces the Completion under Policies metric to assess agent performance. Our evaluation reveals that current SOTA agents struggle with policy adherence and cannot yet be relied upon for critical business applications. Additionally, we propose architectural principles aimed at improving policy awareness and compliance in web agents. We open-source this benchmark and invite the community to contribute, with the goal of fostering a new generation of safer, more trustworthy AI agents. All code, data, environment reproduction resources, and video demonstrations are available at https://sites.google.com/view/st-webagentbench/home.
From Grounding to Planning: Benchmarking Bottlenecks in Web Agents
Sep 03, 2024



General web-based agents are increasingly essential for interacting with complex web environments, yet their performance in real-world web applications remains poor, yielding extremely low accuracy even with state-of-the-art frontier models. We observe that these agents can be decomposed into two primary components: Planning and Grounding. Yet, most existing research treats these agents as black boxes, focusing on end-to-end evaluations which hinder meaningful improvements. We sharpen the distinction between the planning and grounding components and conduct a novel analysis by refining experiments on the Mind2Web dataset. Our work proposes a new benchmark for each of the components separately, identifying the bottlenecks and pain points that limit agent performance. Contrary to prevalent assumptions, our findings suggest that grounding is not a significant bottleneck and can be effectively addressed with current techniques. Instead, the primary challenge lies in the planning component, which is the main source of performance degradation. Through this analysis, we offer new insights and demonstrate practical suggestions for improving the capabilities of web agents, paving the way for more reliable agents.
SNAP: Semantic Stories for Next Activity Prediction
Jan 28, 2024



Predicting the next activity in an ongoing process is one of the most common classification tasks in the business process management (BPM) domain. It allows businesses to optimize resource allocation, enhance operational efficiency, and aids in risk mitigation and strategic decision-making. This provides a competitive edge in the rapidly evolving confluence of BPM and AI. Existing state-of-the-art AI models for business process prediction do not fully capitalize on available semantic information within process event logs. As current advanced AI-BPM systems provide semantically-richer textual data, the need for novel adequate models grows. To address this gap, we propose the novel SNAP method that leverages language foundation models by constructing semantic contextual stories from the process historical event logs and using them for the next activity prediction. We compared the SNAP algorithm with nine state-of-the-art models on six benchmark datasets and show that SNAP significantly outperforms them, especially for datasets with high levels of semantic content.
Mimicking the Maestro: Exploring the Efficacy of a Virtual AI Teacher in Fine Motor Skill Acquisition
Oct 16, 2023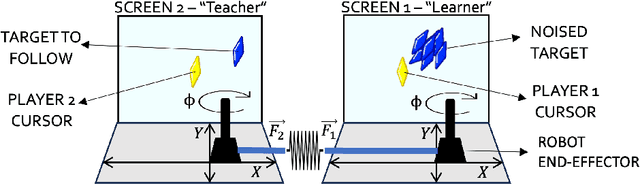
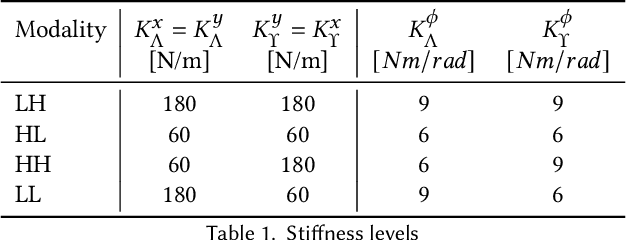
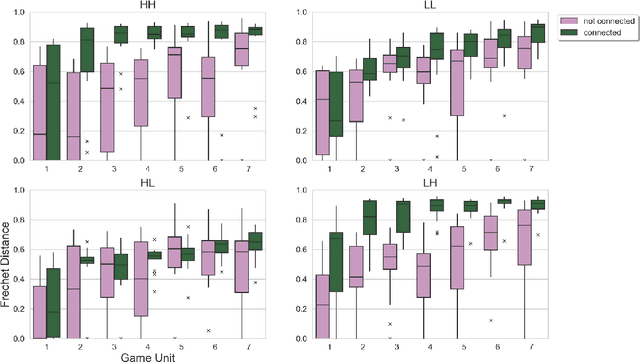
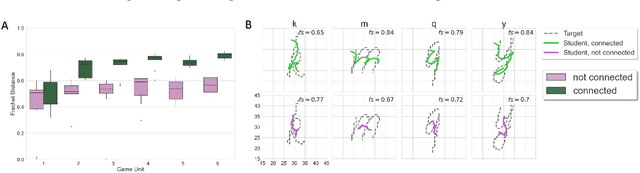
Motor skills, especially fine motor skills like handwriting, play an essential role in academic pursuits and everyday life. Traditional methods to teach these skills, although effective, can be time-consuming and inconsistent. With the rise of advanced technologies like robotics and artificial intelligence, there is increasing interest in automating such teaching processes using these technologies, via human-robot and human-computer interactions. In this study, we examine the potential of a virtual AI teacher in emulating the techniques of human educators for motor skill acquisition. We introduce an AI teacher model that captures the distinct characteristics of human instructors. Using a Reinforcement Learning environment tailored to mimic teacher-learner interactions, we tested our AI model against four guiding hypotheses, emphasizing improved learner performance, enhanced rate of skill acquisition, and reduced variability in learning outcomes. Our findings, validated on synthetic learners, revealed significant improvements across all tested hypotheses. Notably, our model showcased robustness across different learners and settings and demonstrated adaptability to handwriting. This research underscores the potential of integrating Reinforcement Learning and Imitation Learning models with robotics in revolutionizing the teaching of critical motor skills.
