 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBEE: Metric-Adapted Explanations via Baseline Exploration-Exploitation
Dec 23, 2024



Two prominent challenges in explainability research involve 1) the nuanced evaluation of explanations and 2) the modeling of missing information through baseline representations. The existing literature introduces diverse evaluation metrics, each scrutinizing the quality of explanations through distinct lenses. Additionally, various baseline representations have been proposed, each modeling the notion of missingness differently. Yet, a consensus on the ultimate evaluation metric and baseline representation remains elusive. This work acknowledges the diversity in explanation metrics and baselines, demonstrating that different metrics exhibit preferences for distinct explanation maps resulting from the utilization of different baseline representations and distributions. To address the diversity in metrics and accommodate the variety of baseline representations in a unified manner, we propose Baseline Exploration-Exploitation (BEE) - a path-integration method that introduces randomness to the integration process by modeling the baseline as a learned random tensor. This tensor follows a learned mixture of baseline distributions optimized through a contextual exploration-exploitation procedure to enhance performance on the specific metric of interest. By resampling the baseline from the learned distribution, BEE generates a comprehensive set of explanation maps, facilitating the selection of the best-performing explanation map in this broad set for the given metric. Extensive evaluations across various model architectures showcase the superior performance of BEE in comparison to state-of-the-art explanation methods on a variety of objective evaluation metrics.
In Search of Truth: An Interrogation Approach to Hallucination Detection
Mar 05, 2024



Despite the many advances of Large Language Models (LLMs) and their unprecedented rapid evolution, their impact and integration into every facet of our daily lives is limited due to various reasons. One critical factor hindering their widespread adoption is the occurrence of hallucinations, where LLMs invent answers that sound realistic, yet drift away from factual truth. In this paper, we present a novel method for detecting hallucinations in large language models, which tackles a critical issue in the adoption of these models in various real-world scenarios. Through extensive evaluations across multiple datasets and LLMs, including Llama-2, we study the hallucination levels of various recent LLMs and demonstrate the effectiveness of our method to automatically detect them. Notably, we observe up to 62% hallucinations for Llama-2 in a specific experiment, where our method achieves a Balanced Accuracy (B-ACC) of 87%, all without relying on external knowledge.
Deep Integrated Explanations
Oct 28, 2023



This paper presents Deep Integrated Explanations (DIX) - a universal method for explaining vision models. DIX generates explanation maps by integrating information from the intermediate representations of the model, coupled with their corresponding gradients. Through an extensive array of both objective and subjective evaluations spanning diverse tasks, datasets, and model configurations, we showcase the efficacy of DIX in generating faithful and accurate explanation maps, while surpassing current state-of-the-art methods.
Efficient Discovery and Effective Evaluation of Visual Perceptual Similarity: A Benchmark and Beyond
Aug 28, 2023

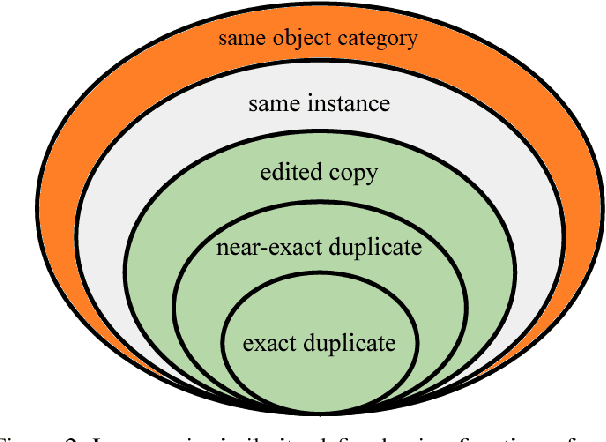
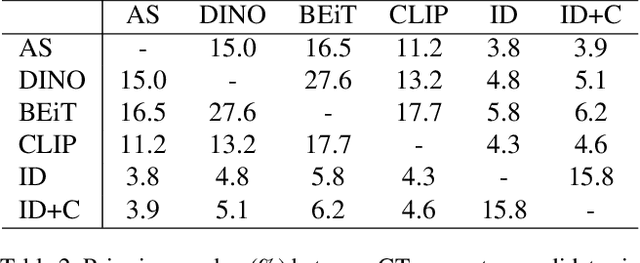
Visual similarities discovery (VSD) is an important task with broad e-commerce applications. Given an image of a certain object, the goal of VSD is to retrieve images of different objects with high perceptual visual similarity. Although being a highly addressed problem, the evaluation of proposed methods for VSD is often based on a proxy of an identification-retrieval task, evaluating the ability of a model to retrieve different images of the same object. We posit that evaluating VSD methods based on identification tasks is limited, and faithful evaluation must rely on expert annotations. In this paper, we introduce the first large-scale fashion visual similarity benchmark dataset, consisting of more than 110K expert-annotated image pairs. Besides this major contribution, we share insight from the challenges we faced while curating this dataset. Based on these insights, we propose a novel and efficient labeling procedure that can be applied to any dataset. Our analysis examines its limitations and inductive biases, and based on these findings, we propose metrics to mitigate those limitations. Though our primary focus lies on visual similarity, the methodologies we present have broader applications for discovering and evaluating perceptual similarity across various domains.
Representation Learning via Variational Bayesian Networks
Jun 28, 2023



