 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the Expressivity Role of LayerNorm in Transformers' Attention
May 11, 2023



Layer Normalization (LayerNorm) is an inherent component in all Transformer-based models. In this paper, we show that LayerNorm is crucial to the expressivity of the multi-head attention layer that follows it. This is in contrast to the common belief that LayerNorm's only role is to normalize the activations during the forward pass, and their gradients during the backward pass. We consider a geometric interpretation of LayerNorm and show that it consists of two components: (a) projection of the input vectors to a $d-1$ space that is orthogonal to the $\left[1,1,...,1\right]$ vector, and (b) scaling of all vectors to the same norm of $\sqrt{d}$. We show that each of these components is important for the attention layer that follows it in Transformers: (a) projection allows the attention mechanism to create an attention query that attends to all keys equally, offloading the need to learn this operation by the attention; and (b) scaling allows each key to potentially receive the highest attention, and prevents keys from being "un-select-able". We show empirically that Transformers do indeed benefit from these properties of LayeNorm in general language modeling and even in computing simple functions such as "majority". Our code is available at https://github.com/tech-srl/layer_norm_expressivity_role .
Diffusing Graph Attention
Mar 01, 2023The dominant paradigm for machine learning on graphs uses Message Passing Graph Neural Networks (MP-GNNs), in which node representations are updated by aggregating information in their local neighborhood. Recently, there have been increasingly more attempts to adapt the Transformer architecture to graphs in an effort to solve some known limitations of MP-GNN. A challenging aspect of designing Graph Transformers is integrating the arbitrary graph structure into the architecture. We propose Graph Diffuser (GD) to address this challenge. GD learns to extract structural and positional relationships between distant nodes in the graph, which it then uses to direct the Transformer's attention and node representation. We demonstrate that existing GNNs and Graph Transformers struggle to capture long-range interactions and how Graph Diffuser does so while admitting intuitive visualizations. Experiments on eight benchmarks show Graph Diffuser to be a highly competitive model, outperforming the state-of-the-art in a diverse set of domains.
Thinking Like Transformers
Jun 13, 2021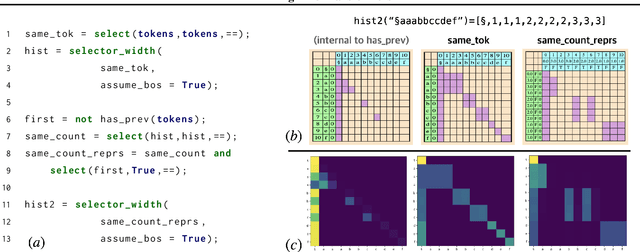
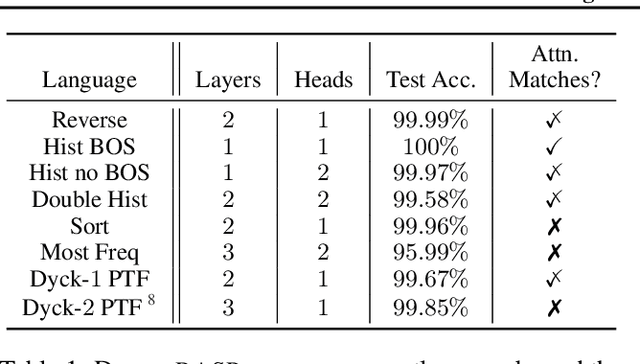
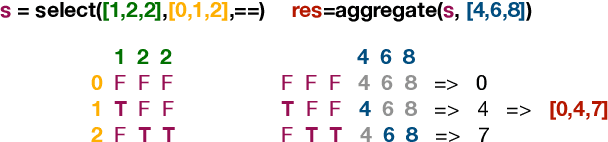