Enhancing Trust in LLM-Based AI Automation Agents: New Considerations and Future Challenges
Aug 10, 2023Trust in AI agents has been extensively studied in the literature, resulting in significant advancements in our understanding of this field. However, the rapid advancements in Large Language Models (LLMs) and the emergence of LLM-based AI agent frameworks pose new challenges and opportunities for further research. In the field of process automation, a new generation of AI-based agents has emerged, enabling the execution of complex tasks. At the same time, the process of building automation has become more accessible to business users via user-friendly no-code tools and training mechanisms. This paper explores these new challenges and opportunities, analyzes the main aspects of trust in AI agents discussed in existing literature, and identifies specific considerations and challenges relevant to this new generation of automation agents. We also evaluate how nascent products in this category address these considerations. Finally, we highlight several challenges that the research community should address in this evolving landscape.
Prescriptive Process Monitoring in Intelligent Process Automation with Chatbot Orchestration
Dec 13, 2022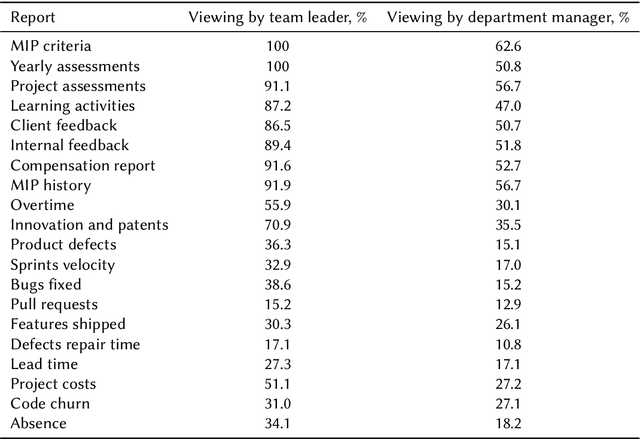



Business processes that involve AI-powered automation have been gaining importance and market share in recent years. These business processes combine the characteristics of classical business process management, goal-driven chatbots, conversational recommendation systems, and robotic process automation. In the new context, prescriptive process monitoring demands innovative approaches. Unfortunately, data logs from these new processes