 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIn Search of Truth: An Interrogation Approach to Hallucination Detection
Mar 05, 2024



Despite the many advances of Large Language Models (LLMs) and their unprecedented rapid evolution, their impact and integration into every facet of our daily lives is limited due to various reasons. One critical factor hindering their widespread adoption is the occurrence of hallucinations, where LLMs invent answers that sound realistic, yet drift away from factual truth. In this paper, we present a novel method for detecting hallucinations in large language models, which tackles a critical issue in the adoption of these models in various real-world scenarios. Through extensive evaluations across multiple datasets and LLMs, including Llama-2, we study the hallucination levels of various recent LLMs and demonstrate the effectiveness of our method to automatically detect them. Notably, we observe up to 62% hallucinations for Llama-2 in a specific experiment, where our method achieves a Balanced Accuracy (B-ACC) of 87%, all without relying on external knowledge.
Efficient Discovery and Effective Evaluation of Visual Perceptual Similarity: A Benchmark and Beyond
Aug 28, 2023

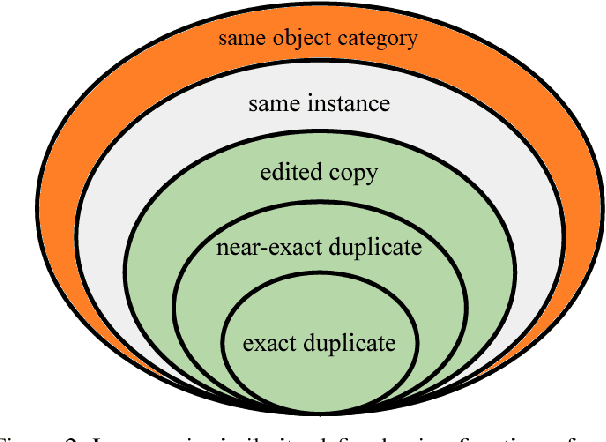
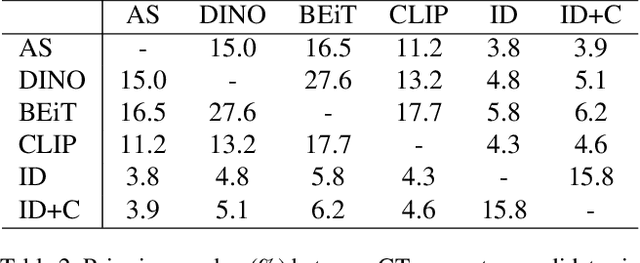
Visual similarities discovery (VSD) is an important task with broad e-commerce applications. Given an image of a certain object, the goal of VSD is to retrieve images of different objects with high perceptual visual similarity. Although being a highly addressed problem, the evaluation of proposed methods for VSD is often based on a proxy of an identification-retrieval task, evaluating the ability of a model to retrieve different images of the same object. We posit that evaluating VSD methods based on identification tasks is limited, and faithful evaluation must rely on expert annotations. In this paper, we introduce the first large-scale fashion visual similarity benchmark dataset, consisting of more than 110K expert-annotated image pairs. Besides this major contribution, we share insight from the challenges we faced while curating this dataset. Based on these insights, we propose a novel and efficient labeling procedure that can be applied to any dataset. Our analysis examines its limitations and inductive biases, and based on these findings, we propose metrics to mitigate those limitations. Though our primary focus lies on visual similarity, the methodologies we present have broader applications for discovering and evaluating perceptual similarity across various domains.
Representation Learning via Variational Bayesian Networks
Jun 28, 2023



We present Variational Bayesian Network (VBN) - a novel Bayesian entity representation learning model that utilizes hierarchical and relational side information and is particularly useful for modeling entities in the ``long-tail'', where the data is scarce. VBN provides better modeling for long-tail entities via two complementary mechanisms: First, VBN employs informative hierarchical priors that enable information propagation between entities sharing common ancestors. Additionally, VBN models explicit relations between entities that enforce complementary structure and consistency, guiding the learned representations towards a more meaningful arrangement in space. Second, VBN represents entities by densities (rather than vectors), hence modeling uncertainty that plays a complementary role in coping with data scarcity. Finally, we propose a scalable Variational Bayes optimization algorithm that enables fast approximate Bayesian inference. We evaluate the effectiveness of VBN on linguistic, recommendations, and medical inference tasks. Our findings show that VBN outperforms other existing methods across multiple datasets, and especially in the long-tail.
GPT-Calls: Enhancing Call Segmentation and Tagging by Generating Synthetic Conversations via Large Language Models
Jun 09, 2023



