 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSimRec: Mitigating the Cold-Start Problem in Sequential Recommendation by Integrating Item Similarity
Oct 29, 2024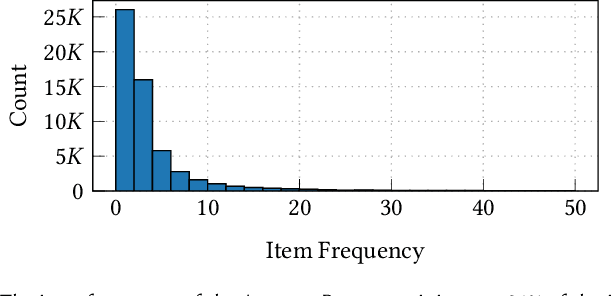

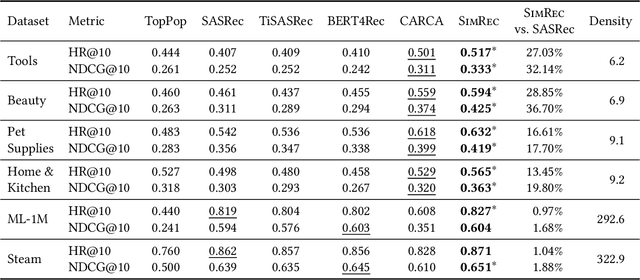
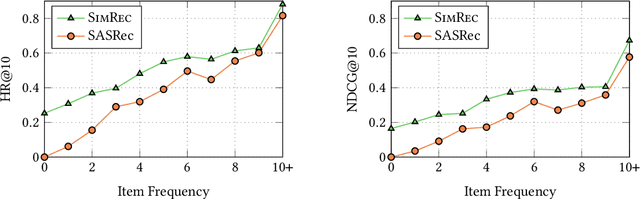
Sequential recommendation systems often struggle to make predictions or take action when dealing with cold-start items that have limited amount of interactions. In this work, we propose SimRec - a new approach to mitigate the cold-start problem in sequential recommendation systems. SimRec addresses this challenge by leveraging the inherent similarity among items, incorporating item similarities into the training process through a customized loss function. Importantly, this enhancement is attained with identical model architecture and the same amount of trainable parameters, resulting in the same inference time and requiring minimal additional effort. This novel approach results in a robust contextual sequential recommendation model capable of effectively handling rare items, including those that were not explicitly seen during training, thereby enhancing overall recommendation performance. Rigorous evaluations against multiple baselines on diverse datasets showcase SimRec's superiority, particularly in scenarios involving items occurring less than 10 times in the training data. The experiments reveal an impressive improvement, with SimRec achieving up to 78% higher HR@10 compared to SASRec. Notably, SimRec outperforms strong baselines on sparse datasets while delivering on-par performance on dense datasets. Our code is available at https://github.com/amazon-science/sequential-recommendation-using-similarity.
FuseCap: Leveraging Large Language Models to Fuse Visual Data into Enriched Image Captions
May 28, 2023Image captioning is a central task in computer vision which has experienced substantial progress following the advent of vision-language pre-training techniques. In this paper, we highlight a frequently overlooked limitation of captioning models that often fail to capture semantically significant elements. This drawback can be traced back to the text-image datasets; while their captions typically offer a general depiction of image content, they frequently omit salient details. To mitigate this limitation, we propose FuseCap - a novel method for enriching captions with additional visual information, obtained from vision experts, such as object detectors, attribute recognizers, and Optical Character Recognizers (OCR). Our approach fuses the outputs of such vision experts with the original caption using a large language model (LLM), yielding enriched captions that present a comprehensive image description. We validate the effectiveness of the proposed caption enrichment method through both quantitative and qualitative analysis. Our method is then used to curate the training set of a captioning model based BLIP which surpasses current state-of-the-art approaches in generating accurate and detailed captions while using significantly fewer parameters and training data. As additional contributions, we provide a dataset comprising of 12M image-enriched caption pairs and show that the proposed method largely improves image-text retrieval.