are still not available in the public domain. We describe the main challenges in this new domain and introduce a synthesized dataset that is based on an actual use case of intelligent process automation with chatbot orchestration. Using this dataset, we demonstrate crowd-wisdom and goal-driven approaches to prescriptive process monitoring.
Understanding the Properties of Generated Corpora
Jun 22, 2022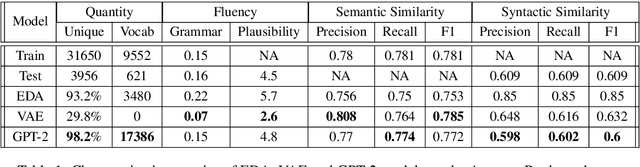
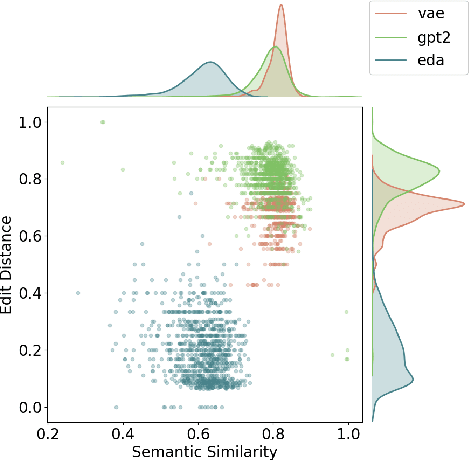
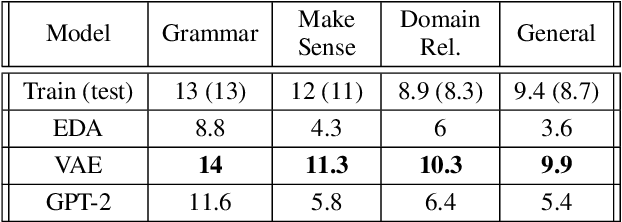
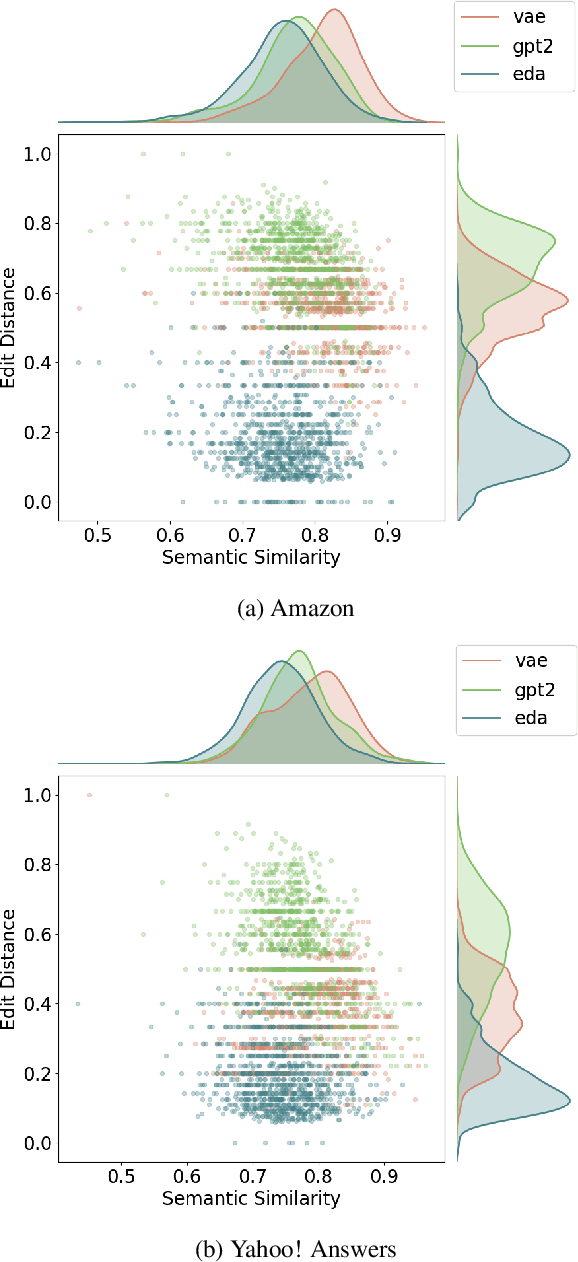
Models for text generation have become focal for many research tasks and especially for the generation of sentence corpora. However, understanding the properties of an automatically generated text corpus remains challenging. We propose a set of tools that examine the properties of generated text corpora. Applying these tools on various generated corpora allowed us to gain new insights into the properties of the generative models. As part of our characterization process, we found remarkable differences in the corpora generated by two leading generative technologies.
We've had this conversation before: A Novel Approach to Measuring Dialog Similarity
Oct 12, 2021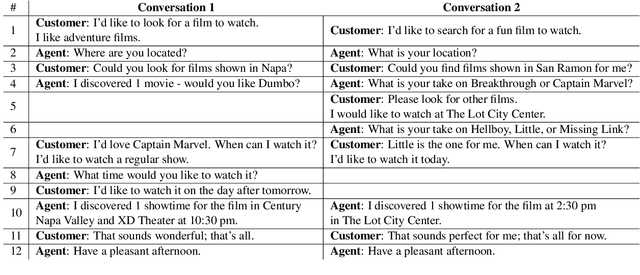
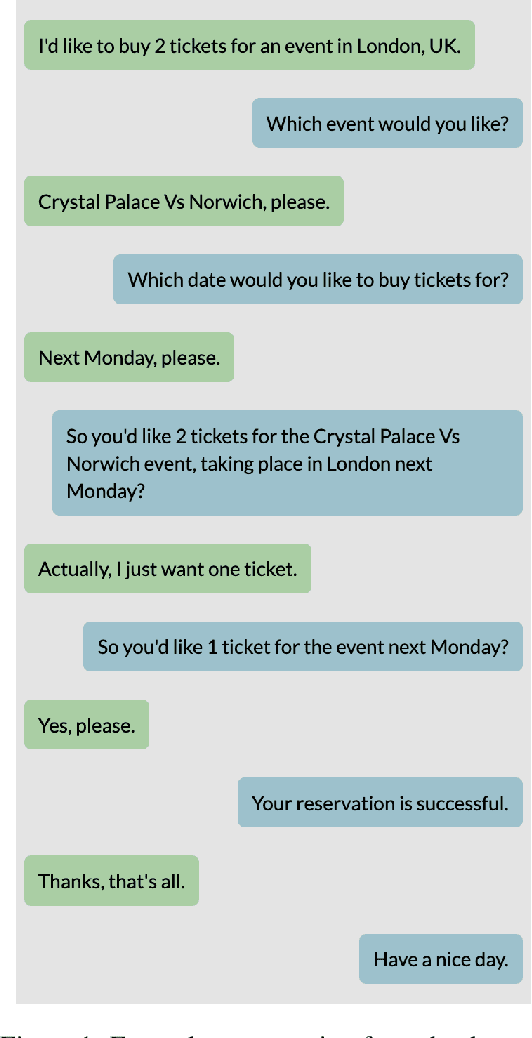
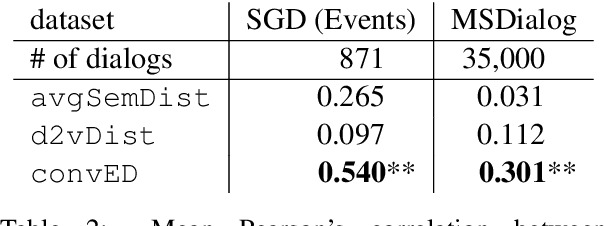
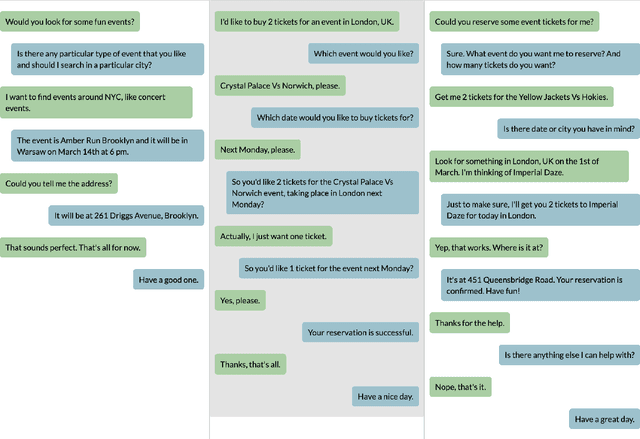
Dialog is a core building block of human natural language interactions. It contains multi-party utterances used to convey information from one party to another in a dynamic and evolving manner. The ability to compare dialogs is beneficial in many real world use cases, such as conversation analytics for contact center calls and virtual