We present Variational Bayesian Network (VBN) - a novel Bayesian entity representation learning model that utilizes hierarchical and relational side information and is particularly useful for modeling entities in the ``long-tail'', where the data is scarce. VBN provides better modeling for long-tail entities via two complementary mechanisms: First, VBN employs informative hierarchical priors that enable information propagation between entities sharing common ancestors. Additionally, VBN models explicit relations between entities that enforce complementary structure and consistency, guiding the learned representations towards a more meaningful arrangement in space. Second, VBN represents entities by densities (rather than vectors), hence modeling uncertainty that plays a complementary role in coping with data scarcity. Finally, we propose a scalable Variational Bayes optimization algorithm that enables fast approximate Bayesian inference. We evaluate the effectiveness of VBN on linguistic, recommendations, and medical inference tasks. Our findings show that VBN outperforms other existing methods across multiple datasets, and especially in the long-tail.
Interpreting BERT-based Text Similarity via Activation and Saliency Maps
Aug 13, 2022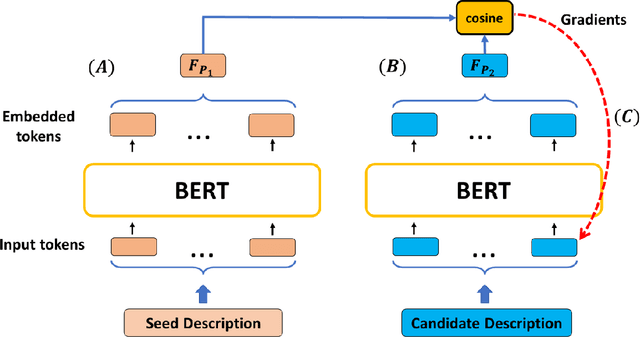
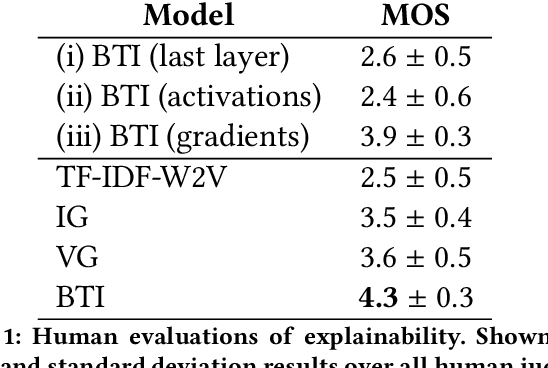
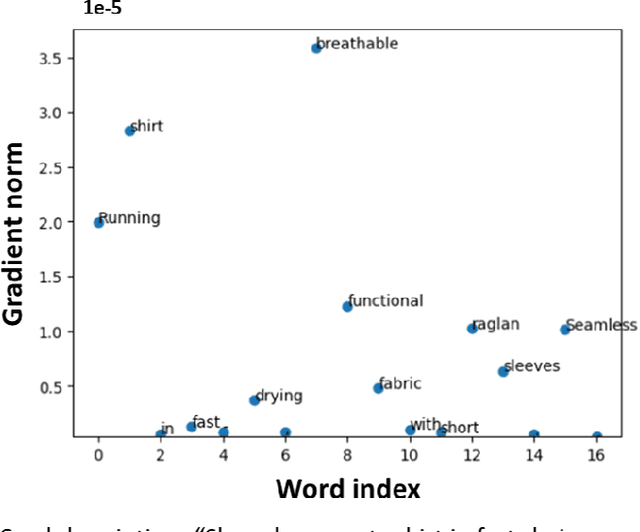
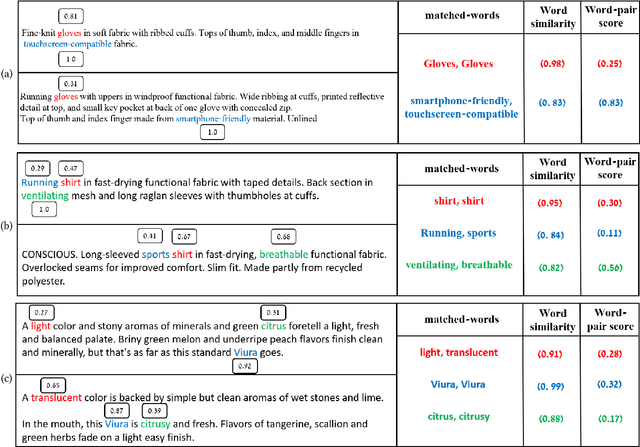
Recently, there has been growing interest in the ability of Transformer-based models to produce meaningful embeddings of text with several applications, such as text similarity. Despite significant progress in the field, the explanations for similarity predictions remain challenging, especially in unsupervised settings. In this work, we present an unsupervised technique for explaining paragraph similarities inferred by pre-trained BERT models. By looking at a pair of paragraphs, our technique identifies important words that dictate each paragraph's semantics, matches between the words in both paragraphs, and retrieves the most important pairs that explain the similarity between the two. The method, which has been assessed by extensive human evaluations and demonstrated on datasets comprising long and complex paragraphs, has shown great promise, providing accurate interpretations that correlate better with human perceptions.
Cold Item Integration in Deep Hybrid Recommenders via Tunable Stochastic Gates
Dec 12, 2021
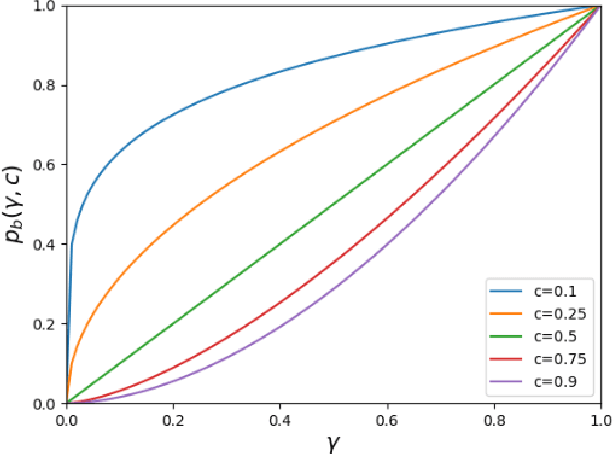
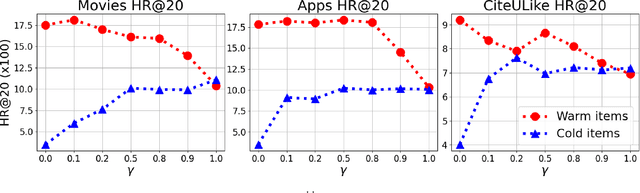
