 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAlterbute: Editing Intrinsic Attributes of Objects in Images
Jan 15, 2026We introduce Alterbute, a diffusion-based method for editing an object's intrinsic attributes in an image. We allow changing color, texture, material, and even the shape of an object, while preserving its perceived identity and scene context. Existing approaches either rely on unsupervised priors that often fail to preserve identity or use overly restrictive supervision that prevents meaningful intrinsic variations. Our method relies on: (i) a relaxed training objective that allows the model to change both intrinsic and extrinsic attributes conditioned on an identity reference image, a textual prompt describing the target intrinsic attributes, and a background image and object mask defining the extrinsic context. At inference, we restrict extrinsic changes by reusing the original background and object mask, thereby ensuring that only the desired intrinsic attributes are altered; (ii) Visual Named Entities (VNEs) - fine-grained visual identity categories (e.g., ''Porsche 911 Carrera'') that group objects sharing identity-defining features while allowing variation in intrinsic attributes. We use a vision-language model to automatically extract VNE labels and intrinsic attribute descriptions from a large public image dataset, enabling scalable, identity-preserving supervision. Alterbute outperforms existing methods on identity-preserving object intrinsic attribute editing.
Real-Time Deepfake Detection in the Real-World
Jun 13, 2024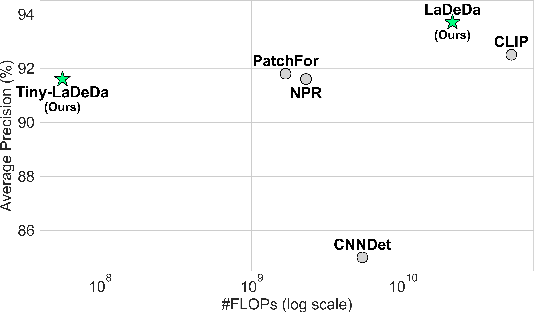
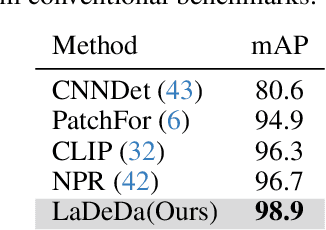
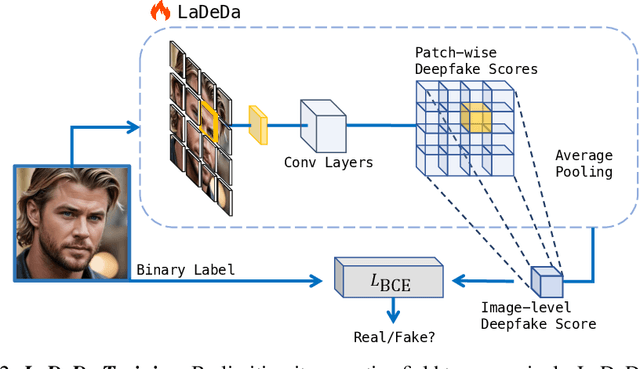
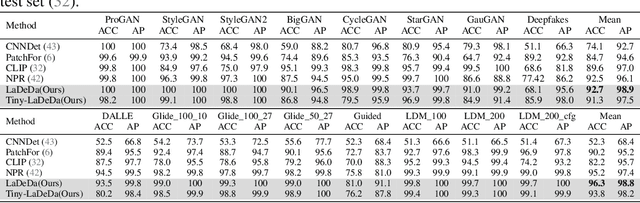
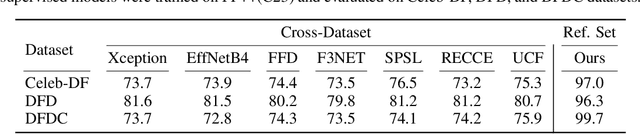
Recent improvements in generative AI made synthesizing fake images easy; as they can be used to cause harm, it is crucial to develop accurate techniques to identify them. This paper introduces "Locally Aware Deepfake Detection Algorithm" (LaDeDa), that accepts a single 9x9 image patch and outputs its deepfake score. The image deepfake score is the pooled score of its patches. With merely patch-level information, LaDeDa significantly improves over the state-of-the-art, achieving around 99% mAP on current benchmarks. Owing to the patch-level structure of LaDeDa, we hypothesize that the generation artifacts can be detected by a simple model. We therefore distill LaDeDa into Tiny-LaDeDa, a highly efficient model consisting of only 4 convolutional layers. Remarkably, Tiny-LaDeDa has 375x fewer FLOPs and is 10,000x more parameter-efficient than LaDeDa, allowing it to run efficiently on edge devices with a minor decrease in accuracy. These almost-perfect scores raise the question: is the task of deepfake detection close to being solved? Perhaps surprisingly, our investigation reveals that current training protocols prevent methods from generalizing to real-world deepfakes extracted from social media. To address this issue, we introduce WildRF, a new deepfake detection dataset curated from several popular social networks. Our method achieves the top performance of 93.7% mAP on WildRF, however the large gap from perfect accuracy shows that reliable real-world deepfake detection is still unsolved.
