 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRethinking Saliency Maps: A Cognitive Human Aligned Taxonomy and Evaluation Framework for Explanations
Nov 18, 2025
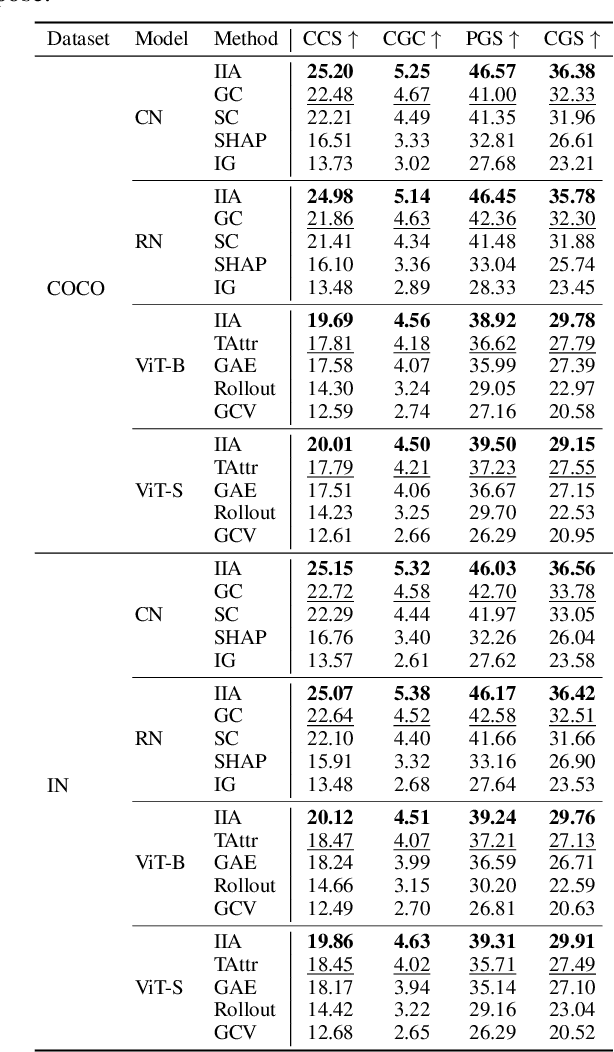


Saliency maps are widely used for visual explanations in deep learning, but a fundamental lack of consensus persists regarding their intended purpose and alignment with diverse user queries. This ambiguity hinders the effective evaluation and practical utility of explanation methods. We address this gap by introducing the Reference-Frame $\times$ Granularity (RFxG) taxonomy, a principled conceptual framework that organizes saliency explanations along two essential axes:Reference-Frame: Distinguishing between pointwise ("Why this prediction?") and contrastive ("Why this and not an alternative?") explanations. Granularity: Ranging from fine-grained class-level (e.g., "Why Husky?") to coarse-grained group-level (e.g., "Why Dog?") interpretations. Using the RFxG lens, we demonstrate critical limitations in existing evaluation metrics, which overwhelmingly prioritize pointwise faithfulness while neglecting contrastive reasoning and semantic granularity. To systematically assess explanation quality across both RFxG dimensions, we propose four novel faithfulness metrics. Our comprehensive evaluation framework applies these metrics to ten state-of-the-art saliency methods, four model architectures, and three datasets. By advocating a shift toward user-intent-driven evaluation, our work provides both the conceptual foundation and the practical tools necessary to develop visual explanations that are not only faithful to the underlying model behavior but are also meaningfully aligned with the complexity of human understanding and inquiry.
BEE: Metric-Adapted Explanations via Baseline Exploration-Exploitation
Dec 23, 2024