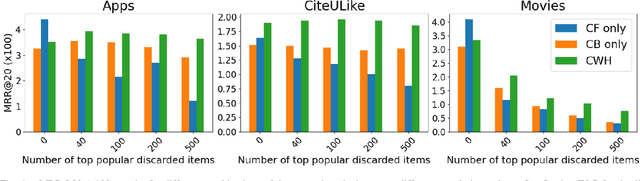
A major challenge in collaborative filtering methods is how to produce recommendations for cold items (items with no ratings), or integrate cold item into an existing catalog. Over the years, a variety of hybrid recommendation models have been proposed to address this problem by utilizing items' metadata and content along with their ratings or usage patterns. In this work, we wish to revisit the cold start problem in order to draw attention to an overlooked challenge: the ability to integrate and balance between (regular) warm items and completely cold items. In this case, two different challenges arise: (1) preserving high quality performance on warm items, while (2) learning to promote cold items to relevant users. First, we show that these two objectives are in fact conflicting, and the balance between them depends on the business needs and the application at hand. Next, we propose a novel hybrid recommendation algorithm that bridges these two conflicting objectives and enables a harmonized balance between preserving high accuracy for warm items while effectively promoting completely cold items. We demonstrate the effectiveness of the proposed algorithm on movies, apps, and articles recommendations, and provide an empirical analysis of the cold-warm trade-off.
Gaussian Process Regression for Out-of-Sample Extension
Jun 05, 2016



Manifold learning methods are useful for high dimensional data analysis. Many of the existing methods produce a low dimensional representation that attempts to describe the intrinsic geometric structure of the original data. Typically, this process is computationally expensive and the produced embedding is limited to the training data. In many real life scenarios, the ability to produce embedding of unseen samples is essential. In this paper we propose a Bayesian non-parametric approach for out-of-sample extension. The method is based on Gaussian Process Regression and independent of the manifold learning algorithm. Additionally, the method naturally provides a measure for the degree of abnormality for a newly arrived data point that did not participate in the training process. We derive the mathematical connection between the proposed method and the Nystrom extension and show that the latter is a special case of the former. We present extensive experimental results that demonstrate the performance of the proposed method and compare it to other existing out-of-sample extension methods.