 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRepresentation Learning via Variational Bayesian Networks
Jun 28, 2023



We present Variational Bayesian Network (VBN) - a novel Bayesian entity representation learning model that utilizes hierarchical and relational side information and is particularly useful for modeling entities in the ``long-tail'', where the data is scarce. VBN provides better modeling for long-tail entities via two complementary mechanisms: First, VBN employs informative hierarchical priors that enable information propagation between entities sharing common ancestors. Additionally, VBN models explicit relations between entities that enforce complementary structure and consistency, guiding the learned representations towards a more meaningful arrangement in space. Second, VBN represents entities by densities (rather than vectors), hence modeling uncertainty that plays a complementary role in coping with data scarcity. Finally, we propose a scalable Variational Bayes optimization algorithm that enables fast approximate Bayesian inference. We evaluate the effectiveness of VBN on linguistic, recommendations, and medical inference tasks. Our findings show that VBN outperforms other existing methods across multiple datasets, and especially in the long-tail.
On the Evolution of Word Order
Jan 23, 2021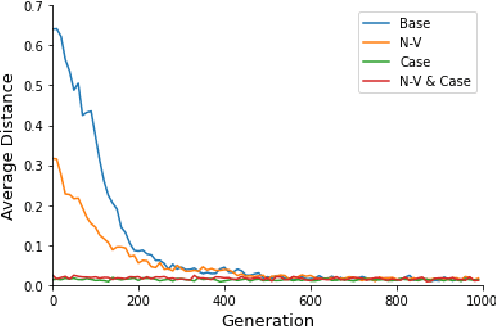
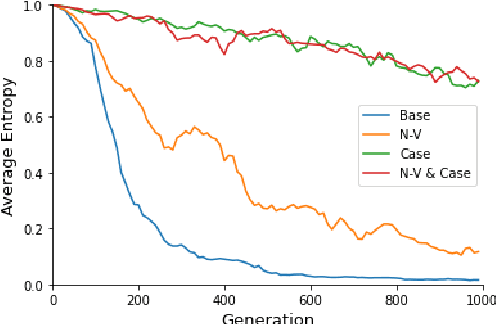
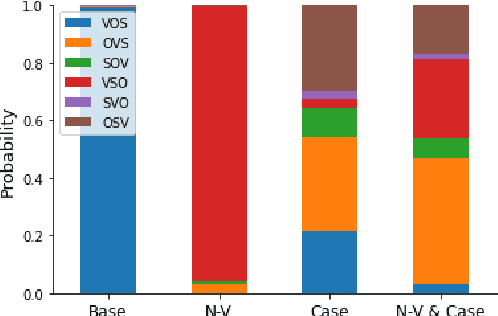
Most natural languages have a predominant or fixed word order. For example, in English, the word order used most often is Subject-Verb-Object. This work attempts to explain this phenomena as well as other typological findings regarding word order from a functional perspective. That is, we target the question of whether fixed word order gives a functional advantage, that may explain why these languages are common. To this end, we consider an evolutionary model of language and show, both theoretically and using a genetic algorithm-based simulation, that an optimal language is one with fixed word order. We also show that adding information to the sentence, such as case markers and noun-verb distinction, reduces the need for fixed word order, in accordance with the typological findings.
Bayesian Hierarchical Words Representation Learning
Apr 12, 2020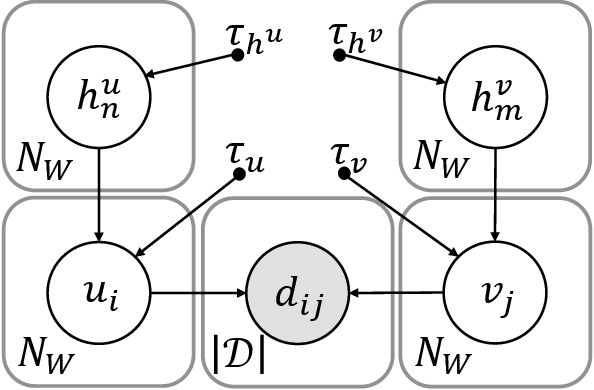

This paper presents the Bayesian Hierarchical Words Representation (BHWR) learning algorithm. BHWR facilitates Variational Bayes word representation learning combined with semantic taxonomy modeling via hierarchical priors. By propagating relevant information between related words, BHWR utilizes the taxonomy to improve the quality of such representations. Evaluation of several linguistic datasets demonstrates the advantages of BHWR over suitable alternatives that facilitate Bayesian modeling with or without semantic priors. Finally, we further show that BHWR produces better representations for rare words.
Combinatorial Bandits with Full-Bandit Feedback: Sample Complexity and Regret Minimization
May 28, 2019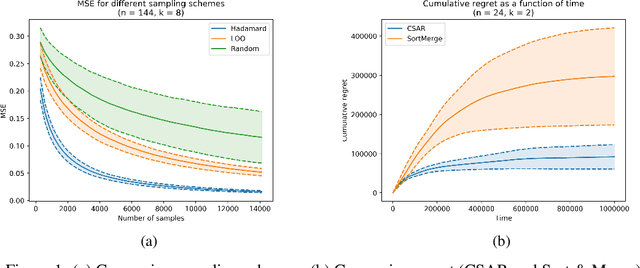
Combinatorial Bandits generalize multi-armed bandits, where k out of n arms are chosen at each round and the sum of the rewards is gained. We address the full-bandit feedback, in which the agent observes only the sum of rewards, in contrast to the semi-bandit feedback, in which the agent observes also the individual arms' rewards. We present the Combinatorial Successive Accepts and Rejects (CSAR) algorithm, which is a generalization of the SAR algorithm (Bubeck et al. 2013) for the combinatorial setting. Our main contribution is an efficient sampling scheme that uses Hadamard matrices in order to estimate accurately the individual arms' expected rewards. We discuss two variants of the algorithm, the first minimizes the sample complexity and the second minimizes the regret. For the sample complexity we also prove a matching lower bound that shows it is optimal. For the regret minimization, we prove a lower bound which is tight up to a factor of k. Finally, we run experiments and show that our algorithm outperforms other methods.
Inducing Regular Grammars Using Recurrent Neural Networks
Jun 26, 2018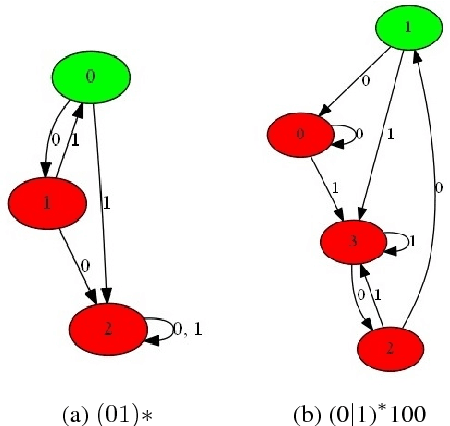
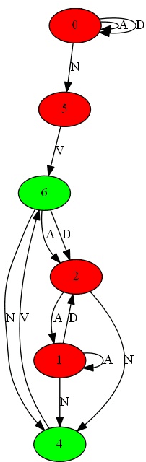

Grammar induction is the task of learning a grammar from a set of examples. Recently, neural networks have been shown to be powerful learning machines that can identify patterns in streams of data. In this work we investigate their effectiveness in inducing a regular grammar from data, without any assumptions about the grammar. We train a recurrent neural network to distinguish between strings that are in or outside a regular language, and utilize an algorithm for extracting the learned finite-state automaton. We apply this method to several regular languages and find unexpected results regarding the connections between the network's states that may be regarded as evidence for generalization.