 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Enforcing Company Policy Adherence in Agentic Workflows
Jul 22, 2025Large Language Model (LLM) agents hold promise for a flexible and scalable alternative to traditional business process automation, but struggle to reliably follow complex company policies. In this study we introduce a deterministic, transparent, and modular framework for enforcing business policy adherence in agentic workflows. Our method operates in two phases: (1) an offline buildtime stage that compiles policy documents into verifiable guard code associated with tool use, and (2) a runtime integration where these guards ensure compliance before each agent action. We demonstrate our approach on the challenging $\tau$-bench Airlines domain, showing encouraging preliminary results in policy enforcement, and further outline key challenges for real-world deployments.
Exploring Straightforward Conversational Red-Teaming
Sep 07, 2024



Large language models (LLMs) are increasingly used in business dialogue systems but they pose security and ethical risks. Multi-turn conversations, where context influences the model's behavior, can be exploited to produce undesired responses. In this paper, we examine the effectiveness of utilizing off-the-shelf LLMs in straightforward red-teaming approaches, where an attacker LLM aims to elicit undesired output from a target LLM, comparing both single-turn and conversational red-teaming tactics. Our experiments offer insights into various usage strategies that significantly affect their performance as red teamers. They suggest that off-the-shelf models can act as effective red teamers and even adjust their attack strategy based on past attempts, although their effectiveness decreases with greater alignment.
From Zero to Hero: Cold-Start Anomaly Detection
May 30, 2024



When first deploying an anomaly detection system, e.g., to detect out-of-scope queries in chatbots, there are no observed data, making data-driven approaches ineffective. Zero-shot anomaly detection methods offer a solution to such "cold-start" cases, but unfortunately they are often not accurate enough. This paper studies the realistic but underexplored cold-start setting where an anomaly detection model is initialized using zero-shot guidance, but subsequently receives a small number of contaminated observations (namely, that may include anomalies). The goal is to make efficient use of both the zero-shot guidance and the observations. We propose ColdFusion, a method that effectively adapts the zero-shot anomaly detector to contaminated observations. To support future development of this new setting, we propose an evaluation suite consisting of evaluation protocols and metrics.
Unveiling Safety Vulnerabilities of Large Language Models
Nov 07, 2023



As large language models become more prevalent, their possible harmful or inappropriate responses are a cause for concern. This paper introduces a unique dataset containing adversarial examples in the form of questions, which we call AttaQ, designed to provoke such harmful or inappropriate responses. We assess the efficacy of our dataset by analyzing the vulnerabilities of various models when subjected to it. Additionally, we introduce a novel automatic approach for identifying and naming vulnerable semantic regions - input semantic areas for which the model is likely to produce harmful outputs. This is achieved through the application of specialized clustering techniques that consider both the semantic similarity of the input attacks and the harmfulness of the model's responses. Automatically identifying vulnerable semantic regions enhances the evaluation of model weaknesses, facilitating targeted improvements to its safety mechanisms and overall reliability.
Understanding the Properties of Generated Corpora
Jun 22, 2022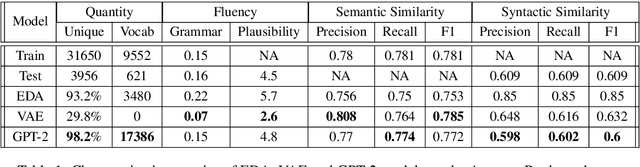
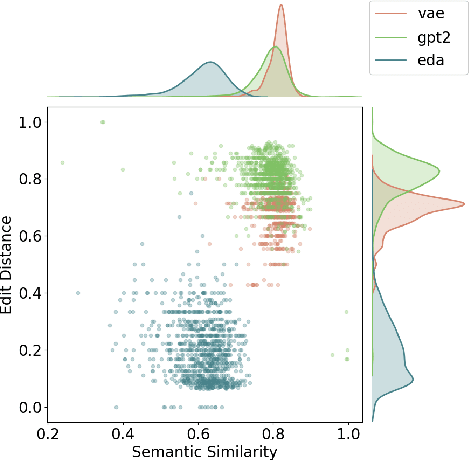
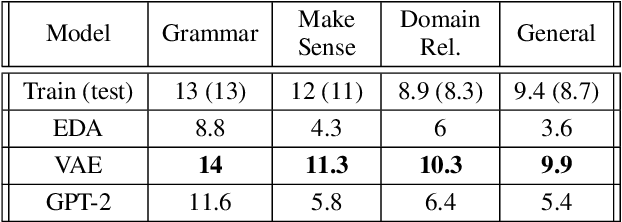
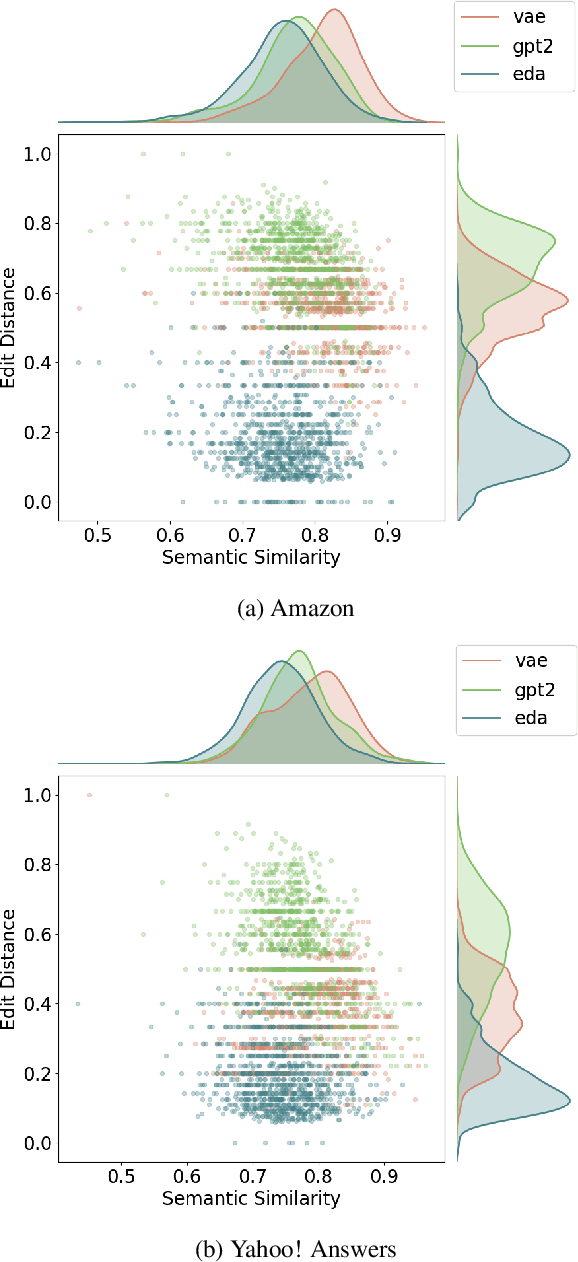
Models for text generation have become focal for many research tasks and especially for the generation of sentence corpora. However, understanding the properties of an automatically generated text corpus remains challenging. We propose a set of tools that examine the properties of generated text corpora. Applying these tools on various generated corpora allowed us to gain new insights into the properties of the generative models. As part of our characterization process, we found remarkable differences in the corpora generated by two leading generative technologies.
Answer Identification in Collaborative Organizational Group Chat
Nov 04, 2020