Transcriptions of phone calls are of significant value across diverse fields, such as sales, customer service, healthcare, and law enforcement. Nevertheless, the analysis of these recorded conversations can be an arduous and time-intensive process, especially when dealing with extended or multifaceted dialogues. In this work, we propose a novel method, GPT-distilled Calls Segmentation and Tagging (GPT-Calls), for efficient and accurate call segmentation and topic extraction. GPT-Calls is composed of offline and online phases. The offline phase is applied once to a given list of topics and involves generating a distribution of synthetic sentences for each topic using a GPT model and extracting anchor vectors. The online phase is applied to every call separately and scores the similarity between the transcripted conversation and the topic anchors found in the offline phase. Then, time domain analysis is applied to the similarity scores to group utterances into segments and tag them with topics. The proposed paradigm provides an accurate and efficient method for call segmentation and topic extraction that does not require labeled data, thus making it a versatile approach applicable to various domains. Our algorithm operates in production under Dynamics 365 Sales Conversation Intelligence, and our research is based on real sales conversations gathered from various Dynamics 365 Sales tenants.
Interpreting BERT-based Text Similarity via Activation and Saliency Maps
Aug 13, 2022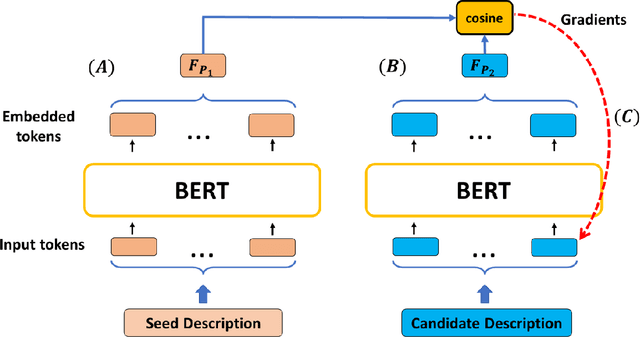
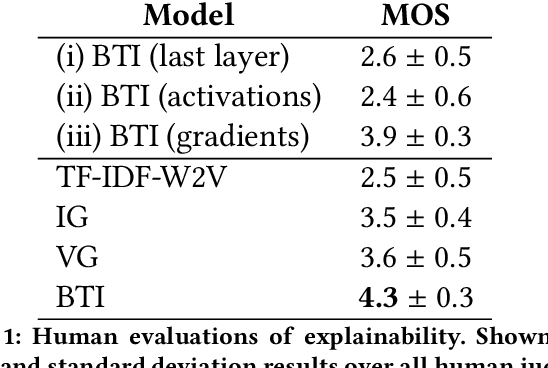
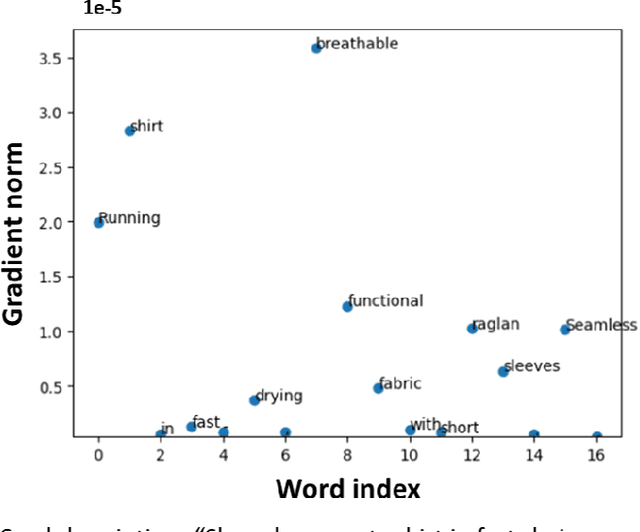
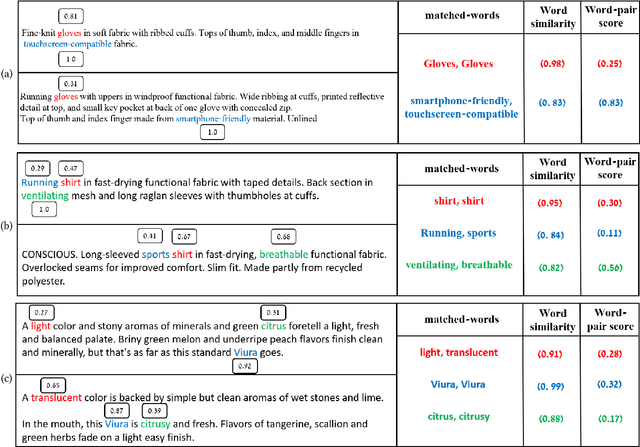
Recently, there has been growing interest in the ability of Transformer-based models to produce meaningful embeddings of text with several applications, such as text similarity. Despite significant progress in the field, the explanations for similarity predictions remain challenging, especially in unsupervised settings. In this work, we present an unsupervised technique for explaining paragraph similarities inferred by pre-trained BERT models. By looking at a pair of paragraphs, our technique identifies important words that dictate each paragraph's semantics, matches between the words in both paragraphs, and retrieves the most important pairs that explain the similarity between the two. The method, which has been assessed by extensive human evaluations and demonstrated on datasets comprising long and complex paragraphs, has shown great promise, providing accurate interpretations that correlate better with human perceptions.
MetricBERT: Text Representation Learning via Self-Supervised Triplet Training
Aug 13, 2022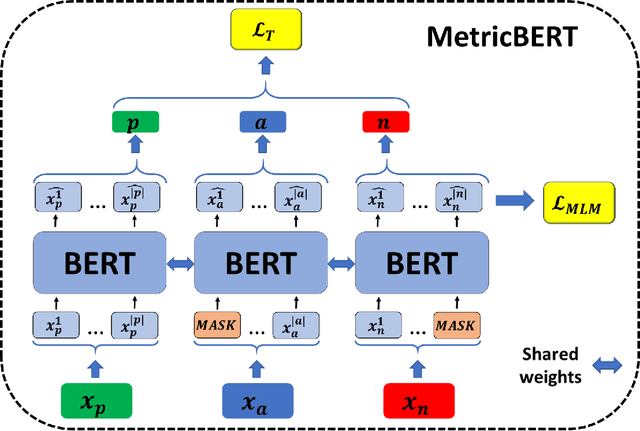