Two prominent challenges in explainability research involve 1) the nuanced evaluation of explanations and 2) the modeling of missing information through baseline representations. The existing literature introduces diverse evaluation metrics, each scrutinizing the quality of explanations through distinct lenses. Additionally, various baseline representations have been proposed, each modeling the notion of missingness differently. Yet, a consensus on the ultimate evaluation metric and baseline representation remains elusive. This work acknowledges the diversity in explanation metrics and baselines, demonstrating that different metrics exhibit preferences for distinct explanation maps resulting from the utilization of different baseline representations and distributions. To address the diversity in metrics and accommodate the variety of baseline representations in a unified manner, we propose Baseline Exploration-Exploitation (BEE) - a path-integration method that introduces randomness to the integration process by modeling the baseline as a learned random tensor. This tensor follows a learned mixture of baseline distributions optimized through a contextual exploration-exploitation procedure to enhance performance on the specific metric of interest. By resampling the baseline from the learned distribution, BEE generates a comprehensive set of explanation maps, facilitating the selection of the best-performing explanation map in this broad set for the given metric. Extensive evaluations across various model architectures showcase the superior performance of BEE in comparison to state-of-the-art explanation methods on a variety of objective evaluation metrics.
In Search of Truth: An Interrogation Approach to Hallucination Detection
Mar 05, 2024



Despite the many advances of Large Language Models (LLMs) and their unprecedented rapid evolution, their impact and integration into every facet of our daily lives is limited due to various reasons. One critical factor hindering their widespread adoption is the occurrence of hallucinations, where LLMs invent answers that sound realistic, yet drift away from factual truth. In this paper, we present a novel method for detecting hallucinations in large language models, which tackles a critical issue in the adoption of these models in various real-world scenarios. Through extensive evaluations across multiple datasets and LLMs, including Llama-2, we study the hallucination levels of various recent LLMs and demonstrate the effectiveness of our method to automatically detect them. Notably, we observe up to 62% hallucinations for Llama-2 in a specific experiment, where our method achieves a Balanced Accuracy (B-ACC) of 87%, all without relying on external knowledge.
DiffMoog: a Differentiable Modular Synthesizer for Sound Matching
Jan 23, 2024This paper presents DiffMoog - a differentiable modular synthesizer with a comprehensive set of modules typically found in commercial instruments. Being differentiable, it allows integration into neural networks, enabling automated sound matching, to replicate a given audio input. Notably, DiffMoog facilitates modulation capabilities (FM/AM), low-frequency oscillators (LFOs), filters, envelope shapers, and the ability for users to create custom signal chains. We introduce an open-source platform that comprises DiffMoog and an end-to-end sound matching framework. This framework utilizes a novel signal-chain loss and an encoder network that self-programs its outputs to predict DiffMoogs parameters based on the user-defined modular architecture. Moreover, we provide insights and lessons learned towards sound matching using differentiable synthesis. Combining robust sound capabilities with a holistic platform, DiffMoog stands as a premier asset for expediting research in audio synthesis and machine learning.
Deep Integrated Explanations
Oct 28, 2023



This paper presents Deep Integrated Explanations (DIX) - a universal method for explaining vision models. DIX generates explanation maps by integrating information from the intermediate representations of the model, coupled with their corresponding gradients. Through an extensive array of both objective and subjective evaluations spanning diverse tasks, datasets, and model configurations, we showcase the efficacy of DIX in generating faithful and accurate explanation maps, while surpassing current state-of-the-art methods.
Visual Explanations via Iterated Integrated Attributions
Oct 28, 2023



We introduce Iterated Integrated Attributions (IIA) - a generic method for explaining the predictions of vision models. IIA employs iterative integration across the input image, the internal representations generated by the model, and their gradients, yielding precise and focused explanation maps. We demonstrate the effectiveness of IIA through comprehensive evaluations across various tasks, datasets, and network architectures. Our results showcase that IIA produces accurate explanation maps, outperforming other state-of-the-art explanation techniques.
Learning to Explain: A Model-Agnostic Framework for Explaining Black Box Models
Oct 25, 2023



We present Learning to Explain (LTX), a model-agnostic framework designed for providing post-hoc explanations for vision models. The LTX framework introduces an "explainer" model that generates explanation maps, highlighting the crucial regions that justify the predictions made by the model being explained. To train the explainer, we employ a two-stage process consisting of initial pretraining followed by per-instance finetuning. During both stages of training, we utilize a unique configuration where we compare the explained model's prediction for a masked input with its original prediction for the unmasked input. This approach enables the use of a novel counterfactual objective, which aims to anticipate the model's output using masked versions of the input image. Importantly, the LTX framework is not restricted to a specific model architecture and can provide explanations for both Transformer-based and convolutional models. Through our evaluations, we demonstrate that LTX significantly outperforms the current state-of-the-art in explainability across various metrics.
Efficient Discovery and Effective Evaluation of Visual Perceptual Similarity: A Benchmark and Beyond
Aug 28, 2023