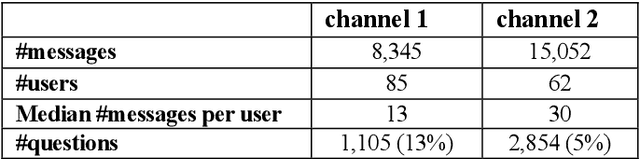
We present a simple unsupervised approach for answer identification in organizational group chat. In recent years, organizational group chat is on the rise enabling asynchronous text-based collaboration between co-workers in different locations and time zones. Finding answers to questions is often critical for work efficiency. However, group chat is characterized by intertwined conversations and 'always on' availability, making it hard for users to pinpoint answers to questions they care about in real-time or search for answers in retrospective. In addition, structural and lexical characteristics differ between chat groups, making it hard to find a 'one model fits all' approach. Our Kernel Density Estimation (KDE) based clustering approach termed Ans-Chat implicitly learns discussion patterns as a means for answer identification, thus eliminating the need to channel-specific tagging. Empirical evaluation shows that this solution outperforms other approached.
Not Enough Data? Deep Learning to the Rescue!
Nov 27, 2019
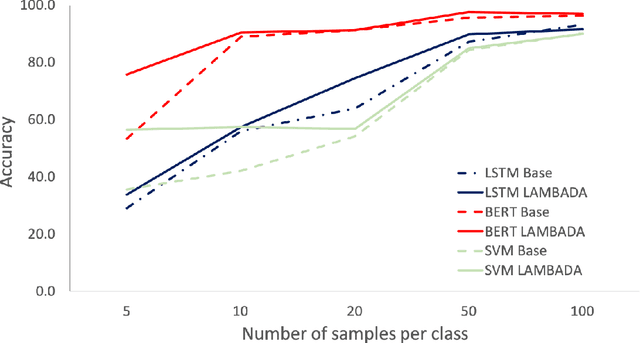

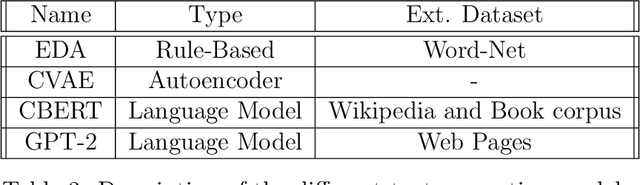
Based on recent advances in natural language modeling and those in text generation capabilities, we propose a novel data augmentation method for text classification tasks. We use a powerful pre-trained neural network model to artificially synthesize new labeled data for supervised learning. We mainly focus on cases with scarce labeled data. Our method, referred to as language-model-based data augmentation (LAMBADA), involves fine-tuning a state-of-the-art language generator to a specific task through an initial training phase on the existing (usually small) labeled data. Using the fine-tuned model and given a class label, new sentences for the class are generated. Our process then filters these new sentences by using a classifier trained on the original data. In a series of experiments, we show that LAMBADA improves classifiers' performance on a variety of datasets. Moreover, LAMBADA significantly improves upon the state-of-the-art techniques for data augmentation, specifically those applicable to text classification tasks with little data.