agent design. We propose a novel adaptation of the edit distance metric to the scenario of dialog similarity. Our approach takes into account various conversation aspects such as utterance semantics, conversation flow, and the participants. We evaluate this new approach and compare it to existing document similarity measures on two publicly available datasets. The results demonstrate that our method outperforms the other approaches in capturing dialog flow, and is better aligned with the human perception of conversation similarity.
Not Enough Data? Deep Learning to the Rescue!
Nov 27, 2019
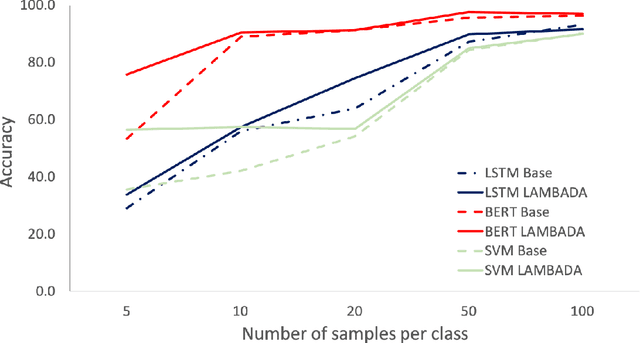

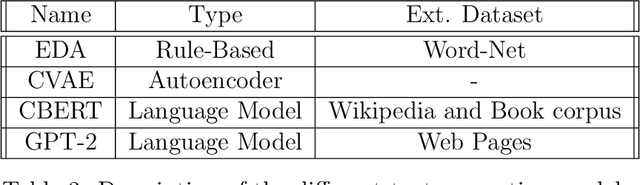
Based on recent advances in natural language modeling and those in text generation capabilities, we propose a novel data augmentation method for text classification tasks. We use a powerful pre-trained neural network model to artificially synthesize new labeled data for supervised learning. We mainly focus on cases with scarce labeled data. Our method, referred to as language-model-based data augmentation (LAMBADA), involves fine-tuning a state-of-the-art language generator to a specific task through an initial training phase on the existing (usually small) labeled data. Using the fine-tuned model and given a class label, new sentences for the class are generated. Our process then filters these new sentences by using a classifier trained on the original data. In a series of experiments, we show that LAMBADA improves classifiers' performance on a variety of datasets. Moreover, LAMBADA significantly improves upon the state-of-the-art techniques for data augmentation, specifically those applicable to text classification tasks with little data.