 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMeeQA: Natural Questions in Meeting Transcripts
May 15, 2023We present MeeQA, a dataset for natural-language question answering over meeting transcripts. It includes real questions asked during meetings by its participants. The dataset contains 48K question-answer pairs, extracted from 422 meeting transcripts, spanning multiple domains. Questions in transcripts pose a special challenge as they are not always clear, and considerable context may be required in order to provide an answer. Further, many questions asked during meetings are left unanswered. To improve baseline model performance on this type of questions, we also propose a novel loss function, \emph{Flat Hierarchical Loss}, designed to enhance performance over questions with no answer in the text. Our experiments demonstrate the advantage of using our approach over standard QA models.
A Systematic Study of Knowledge Distillation for Natural Language Generation with Pseudo-Target Training
May 03, 2023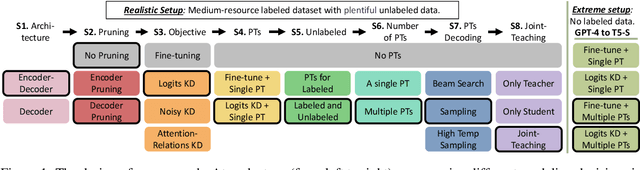



Modern Natural Language Generation (NLG) models come with massive computational and storage requirements. In this work, we study the potential of compressing them, which is crucial for real-world applications serving millions of users. We focus on Knowledge Distillation (KD) techniques, in which a small student model learns to imitate a large teacher model, allowing to transfer knowledge from the teacher to the student. In contrast to much of the previous work, our goal is to optimize the model for a specific NLG task and a specific dataset. Typically, in real-world applications, in addition to labeled data there is abundant unlabeled task-specific data, which is crucial for attaining high compression rates via KD. In this work, we conduct a systematic study of task-specific KD techniques for various NLG tasks under realistic assumptions. We discuss the special characteristics of NLG distillation and particularly the exposure bias problem. Following, we derive a family of Pseudo-Target (PT) augmentation methods, substantially extending prior work on sequence-level KD. We propose the Joint-Teaching method for NLG distillation, which applies word-level KD to multiple PTs generated by both the teacher and the student. Our study provides practical model design observations and demonstrates the effectiveness of PT training for task-specific KD in NLG.
Not Enough Data? Deep Learning to the Rescue!
Nov 27, 2019
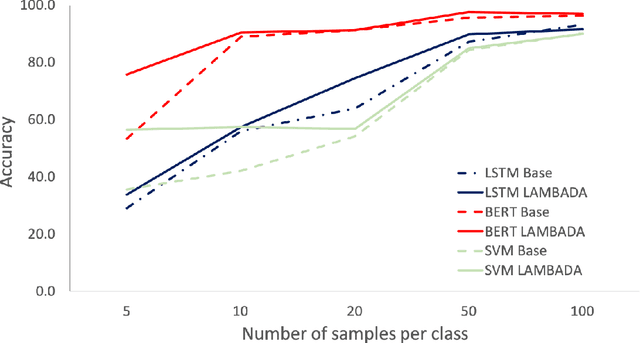

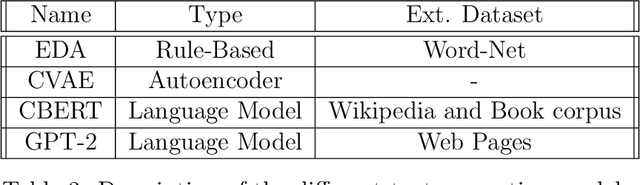
Based on recent advances in natural language modeling and those in text generation capabilities, we propose a novel data augmentation method for text classification tasks. We use a powerful pre-trained neural network model to artificially synthesize new labeled data for supervised learning. We mainly focus on cases with scarce labeled data. Our method, referred to as language-model-based data augmentation (LAMBADA), involves fine-tuning a state-of-the-art language generator to a specific task through an initial training phase on the existing (usually small) labeled data. Using the fine-tuned model and given a class label, new sentences for the class are generated. Our process then filters these new sentences by using a classifier trained on the original data. In a series of experiments, we show that LAMBADA improves classifiers' performance on a variety of datasets. Moreover, LAMBADA significantly improves upon the state-of-the-art techniques for data augmentation, specifically those applicable to text classification tasks with little data.