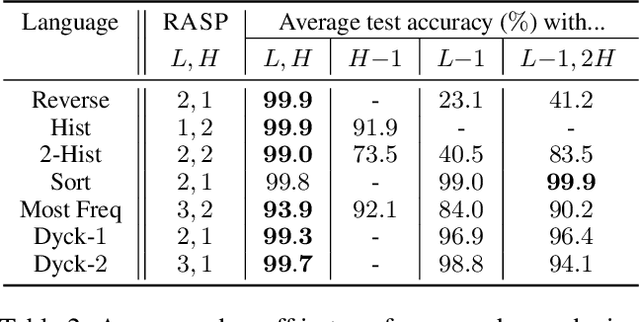
What is the computational model behind a Transformer? Where recurrent neural networks have direct parallels in finite state machines, allowing clear discussion and thought around architecture variants or trained models, Transformers have no such familiar parallel. In this paper we aim to change that, proposing a computational model for the transformer-encoder in the form of a programming language. We map the basic components of a transformer-encoder -- attention and feed-forward computation -- into simple primitives, around which we form a programming language: the Restricted Access Sequence Processing Language (RASP). We show how RASP can be used to program solutions to tasks that could conceivably be learned by a Transformer, and how a Transformer can be trained to mimic a RASP solution. In particular, we provide RASP programs for histograms, sorting, and Dyck-languages. We further use our model to relate their difficulty in terms of the number of required layers and attention heads: analyzing a RASP program implies a maximum number of heads and layers necessary to encode a task in a transformer. Finally, we see how insights gained from our abstraction might be used to explain phenomena seen in recent works.
How Attentive are Graph Attention Networks?
May 30, 2021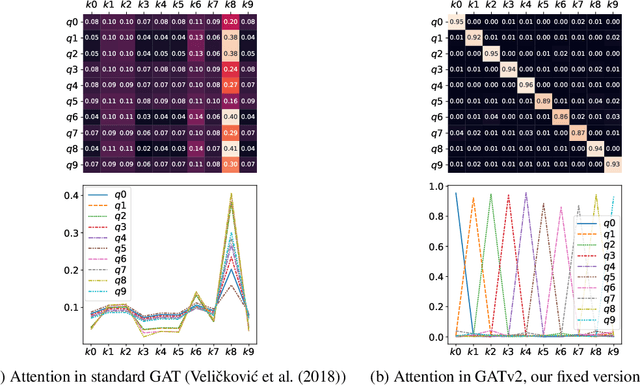
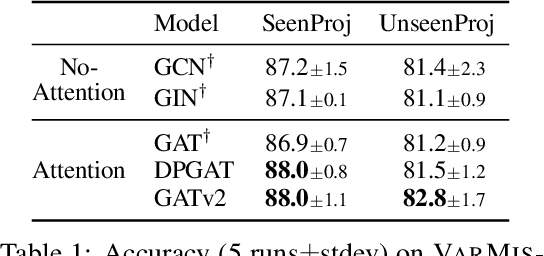
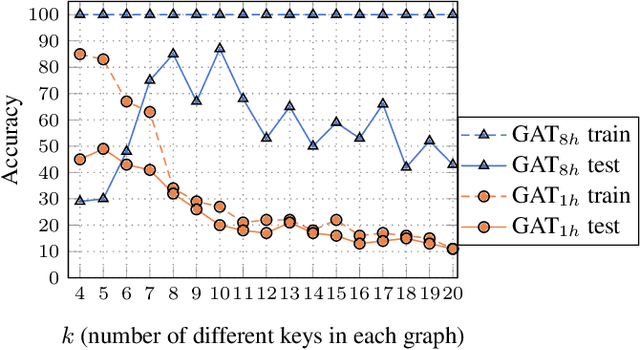
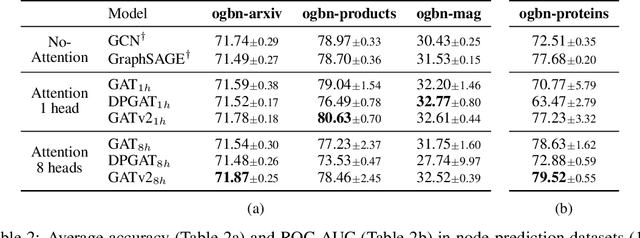
Graph Attention Networks (GATs) are one of the most popular GNN architectures and are considered as the state-of-the-art architecture for representation learning with graphs. In GAT, every node attends to its neighbors given its own representation as the query. However, in this paper we show that GATs can only compute a restricted kind of attention where the ranking of attended nodes is unconditioned on the query node. We formally define this restricted kind of attention as static attention and distinguish it from a strictly more expressive dynamic attention. Because GATs use a static attention mechanism, there are simple graph problems that GAT cannot express: in a controlled problem, we show that static attention hinders GAT from even fitting the training data. To remove this limitation, we introduce a simple fix by modifying the order of operations and propose GATv2: a dynamic graph attention variant that is strictly more expressive than GAT. We perform an extensive evaluation and show that GATv2 outperforms GAT across 11 OGB and other benchmarks while we match their parametric costs. Our code is available at https://github.com/tech-srl/how_attentive_are_gats .