From Zero to Hero: Cold-Start Anomaly Detection
May 30, 2024



When first deploying an anomaly detection system, e.g., to detect out-of-scope queries in chatbots, there are no observed data, making data-driven approaches ineffective. Zero-shot anomaly detection methods offer a solution to such "cold-start" cases, but unfortunately they are often not accurate enough. This paper studies the realistic but underexplored cold-start setting where an anomaly detection model is initialized using zero-shot guidance, but subsequently receives a small number of contaminated observations (namely, that may include anomalies). The goal is to make efficient use of both the zero-shot guidance and the observations. We propose ColdFusion, a method that effectively adapts the zero-shot anomaly detector to contaminated observations. To support future development of this new setting, we propose an evaluation suite consisting of evaluation protocols and metrics.
Detecting Deepfakes Without Seeing Any
Nov 02, 2023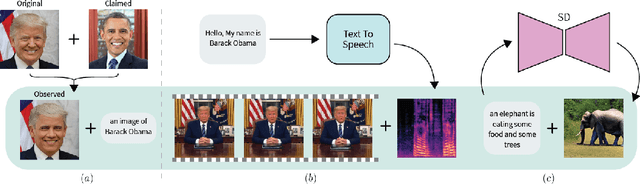

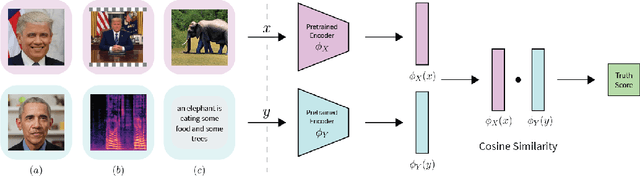
Deepfake attacks, malicious manipulation of media containing people, are a serious concern for society. Conventional deepfake detection methods train supervised classifiers to distinguish real media from previously encountered deepfakes. Such techniques can only detect deepfakes similar to those previously seen, but not zero-day (previously unseen) attack types. As current deepfake generation techniques are changing at a breathtaking pace, new attack types are proposed frequently, making this a major issue. Our main observations are that: i) in many effective deepfake attacks, the fake media must be accompanied by false facts i.e. claims about the identity, speech, motion, or appearance of the person. For instance, when impersonating Obama, the attacker explicitly or implicitly claims that the fake media show Obama; ii) current generative techniques cannot perfectly synthesize the false facts claimed by the attacker. We therefore introduce the concept of "fact checking", adapted from fake news detection, for detecting zero-day deepfake attacks. Fact checking verifies that the claimed facts (e.g. identity is Obama), agree with the observed media (e.g. is the face really Obama's?), and thus can differentiate between real and fake media. Consequently, we introduce FACTOR, a practical recipe for deepfake fact checking and demonstrate its power in critical attack settings: face swapping and audio-visual synthesis. Although it is training-free, relies exclusively on off-the-shelf features, is very easy to implement, and does not see any deepfakes, it achieves better than state-of-the-art accuracy.
Efficient Discovery and Effective Evaluation of Visual Perceptual Similarity: A Benchmark and Beyond
Aug 28, 2023

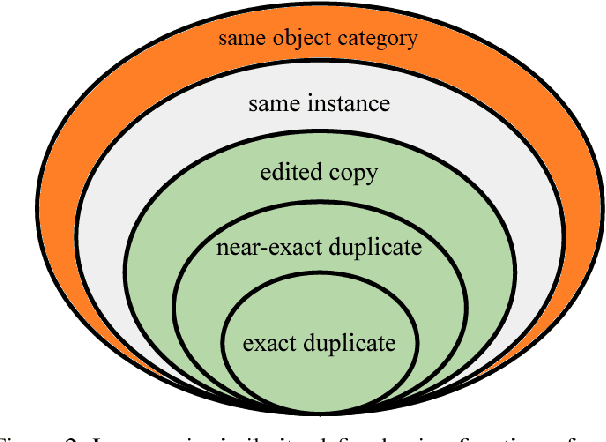
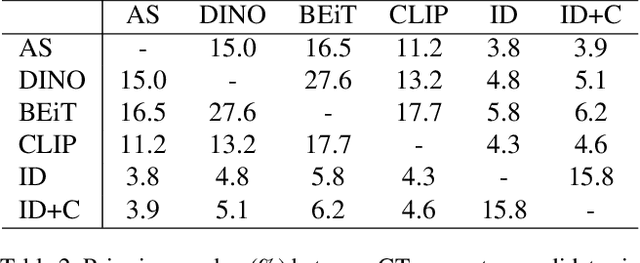
Visual similarities discovery (VSD) is an important task with broad e-commerce applications. Given an image of a certain object, the goal of VSD is to retrieve images of different objects with high perceptual visual similarity. Although being a highly addressed problem, the evaluation of proposed methods for VSD is often based on a proxy of an identification-retrieval task, evaluating the ability of a model to retrieve different images of the same object. We posit that evaluating VSD methods based on identification tasks is limited, and faithful evaluation must rely on expert annotations. In this paper, we introduce the first large-scale fashion visual similarity benchmark dataset, consisting of more than 110K expert-annotated image pairs. Besides this major contribution, we share insight from the challenges we faced while curating this dataset. Based on these insights, we propose a novel and efficient labeling procedure that can be applied to any dataset. Our analysis examines its limitations and inductive biases, and based on these findings, we propose metrics to mitigate those limitations. Though our primary focus lies on visual similarity, the methodologies we present have broader applications for discovering and evaluating perceptual similarity across various domains.