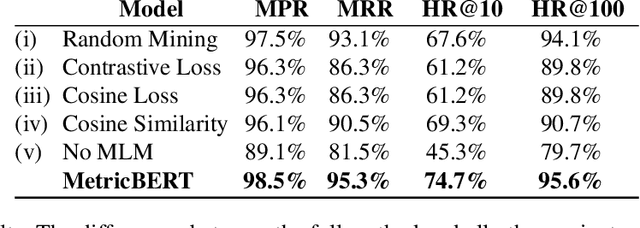
We present MetricBERT, a BERT-based model that learns to embed text under a well-defined similarity metric while simultaneously adhering to the ``traditional'' masked-language task. We focus on downstream tasks of learning similarities for recommendations where we show that MetricBERT outperforms state-of-the-art alternatives, sometimes by a substantial margin. We conduct extensive evaluations of our method and its different variants, showing that our training objective is highly beneficial over a traditional contrastive loss, a standard cosine similarity objective, and six other baselines. As an additional contribution, we publish a dataset of video games descriptions along with a test set of similarity annotations crafted by a domain expert.
Grad-SAM: Explaining Transformers via Gradient Self-Attention Maps
Apr 23, 2022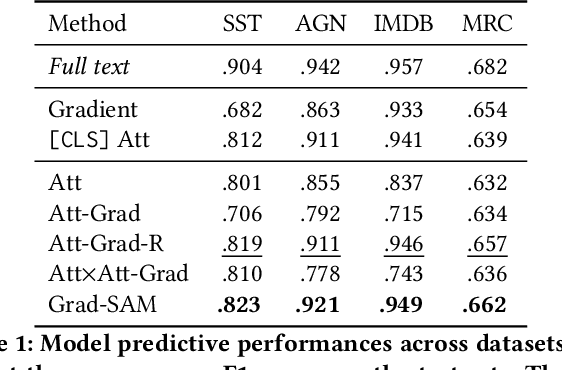
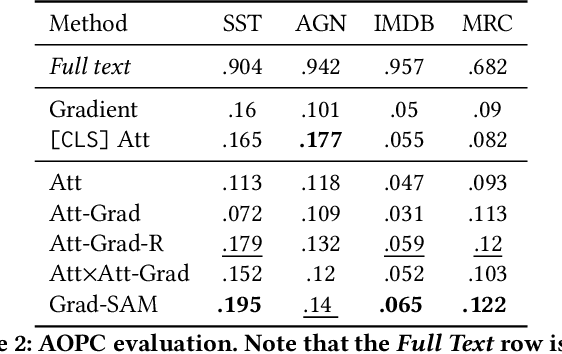