On the Bottleneck of Graph Neural Networks and its Practical Implications
Jun 09, 2020
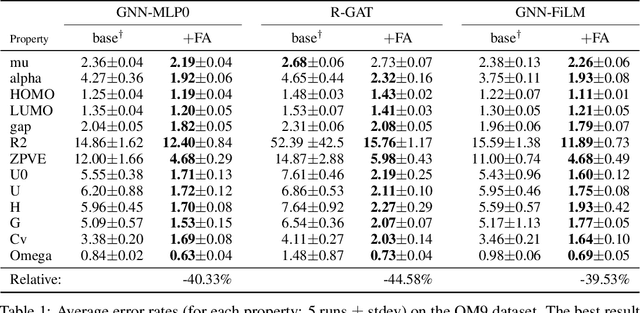
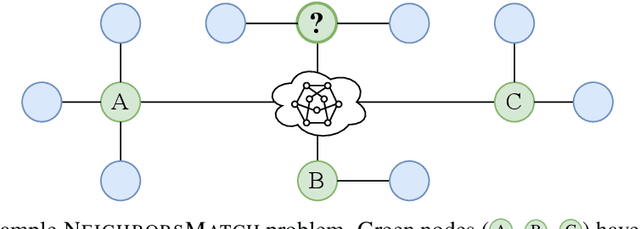
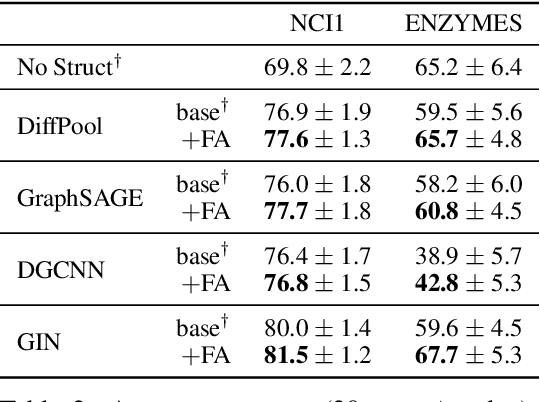
Graph neural networks (GNNs) were shown to effectively learn from highly structured data containing elements (nodes) with relationships (edges) between them. GNN variants differ in how each node in the graph absorbs the information flowing from its neighbor nodes. In this paper, we highlight an inherent problem in GNNs: the mechanism of propagating information between neighbors creates a bottleneck when every node aggregates messages from its neighbors. This bottleneck causes the over-squashing of exponentially-growing information into fixed-size vectors. As a result, the graph fails to propagate messages flowing from distant nodes and performs poorly when the prediction task depends on long-range information. We demonstrate that the bottleneck hinders popular GNNs from fitting the training data. We show that GNNs that absorb incoming edges equally, like GCN and GIN, are more susceptible to over-squashing than other GNN types. We further show that existing, extensively-tuned, GNN-based models suffer from over-squashing and that breaking the bottleneck improves state-of-the-art results without any hyperparameter tuning or additional weights.