On the Expressivity Role of LayerNorm in Transformers' Attention
May 11, 2023



Layer Normalization (LayerNorm) is an inherent component in all Transformer-based models. In this paper, we show that LayerNorm is crucial to the expressivity of the multi-head attention layer that follows it. This is in contrast to the common belief that LayerNorm's only role is to normalize the activations during the forward pass, and their gradients during the backward pass. We consider a geometric interpretation of LayerNorm and show that it consists of two components: (a) projection of the input vectors to a $d-1$ space that is orthogonal to the $\left[1,1,...,1\right]$ vector, and (b) scaling of all vectors to the same norm of $\sqrt{d}$. We show that each of these components is important for the attention layer that follows it in Transformers: (a) projection allows the attention mechanism to create an attention query that attends to all keys equally, offloading the need to learn this operation by the attention; and (b) scaling allows each key to potentially receive the highest attention, and prevents keys from being "un-select-able". We show empirically that Transformers do indeed benefit from these properties of LayeNorm in general language modeling and even in computing simple functions such as "majority". Our code is available at https://github.com/tech-srl/layer_norm_expressivity_role .
BLOOM: A 176B-Parameter Open-Access Multilingual Language Model
Nov 09, 2022Large language models (LLMs) have been shown to be able to perform new tasks based on a few demonstrations or natural language instructions. While these capabilities have led to widespread adoption, most LLMs are developed by resource-rich organizations and are frequently kept from the public. As a step towards democratizing this powerful technology, we present BLOOM, a 176B-parameter open-access language model designed and built thanks to a collaboration of hundreds of researchers. BLOOM is a decoder-only Transformer language model that was trained on the ROOTS corpus, a dataset comprising hundreds of sources in 46 natural and 13 programming languages (59 in total). We find that BLOOM achieves competitive performance on a wide variety of benchmarks, with stronger results after undergoing multitask prompted finetuning. To facilitate future research and applications using LLMs, we publicly release our models and code under the Responsible AI License.
How Attentive are Graph Attention Networks?
May 30, 2021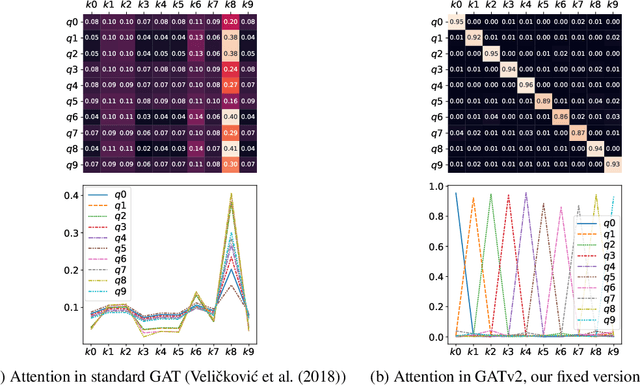
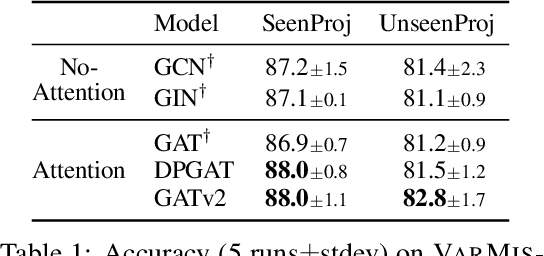
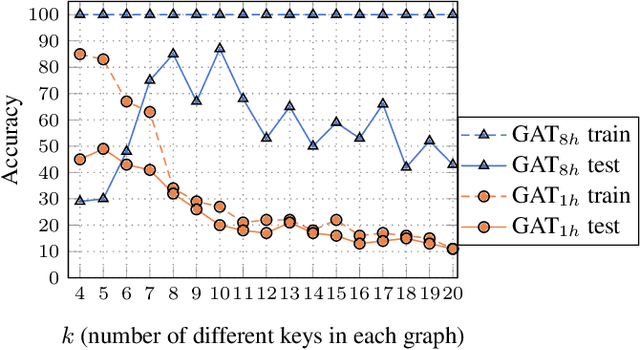
