 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIn-Context Learning with Long-Context Models: An In-Depth Exploration
Apr 30, 2024As model context lengths continue to increase, the number of demonstrations that can be provided in-context approaches the size of entire training datasets. We study the behavior of in-context learning (ICL) at this extreme scale on multiple datasets and models. We show that, for many datasets with large label spaces, performance continues to increase with hundreds or thousands of demonstrations. We contrast this with example retrieval and finetuning: example retrieval shows excellent performance at low context lengths but has diminished gains with more demonstrations; finetuning is more data hungry than ICL but can sometimes exceed long-context ICL performance with additional data. We use this ICL setting as a testbed to study several properties of both in-context learning and long-context models. We show that long-context ICL is less sensitive to random input shuffling than short-context ICL, that grouping of same-label examples can negatively impact performance, and that the performance boosts we see do not arise from cumulative gain from encoding many examples together. We conclude that although long-context ICL can be surprisingly effective, most of this gain comes from attending back to similar examples rather than task learning.
Transformers Can Achieve Length Generalization But Not Robustly
Feb 14, 2024



Length generalization, defined as the ability to extrapolate from shorter training sequences to longer test ones, is a significant challenge for language models. This issue persists even with large-scale Transformers handling relatively straightforward tasks. In this paper, we test the Transformer's ability of length generalization using the task of addition of two integers. We show that the success of length generalization is intricately linked to the data format and the type of position encoding. Using the right combination of data format and position encodings, we show for the first time that standard Transformers can extrapolate to a sequence length that is 2.5x the input length. Nevertheless, unlike in-distribution generalization, length generalization remains fragile, significantly influenced by factors like random weight initialization and training data order, leading to large variances across different random seeds.
In-Context Principle Learning from Mistakes
Feb 09, 2024

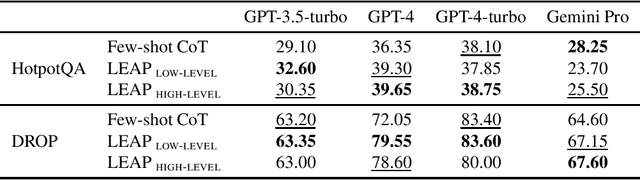

In-context learning (ICL, also known as few-shot prompting) has been the standard method of adapting LLMs to downstream tasks, by learning from a few input-output examples. Nonetheless, all ICL-based approaches only learn from correct input-output pairs. In this paper, we revisit this paradigm, by learning more from the few given input-output examples. We introduce Learning Principles (LEAP): First, we intentionally induce the model to make mistakes on these few examples; then we reflect on these mistakes, and learn explicit task-specific "principles" from them, which help solve similar problems and avoid common mistakes; finally, we prompt the model to answer unseen test questions using the original few-shot examples and these learned general principles. We evaluate LEAP on a wide range of benchmarks, including multi-hop question answering (Hotpot QA), textual QA (DROP), Big-Bench Hard reasoning, and math problems (GSM8K and MATH); in all these benchmarks, LEAP improves the strongest available LLMs such as GPT-3.5-turbo, GPT-4, GPT-4 turbo and Claude-2.1. For example, LEAP improves over the standard few-shot prompting using GPT-4 by 7.5% in DROP, and by 3.3% in HotpotQA. Importantly, LEAP does not require any more input or examples than the standard few-shot prompting settings.
Universal Self-Consistency for Large Language Model Generation
Nov 29, 2023



Self-consistency with chain-of-thought prompting (CoT) has demonstrated remarkable performance gains on various challenging tasks, by utilizing multiple reasoning paths sampled from large language models (LLMs). However, self-consistency relies on the answer extraction process to aggregate multiple solutions, which is not applicable to free-form answers. In this work, we propose Universal Self-Consistency (USC), which leverages LLMs themselves to select the most consistent answer among multiple candidates. We evaluate USC on a variety of benchmarks, including mathematical reasoning, code generation, long-context summarization, and open-ended question answering. On open-ended generation tasks where the original self-consistency method is not applicable, USC effectively utilizes multiple samples and improves the performance. For mathematical reasoning, USC matches the standard self-consistency performance without requiring the answer formats to be similar. Finally, without access to execution results, USC also matches the execution-based voting performance on code generation.
CAT-LM: Training Language Models on Aligned Code And Tests
Oct 02, 2023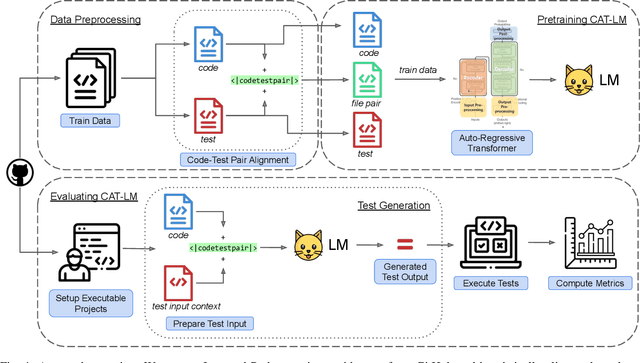