Neural Edit Completion
May 27, 2020
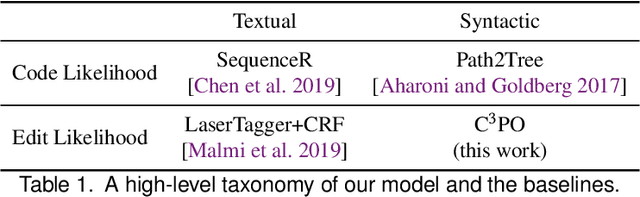
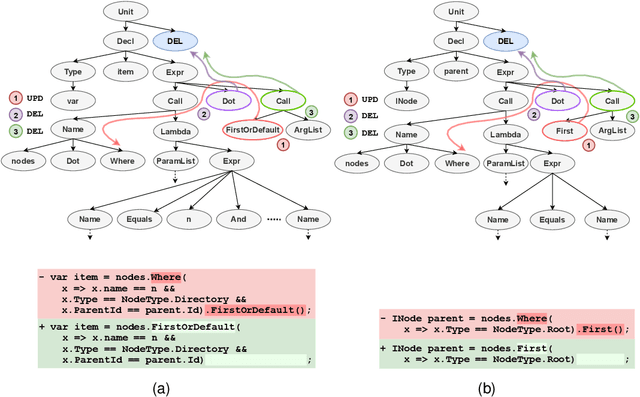
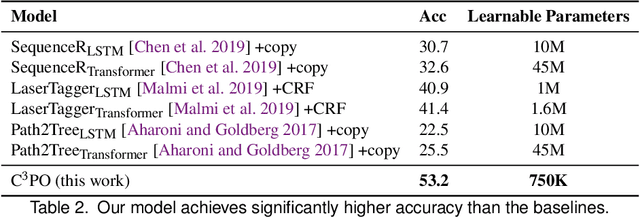
We address the problem of predicting edit completions based on a learned model that was trained on past edits. Given a code snippet that is partially edited, our goal is to predict a completion of the edit for the rest of the snippet. We refer to this task as the EditCompletion task and present a novel approach for tackling it. The main idea is to directly represent structural edits. This allows us to model the likelihood of the edit itself, rather than learning the likelihood of the edited code. We represent an edit operation as a path in the program's Abstract Syntax Tree (AST), originating from the source of the edit to the target of the edit. Using this representation, we present a powerful and lightweight neural model for the EditCompletion task. We conduct a thorough evaluation, comparing our approach to a variety of representation and modeling approaches that are driven by multiple strong models such as LSTMs, Transformers, and neural CRFs. Our experiments show that our model achieves 28% relative gain over state-of-the-art sequential models and 2$\times$ higher accuracy than syntactic models that learn to generate the edited code instead of modeling the edits directly. We make our code, dataset, and trained models publicly available.
A Formal Hierarchy of RNN Architectures
Apr 24, 2020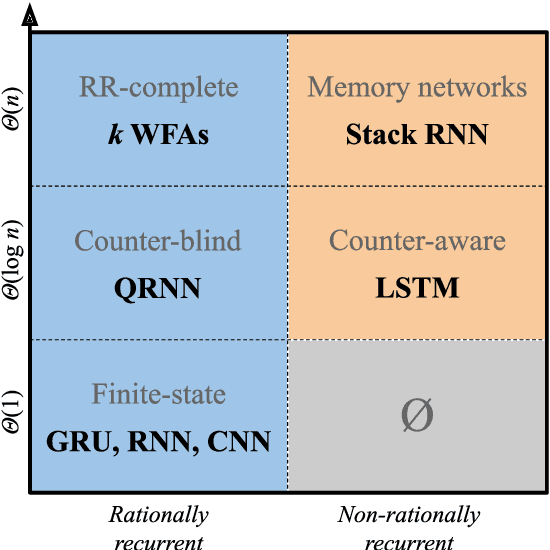
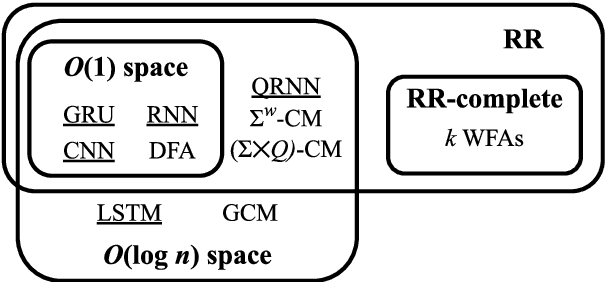
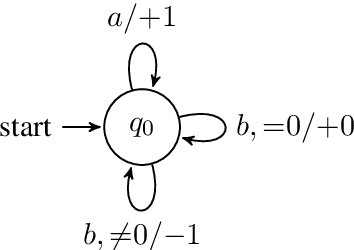
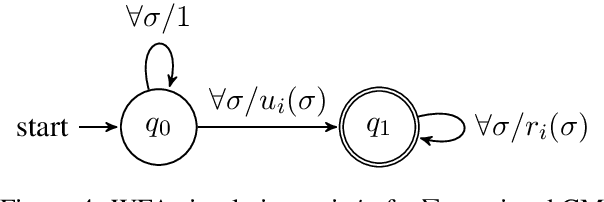
We develop a formal hierarchy of the expressive capacity of RNN architectures. The hierarchy is based on two formal properties: space complexity, which measures the RNN's memory, and rational recurrence, defined as whether the recurrent update can be described by a weighted finite-state machine. We place several RNN variants within this hierarchy. For example, we prove the LSTM is not rational, which formally separates it from the related QRNN (Bradbury et al., 2016). We also show how these