 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnderstanding the Properties of Generated Corpora
Jun 22, 2022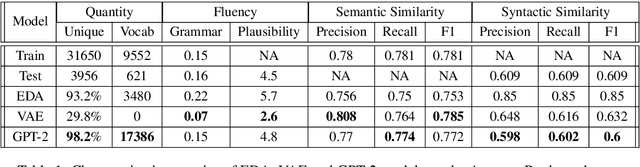
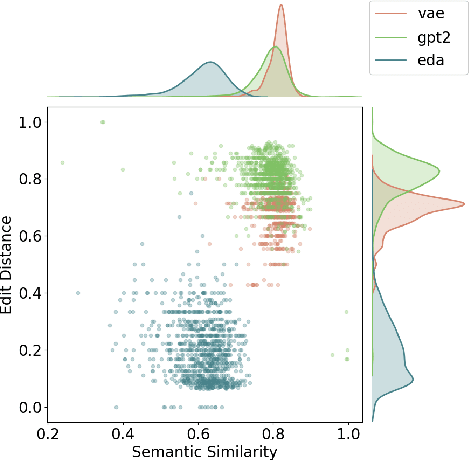
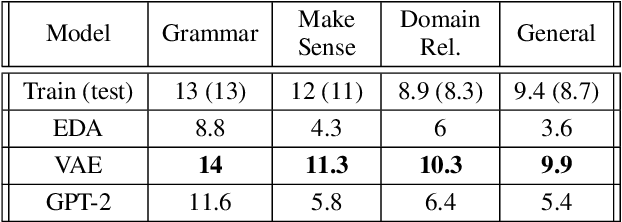
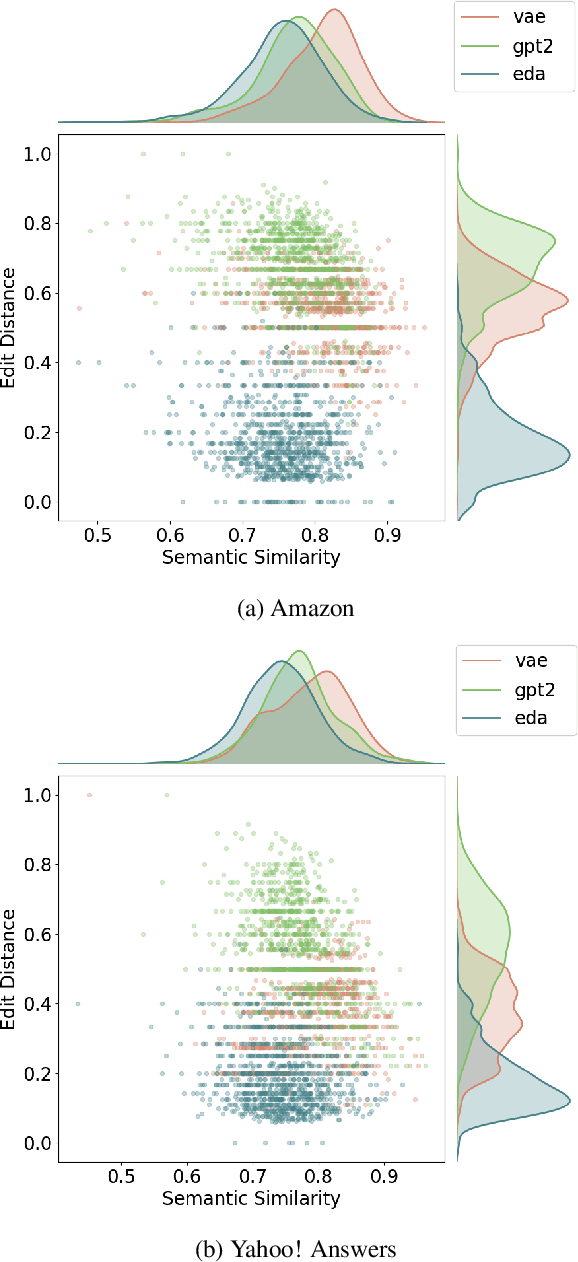
Models for text generation have become focal for many research tasks and especially for the generation of sentence corpora. However, understanding the properties of an automatically generated text corpus remains challenging. We propose a set of tools that examine the properties of generated text corpora. Applying these tools on various generated corpora allowed us to gain new insights into the properties of the generative models. As part of our characterization process, we found remarkable differences in the corpora generated by two leading generative technologies.
Answer Identification in Collaborative Organizational Group Chat
Nov 04, 2020


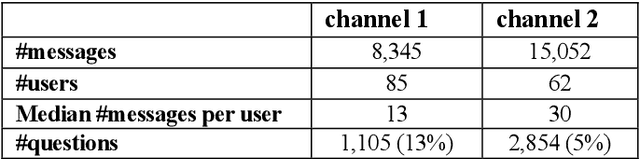
We present a simple unsupervised approach for answer identification in organizational group chat. In recent years, organizational group chat is on the rise enabling asynchronous text-based collaboration between co-workers in different locations and time zones. Finding answers to questions is often critical for work efficiency. However, group chat is characterized by intertwined conversations and 'always on' availability, making it hard for users to pinpoint answers to questions they care about in real-time or search for answers in retrospective. In addition, structural and lexical characteristics differ between chat groups, making it hard to find a 'one model fits all' approach. Our Kernel Density Estimation (KDE) based clustering approach termed Ans-Chat implicitly learns discussion patterns as a means for answer identification, thus eliminating the need to channel-specific tagging. Empirical evaluation shows that this solution outperforms other approached.
Not Enough Data? Deep Learning to the Rescue!
Nov 27, 2019
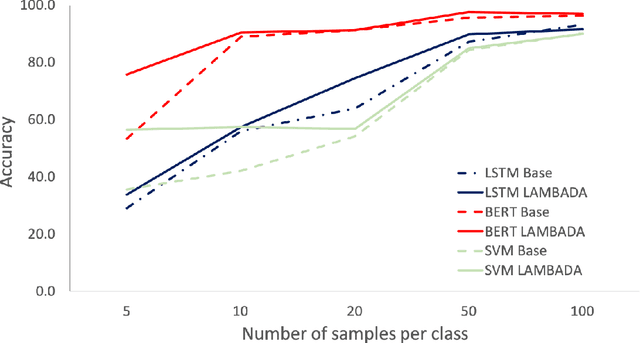

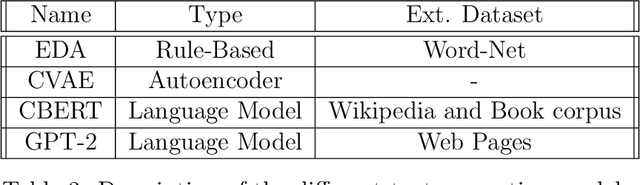
Based on recent advances in natural language modeling and those in text generation capabilities, we propose a novel data augmentation method for text classification tasks. We use a powerful pre-trained neural network model to artificially synthesize new labeled data for supervised learning. We mainly focus on cases with scarce labeled data. Our method, referred to as language-model-based data augmentation (LAMBADA), involves fine-tuning a state-of-the-art language generator to a specific task through an initial training phase on the existing (usually small) labeled data. Using the fine-tuned model and given a class label, new sentences for the class are generated. Our process then filters these new sentences by using a classifier trained on the original data. In a series of experiments, we show that LAMBADA improves classifiers' performance on a variety of datasets. Moreover, LAMBADA significantly improves upon the state-of-the-art techniques for data augmentation, specifically those applicable to text classification tasks with little data.