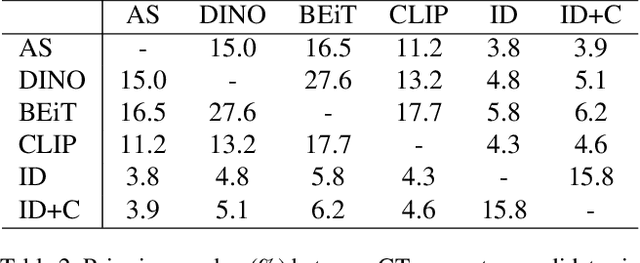
Visual similarities discovery (VSD) is an important task with broad e-commerce applications. Given an image of a certain object, the goal of VSD is to retrieve images of different objects with high perceptual visual similarity. Although being a highly addressed problem, the evaluation of proposed methods for VSD is often based on a proxy of an identification-retrieval task, evaluating the ability of a model to retrieve different images of the same object. We posit that evaluating VSD methods based on identification tasks is limited, and faithful evaluation must rely on expert annotations. In this paper, we introduce the first large-scale fashion visual similarity benchmark dataset, consisting of more than 110K expert-annotated image pairs. Besides this major contribution, we share insight from the challenges we faced while curating this dataset. Based on these insights, we propose a novel and efficient labeling procedure that can be applied to any dataset. Our analysis examines its limitations and inductive biases, and based on these findings, we propose metrics to mitigate those limitations. Though our primary focus lies on visual similarity, the methodologies we present have broader applications for discovering and evaluating perceptual similarity across various domains.
Representation Learning via Variational Bayesian Networks
Jun 28, 2023



We present Variational Bayesian Network (VBN) - a novel Bayesian entity representation learning model that utilizes hierarchical and relational side information and is particularly useful for modeling entities in the ``long-tail'', where the data is scarce. VBN provides better modeling for long-tail entities via two complementary mechanisms: First, VBN employs informative hierarchical priors that enable information propagation between entities sharing common ancestors. Additionally, VBN models explicit relations between entities that enforce complementary structure and consistency, guiding the learned representations towards a more meaningful arrangement in space. Second, VBN represents entities by densities (rather than vectors), hence modeling uncertainty that plays a complementary role in coping with data scarcity. Finally, we propose a scalable Variational Bayes optimization algorithm that enables fast approximate Bayesian inference. We evaluate the effectiveness of VBN on linguistic, recommendations, and medical inference tasks. Our findings show that VBN outperforms other existing methods across multiple datasets, and especially in the long-tail.
GPT-Calls: Enhancing Call Segmentation and Tagging by Generating Synthetic Conversations via Large Language Models
Jun 09, 2023



Transcriptions of phone calls are of significant value across diverse fields, such as sales, customer service, healthcare, and law enforcement. Nevertheless, the analysis of these recorded conversations can be an arduous and time-intensive process, especially when dealing with extended or multifaceted dialogues. In this work, we propose a novel method, GPT-distilled Calls Segmentation and Tagging (GPT-Calls), for efficient and accurate call segmentation and topic extraction. GPT-Calls is composed of offline and online phases. The offline phase is applied once to a given list of topics and involves generating a distribution of synthetic sentences for each topic using a GPT model and extracting anchor vectors. The online phase is applied to every call separately and scores the similarity between the transcripted conversation and the topic anchors found in the offline phase. Then, time domain analysis is applied to the similarity scores to group utterances into segments and tag them with topics. The proposed paradigm provides an accurate and efficient method for call segmentation and topic extraction that does not require labeled data, thus making it a versatile approach applicable to various domains. Our algorithm operates in production under Dynamics 365 Sales Conversation Intelligence, and our research is based on real sales conversations gathered from various Dynamics 365 Sales tenants.