models' expressive capacity is expanded by stacking multiple layers or composing them with different pooling functions. Our results build on the theory of "saturated" RNNs (Merrill, 2019). While formally extending these findings to unsaturated RNNs is left to future work, we hypothesize that the practical learnable capacity of unsaturated RNNs obeys a similar hierarchy. Experimental findings from training unsaturated networks on formal languages support this conjecture.
Adversarial Examples for Models of Code
Nov 27, 2019


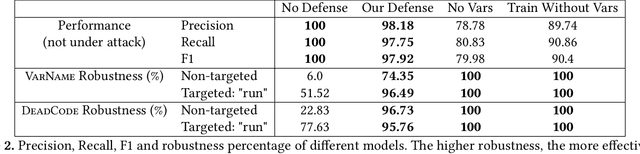
Neural models of code have shown impressive performance for tasks such as predicting method names and identifying certain kinds of bugs. In this paper, we show that these models are vulnerable to adversarial examples, and introduce a novel approach for attacking trained models of code with adversarial examples. The main idea is to force a given trained model to make an incorrect prediction as specified by the adversary by introducing small perturbations that do not change the program's semantics. To find such perturbations, we present a new technique for Discrete Adversarial Manipulation of Programs (DAMP). DAMP works by deriving the desired prediction with respect to the model's inputs while holding the model weights constant and following the gradients to slightly modify the code. To defend a model against such attacks, we propose placing a defensive model (Anti-DAMP) in front of it. Anti-DAMP detects unlikely mutations and masks them before feeding the input to the downstream model. We show that our DAMP attack is effective across three neural architectures: code2vec, GGNN, and GNN-FiLM, in both Java and C#. We show that DAMP has up to 89% success rate in changing a prediction to the adversary's choice ("targeted attack"), and a success rate of up to 94% in changing a given prediction to any incorrect prediction ("non-targeted attack"). By using Anti-DAMP, the success rate of the attack drops drastically for both targeted and non-targeted attacks, with a minor penalty of 2% relative degradation in accuracy while not performing under attack.
