 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJamba-1.5: Hybrid Transformer-Mamba Models at Scale
Aug 22, 2024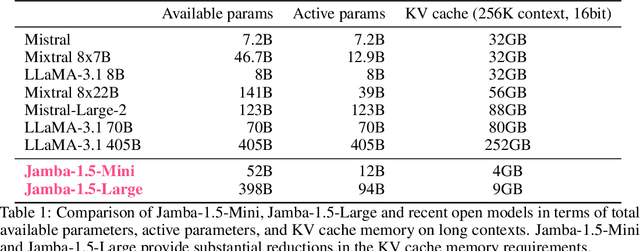
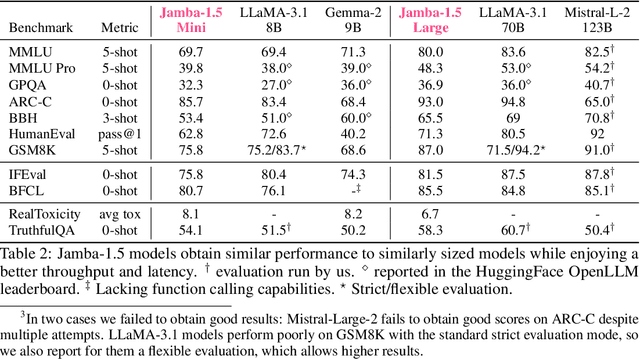
We present Jamba-1.5, new instruction-tuned large language models based on our Jamba architecture. Jamba is a hybrid Transformer-Mamba mixture of experts architecture, providing high throughput and low memory usage across context lengths, while retaining the same or better quality as Transformer models. We release two model sizes: Jamba-1.5-Large, with 94B active parameters, and Jamba-1.5-Mini, with 12B active parameters. Both models are fine-tuned for a variety of conversational and instruction-following capabilties, and have an effective context length of 256K tokens, the largest amongst open-weight models. To support cost-effective inference, we introduce ExpertsInt8, a novel quantization technique that allows fitting Jamba-1.5-Large on a machine with 8 80GB GPUs when processing 256K-token contexts without loss of quality. When evaluated on a battery of academic and chatbot benchmarks, Jamba-1.5 models achieve excellent results while providing high throughput and outperforming other open-weight models on long-context benchmarks. The model weights for both sizes are publicly available under the Jamba Open Model License and we release ExpertsInt8 as open source.
MeeQA: Natural Questions in Meeting Transcripts
May 15, 2023We present MeeQA, a dataset for natural-language question answering over meeting transcripts. It includes real questions asked during meetings by its participants. The dataset contains 48K question-answer pairs, extracted from 422 meeting transcripts, spanning multiple domains. Questions in transcripts pose a special challenge as they are not always clear, and considerable context may be required in order to provide an answer. Further, many questions asked during meetings are left unanswered. To improve baseline model performance on this type of questions, we also propose a novel loss function, \emph{Flat Hierarchical Loss}, designed to enhance performance over questions with no answer in the text. Our experiments demonstrate the advantage of using our approach over standard QA models.
Towards Coherent Visual Storytelling with Ordered Image Attention
Aug 22, 2021


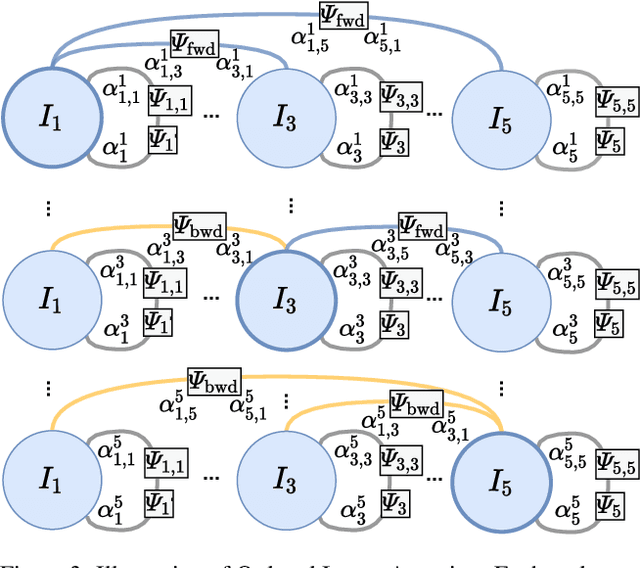
We address the problem of visual storytelling, i.e., generating a story for a given sequence of images. While each sentence of the story should describe a corresponding image, a coherent story also needs to be consistent and relate to both future and past images. To achieve this we develop ordered image attention (OIA). OIA models interactions between the sentence-corresponding image and important regions in other images of the sequence. To highlight the important objects, a message-passing-like algorithm collects representations of those objects in an order-aware manner. To generate the story's sentences, we then highlight important image attention vectors with an Image-Sentence Attention (ISA). Further, to alleviate common linguistic mistakes like repetitiveness, we introduce an adaptive prior. The obtained results improve the METEOR score on the VIST dataset by 1%. In addition, an extensive human study verifies coherency improvements and shows that OIA and ISA generated stories are more focused, shareable, and image-grounded.