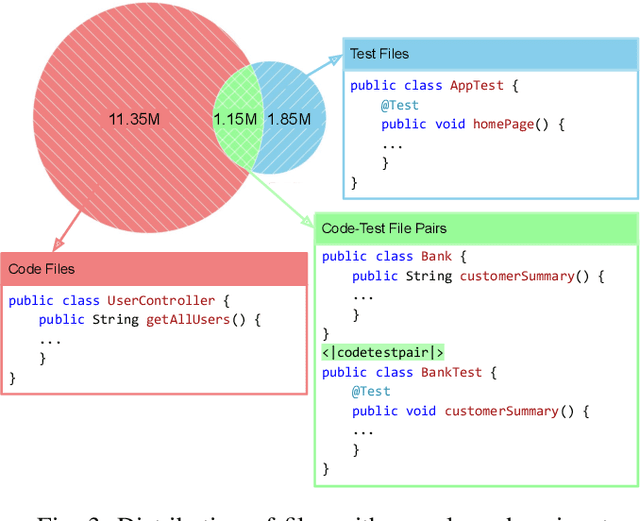
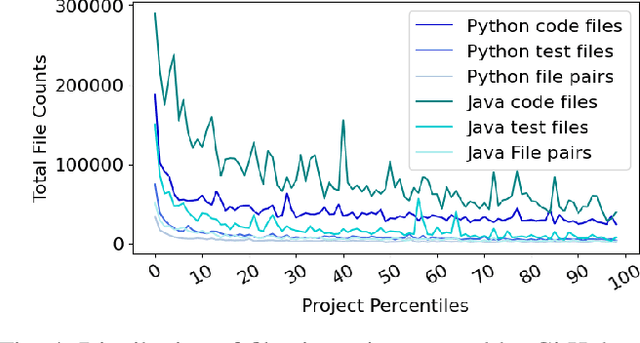
Testing is an integral part of the software development process. Yet, writing tests is time-consuming and therefore often neglected. Classical test generation tools such as EvoSuite generate behavioral test suites by optimizing for coverage, but tend to produce tests that are hard to understand. Language models trained on code can generate code that is highly similar to that written by humans, but current models are trained to generate each file separately, as is standard practice in natural language processing, and thus fail to consider the code-under-test context when producing a test file. In this work, we propose the Aligned Code And Tests Language Model (CAT-LM), a GPT-style language model with 2.7 Billion parameters, trained on a corpus of Python and Java projects. We utilize a novel pretraining signal that explicitly considers the mapping between code and test files when available. We also drastically increase the maximum sequence length of inputs to 8,192 tokens, 4x more than typical code generation models, to ensure that the code context is available to the model when generating test code. We analyze its usefulness for realistic applications, showing that sampling with filtering (e.g., by compilability, coverage) allows it to efficiently produce tests that achieve coverage similar to ones written by developers while resembling their writing style. By utilizing the code context, CAT-LM generates more valid tests than even much larger language models trained with more data (CodeGen 16B and StarCoder) and substantially outperforms a recent test-specific model (TeCo) at test completion. Overall, our work highlights the importance of incorporating software-specific insights when training language models for code and paves the way to more powerful automated test generation.
WebArena: A Realistic Web Environment for Building Autonomous Agents
Jul 25, 2023



With generative AI advances, the exciting potential for autonomous agents to manage daily tasks via natural language commands has emerged. However, cur rent agents are primarily created and tested in simplified synthetic environments, substantially limiting real-world scenario representation. In this paper, we build an environment for agent command and control that is highly realistic and reproducible. Specifically, we focus on agents that perform tasks on websites, and we create an environment with fully functional websites from four common domains: e-commerce, social forum discussions, collaborative software development, and content management. Our environment is enriched with tools (e.g., a map) and external knowledge bases (e.g., user manuals) to encourage human-like task-solving. Building upon our environment, we release a set of benchmark tasks focusing on evaluating the functional correctness of task completions. The tasks in our benchmark are diverse, long-horizon, and are designed to emulate tasks that humans routinely perform on the internet. We design and implement several autonomous agents, integrating recent techniques such as reasoning before acting. The results demonstrate that solving complex tasks is challenging: our best GPT-4-based agent only achieves an end-to-end task success rate of 10.59%. These results highlight the need for further development of robust agents, that current state-of-the-art LMs are far from perfect performance in these real-life tasks, and that WebArena can be used to measure such progress. Our code, data, environment reproduction resources, and video demonstrations are publicly available at https://webarena.dev/.
GPT-Calls: Enhancing Call Segmentation and Tagging by Generating Synthetic Conversations via Large Language Models
Jun 09, 2023