Transformer-based language models significantly advanced the state-of-the-art in many linguistic tasks. As this revolution continues, the ability to explain model predictions has become a major area of interest for the NLP community. In this work, we present Gradient Self-Attention Maps (Grad-SAM) - a novel gradient-based method that analyzes self-attention units and identifies the input elements that explain the model's prediction the best. Extensive evaluations on various benchmarks show that Grad-SAM obtains significant improvements over state-of-the-art alternatives.
Pre-training and Fine-tuning Transformers for fMRI Prediction Tasks
Dec 10, 2021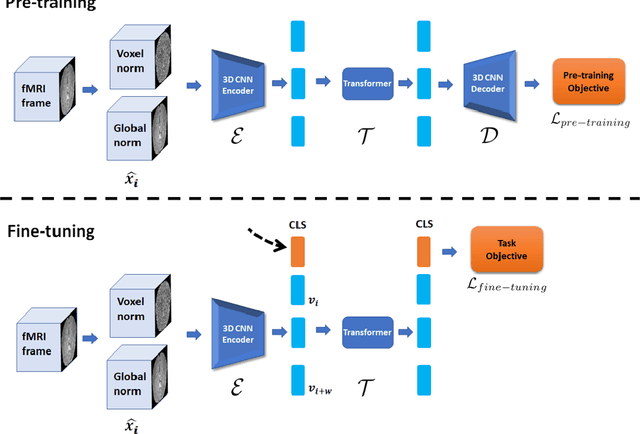
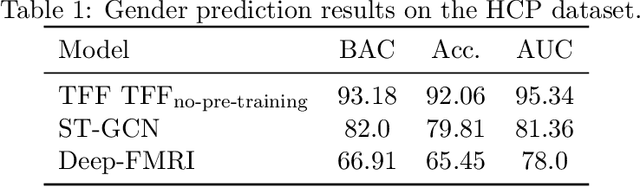
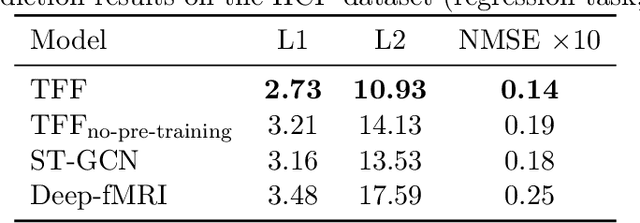
We present the TFF Transformer framework for the analysis of functional Magnetic Resonance Imaging (fMRI) data. TFF employs a transformer-based architecture and a two-phase training approach. First, self-supervised training is applied to a collection of fMRI scans, where the model is trained for the reconstruction of 3D volume data. Second, the pre-trained model is fine-tuned on specific tasks, utilizing ground truth labels. Our results show state-of-the-art performance on a variety of fMRI tasks, including age and gender prediction, as well as schizophrenia recognition.
Caption Enriched Samples for Improving Hateful Memes Detection
Sep 22, 2021
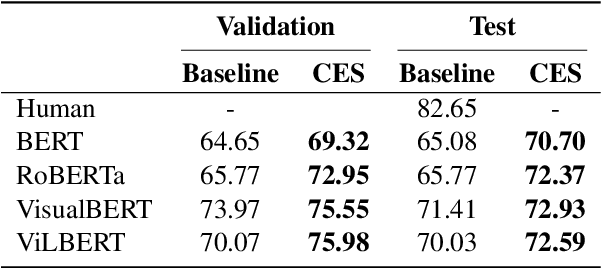