No Free Lunch: The Hazards of Over-Expressive Representations in Anomaly Detection
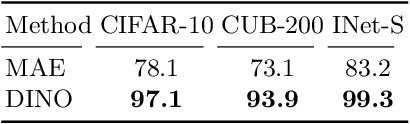
Jun 12, 2023Anomaly detection methods, powered by deep learning, have recently been making significant progress, mostly due to improved representations. It is tempting to hypothesize that anomaly detection can improve indefinitely by increasing the scale of our networks, making their representations more expressive. In this paper, we provide theoretical and empirical evidence to the contrary. In fact, we empirically show cases where very expressive representations fail to detect even simple anomalies when evaluated beyond the well-studied object-centric datasets. To investigate this phenomenon, we begin by introducing a novel theoretical toy model for anomaly detection performance. The model uncovers a fundamental trade-off between representation sufficiency and over-expressivity. It provides evidence for a no-free-lunch theorem in anomaly detection stating that increasing representation expressivity will eventually result in performance degradation. Instead, guidance must be provided to focus the representation on the attributes relevant to the anomalies of interest. We conduct an extensive empirical investigation demonstrating that state-of-the-art representations often suffer from over-expressivity, failing to detect many types of anomalies. Our investigation demonstrates how this over-expressivity impairs image anomaly detection in practical settings. We conclude with future directions for mitigating this issue.
Attribute-based Representations for Accurate and Interpretable Video Anomaly Detection
Dec 01, 2022



Video anomaly detection (VAD) is a challenging computer vision task with many practical applications. As anomalies are inherently ambiguous, it is essential for users to understand the reasoning behind a system's decision in order to determine if the rationale is sound. In this paper, we propose a simple but highly effective method that pushes the boundaries of VAD accuracy and interpretability using attribute-based representations. Our method represents every object by its velocity and pose. The anomaly scores are computed using a density-based approach. Surprisingly, we find that this simple representation is sufficient to achieve state-of-the-art performance in ShanghaiTech, the largest and most complex VAD dataset. Combining our interpretable attribute-based representations with implicit, deep representation yields state-of-the-art performance with a $99.1\%, 93.3\%$, and $85.9\%$ AUROC on Ped2, Avenue, and ShanghaiTech, respectively. Our method is accurate, interpretable, and easy to implement.
Anomaly Detection Requires Better Representations
Oct 19, 2022


Anomaly detection seeks to identify unusual phenomena, a central task in science and industry. The task is inherently unsupervised as anomalies are unexpected and unknown during training. Recent advances in self-supervised representation learning have directly driven improvements in anomaly detection. In this position paper, we first explain how self-supervised representations can be easily used to achieve state-of-the-art performance in commonly reported anomaly detection benchmarks. We then argue that tackling the next generation of anomaly detection tasks requires new technical and conceptual improvements in representation learning.