Transcriptions of phone calls are of significant value across diverse fields, such as sales, customer service, healthcare, and law enforcement. Nevertheless, the analysis of these recorded conversations can be an arduous and time-intensive process, especially when dealing with extended or multifaceted dialogues. In this work, we propose a novel method, GPT-distilled Calls Segmentation and Tagging (GPT-Calls), for efficient and accurate call segmentation and topic extraction. GPT-Calls is composed of offline and online phases. The offline phase is applied once to a given list of topics and involves generating a distribution of synthetic sentences for each topic using a GPT model and extracting anchor vectors. The online phase is applied to every call separately and scores the similarity between the transcripted conversation and the topic anchors found in the offline phase. Then, time domain analysis is applied to the similarity scores to group utterances into segments and tag them with topics. The proposed paradigm provides an accurate and efficient method for call segmentation and topic extraction that does not require labeled data, thus making it a versatile approach applicable to various domains. Our algorithm operates in production under Dynamics 365 Sales Conversation Intelligence, and our research is based on real sales conversations gathered from various Dynamics 365 Sales tenants.
On the Expressivity Role of LayerNorm in Transformers' Attention
May 11, 2023



Layer Normalization (LayerNorm) is an inherent component in all Transformer-based models. In this paper, we show that LayerNorm is crucial to the expressivity of the multi-head attention layer that follows it. This is in contrast to the common belief that LayerNorm's only role is to normalize the activations during the forward pass, and their gradients during the backward pass. We consider a geometric interpretation of LayerNorm and show that it consists of two components: (a) projection of the input vectors to a $d-1$ space that is orthogonal to the $\left[1,1,...,1\right]$ vector, and (b) scaling of all vectors to the same norm of $\sqrt{d}$. We show that each of these components is important for the attention layer that follows it in Transformers: (a) projection allows the attention mechanism to create an attention query that attends to all keys equally, offloading the need to learn this operation by the attention; and (b) scaling allows each key to potentially receive the highest attention, and prevents keys from being "un-select-able". We show empirically that Transformers do indeed benefit from these properties of LayeNorm in general language modeling and even in computing simple functions such as "majority". Our code is available at https://github.com/tech-srl/layer_norm_expressivity_role .
Unlimiformer: Long-Range Transformers with Unlimited Length Input
May 02, 2023



Transformer-based models typically have a predefined bound to their input length, because of their need to potentially attend to every token in the input. In this work, we propose Unlimiformer: a general approach that can wrap any existing pretrained encoder-decoder transformer, and offload the attention computation across all layers to a single $k$-nearest-neighbor index; this index can be kept on either the GPU or CPU memory and queried in sub-linear time. This way, we can index extremely long input sequences, while every attention head in every decoder layer retrieves its top-$k$ keys, instead of attending to every key. We demonstrate Unlimiformers's efficacy on several long-document and multi-document summarization benchmarks, showing that it can summarize even 350k token-long inputs from the BookSum dataset, without any input truncation at test time. Unlimiformer improves pretrained models such as BART and Longformer by extending them to unlimited inputs without additional learned weights and without modifying their code. We make our code and models publicly available at https://github.com/abertsch72/unlimiformer .
Self-Refine: Iterative Refinement with Self-Feedback
Mar 30, 2023



Like people, LLMs do not always generate the best text for a given generation problem on their first try (e.g., summaries, answers, explanations). Just as people then refine their text, we introduce SELF-REFINE, a framework for similarly improving initial outputs from LLMs through iterative feedback and refinement. The main idea is to generate an output using an LLM, then allow the same model to provide multi-aspect feedback for its own output; finally, the same model refines its previously generated output given its own feedback. Unlike earlier work, our iterative refinement framework does not require supervised training data or reinforcement learning, and works with a single LLM. We experiment with 7 diverse tasks, ranging from review rewriting to math reasoning, demonstrating that our approach outperforms direct generation. In all tasks, outputs generated with SELF-REFINE are preferred by humans and by automated metrics over those generated directly with GPT-3.5 and GPT-4, improving on average by absolute 20% across tasks.