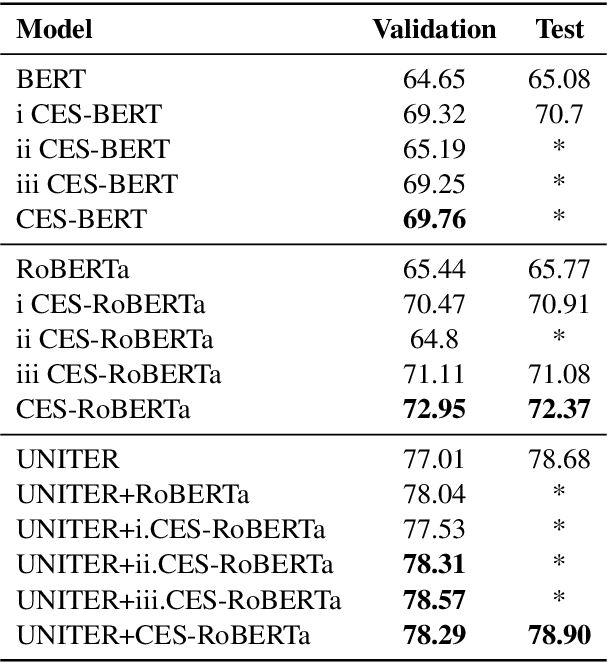
The recently introduced hateful meme challenge demonstrates the difficulty of determining whether a meme is hateful or not. Specifically, both unimodal language models and multimodal vision-language models cannot reach the human level of performance. Motivated by the need to model the contrast between the image content and the overlayed text, we suggest applying an off-the-shelf image captioning tool in order to capture the first. We demonstrate that the incorporation of such automatic captions during fine-tuning improves the results for various unimodal and multimodal models. Moreover, in the unimodal case, continuing the pre-training of language models on augmented and original caption pairs, is highly beneficial to the classification accuracy.
GAM: Explainable Visual Similarity and Classification via Gradient Activation Maps
Sep 02, 2021

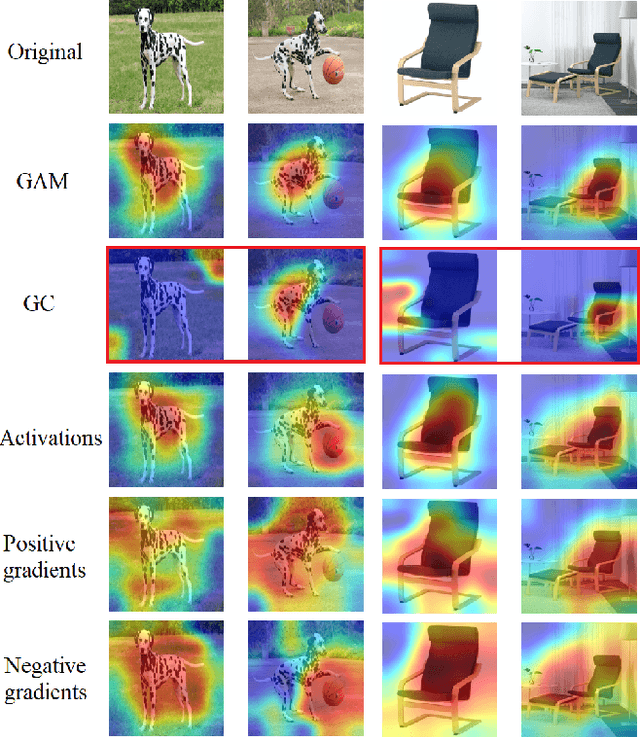

We present Gradient Activation Maps (GAM) - a machinery for explaining predictions made by visual similarity and classification models. By gleaning localized gradient and activation information from multiple network layers, GAM offers improved visual explanations, when compared to existing alternatives. The algorithmic advantages of GAM are explained in detail, and validated empirically, where it is shown that GAM outperforms its alternatives across various tasks and datasets.