Mean-Shifted Contrastive Loss for Anomaly Detection
Jun 07, 2021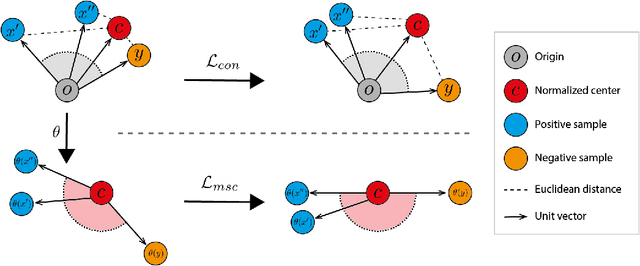
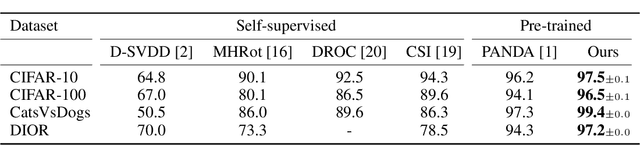
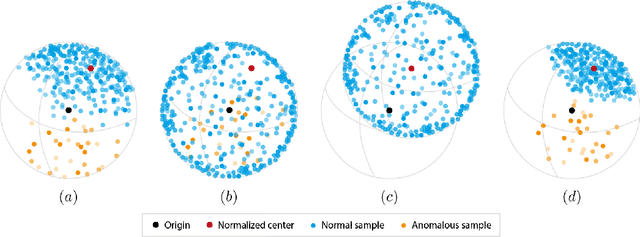
Deep anomaly detection methods learn representations that separate between normal and anomalous samples. Very effective representations are obtained when powerful externally trained feature extractors (e.g. ResNets pre-trained on ImageNet) are fine-tuned on the training data which consists of normal samples and no anomalies. However, this is a difficult task that can suffer from catastrophic collapse, i.e. it is prone to learning trivial and non-specific features. In this paper, we propose a new loss function which can overcome failure modes of both center-loss and contrastive-loss methods. Furthermore, we combine it with a confidence-invariant angular center loss, which replaces the Euclidean distance used in previous work, that was sensitive to prediction confidence. Our improvements yield a new anomaly detection approach, based on $\textit{Mean-Shifted Contrastive Loss}$, which is both more accurate and less sensitive to catastrophic collapse than previous methods. Our method achieves state-of-the-art anomaly detection performance on multiple benchmarks including $97.5\%$ ROC-AUC on the CIFAR-10 dataset.
PANDA -- Adapting Pretrained Features for Anomaly Detection
Oct 12, 2020
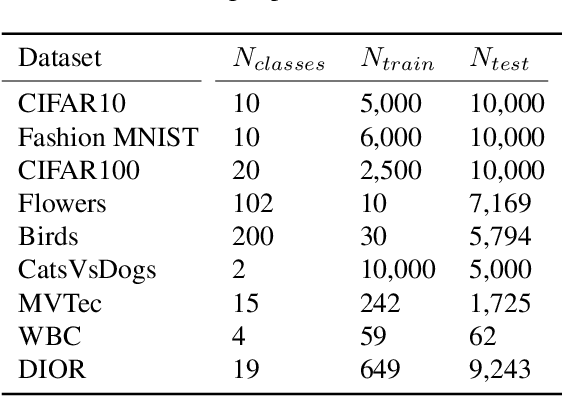
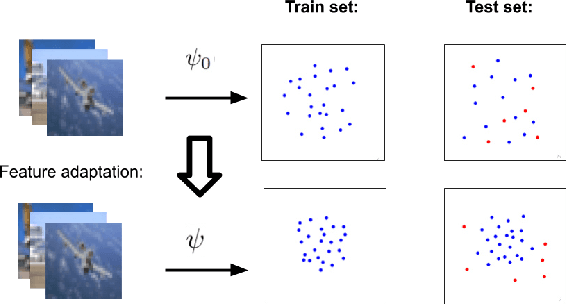
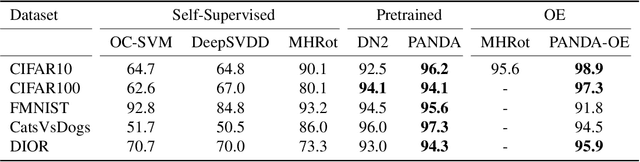
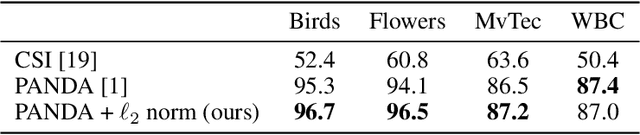
Anomaly detection methods require high-quality features. One way of obtaining strong features is to adapt pre-trained features to anomaly detection on the target distribution. Unfortunately, simple adaptation methods often result in catastrophic collapse (feature deterioration) and reduce performance. DeepSVDD combats collapse by removing biases from architectures, but this limits the adaptation performance gain. In this work, we propose two methods for combating collapse: i) a variant of early stopping that dynamically learns the stopping iteration ii) elastic regularization inspired by continual learning. In addition, we conduct a thorough investigation of Imagenet-pretrained features for one-class anomaly detection. Our method, PANDA, outperforms the state-of-the-art in the one-class and outlier exposure settings (CIFAR10: 96.2% vs. 90.1% and 98.9% vs. 95.6%).