Learning Deterministic Weighted Automata with Queries and Counterexamples
Oct 30, 2019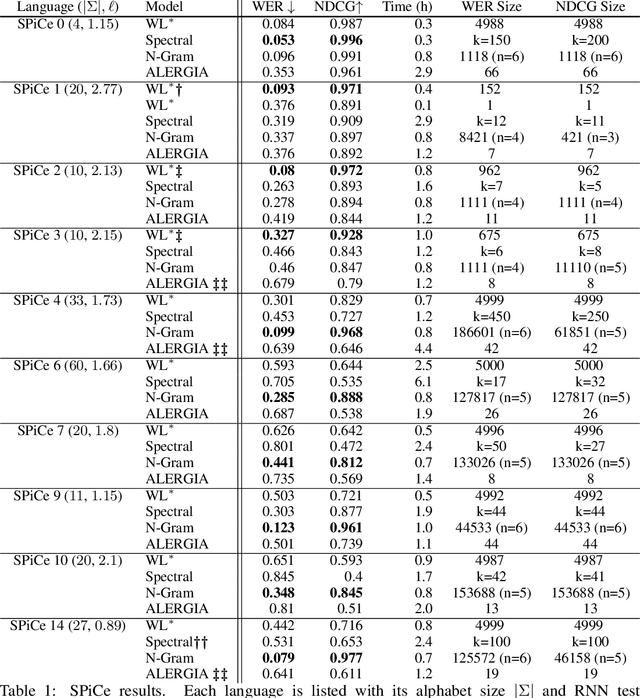

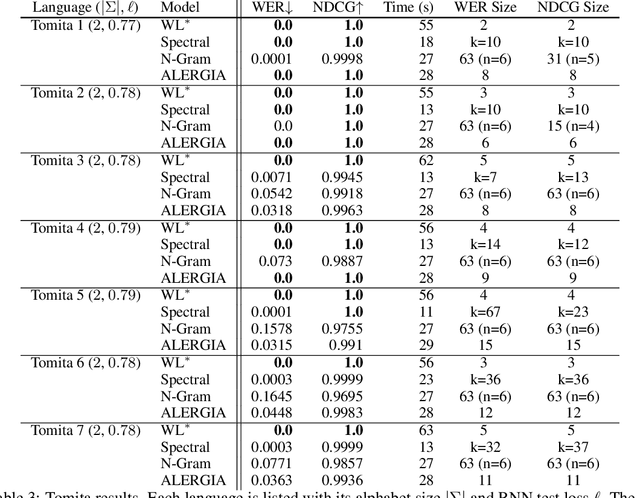

We present an algorithm for extraction of a probabilistic deterministic finite automaton (PDFA) from a given black-box language model, such as a recurrent neural network (RNN). The algorithm is a variant of the exact-learning algorithm L*, adapted to a probabilistic setting with noise. The key insight is the use of conditional probabilities for observations, and the introduction of a local tolerance when comparing them. When applied to RNNs, our algorithm often achieves better word error rate (WER) and normalised distributed cumulative gain (NDCG) than that achieved by spectral extraction of weighted finite automata (WFA) from the same networks. PDFAs are substantially more expressive than n-grams, and are guaranteed to be stochastic and deterministic - unlike spectrally extracted WFAs.
Structural Language Models for Any-Code Generation
Sep 30, 2019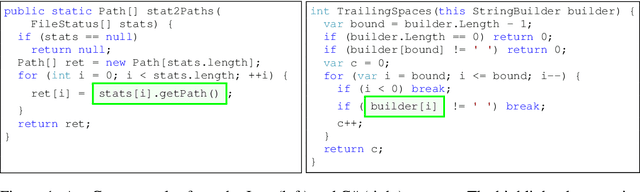



We address the problem of Any-Code Generation (AnyGen) - generating code without any restriction on the vocabulary or structure. The state-of-the-art in this problem is the sequence-to-sequence (seq2seq) approach, which treats code as a sequence and does not leverage any structural information. We introduce a new approach to AnyGen that leverages the strict syntax of programming languages to model a code snippet as a tree - structural language modeling (SLM). SLM estimates the probability of the program's abstract syntax tree (AST) by decomposing it into a product of conditional probabilities over its nodes. We present a neural model that computes these conditional probabilities by considering all AST paths leading to a target node. Unlike previous structural techniques that have severely restricted the kinds of expressions that can be generated, our approach can generate arbitrary expressions in any programming language. Our model significantly outperforms both seq2seq and a variety of existing structured approaches in generating Java and C# code. We make our code, datasets, and models available online.