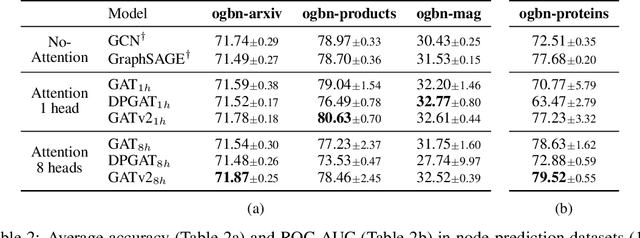
Graph Attention Networks (GATs) are one of the most popular GNN architectures and are considered as the state-of-the-art architecture for representation learning with graphs. In GAT, every node attends to its neighbors given its own representation as the query. However, in this paper we show that GATs can only compute a restricted kind of attention where the ranking of attended nodes is unconditioned on the query node. We formally define this restricted kind of attention as static attention and distinguish it from a strictly more expressive dynamic attention. Because GATs use a static attention mechanism, there are simple graph problems that GAT cannot express: in a controlled problem, we show that static attention hinders GAT from even fitting the training data. To remove this limitation, we introduce a simple fix by modifying the order of operations and propose GATv2: a dynamic graph attention variant that is strictly more expressive than GAT. We perform an extensive evaluation and show that GATv2 outperforms GAT across 11 OGB and other benchmarks while we match their parametric costs. Our code is available at https://github.com/tech-srl/how_attentive_are_gats .
Neural Edit Completion
May 27, 2020
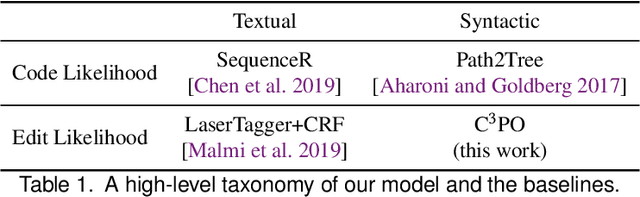
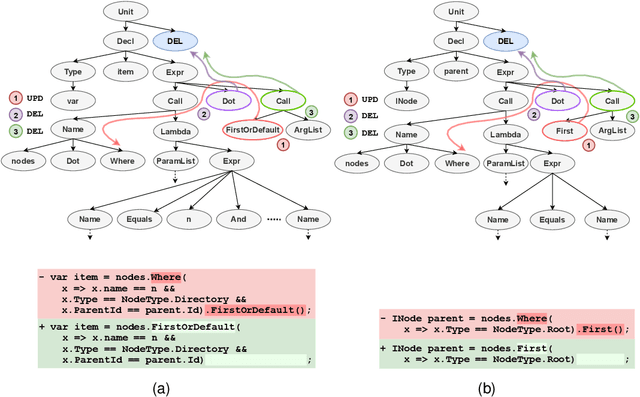
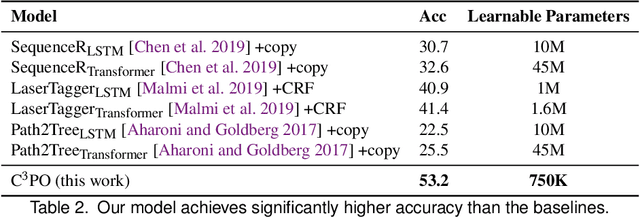
We address the problem of predicting edit completions based on a learned model that was trained on past edits. Given a code snippet that is partially edited, our goal is to predict a completion of the edit for the rest of the snippet. We refer to this task as the EditCompletion task and present a novel approach for tackling it. The main idea is to directly represent structural edits. This allows us to model the likelihood of the edit itself, rather than learning the likelihood of the edited code. We represent an edit operation as a path in the program's Abstract Syntax Tree (AST), originating from the source of the edit to the target of the edit. Using this representation, we present a powerful and lightweight neural model for the EditCompletion task. We conduct a thorough evaluation, comparing our approach to a variety of representation and modeling approaches that are driven by multiple strong models such as LSTMs, Transformers, and neural CRFs. Our experiments show that our model achieves 28% relative gain over state-of-the-art sequential models and 2$\times$ higher accuracy than syntactic models that learn to generate the edited code instead of modeling the edits directly. We make our code, dataset, and trained models publicly available.