 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKOALA: Knowledge Conflict Augmentations for Robustness in Vision Language Models
Feb 19, 2025


The robustness of large language models (LLMs) against knowledge conflicts in unimodal question answering systems has been well studied. However, the effect of conflicts in information sources on vision language models (VLMs) in multimodal settings has not yet been explored. In this work, we propose \segsub, a framework that applies targeted perturbations to image sources to study and improve the robustness of VLMs against three different types of knowledge conflicts, namely parametric, source, and counterfactual conflicts. Contrary to prior findings that showed that LLMs are sensitive to parametric conflicts arising from textual perturbations, we find VLMs are largely robust to image perturbation. On the other hand, VLMs perform poorly on counterfactual examples (<30% accuracy) and fail to reason over source conflicts (<1% accuracy). We also find a link between hallucinations and image context, with GPT-4o prone to hallucination when presented with highly contextualized counterfactual examples. While challenges persist with source conflicts, finetuning models significantly improves reasoning over counterfactual samples. Our findings highlight the need for VLM training methodologies that enhance their reasoning capabilities, particularly in addressing complex knowledge conflicts between multimodal sources.
CAT-LM: Training Language Models on Aligned Code And Tests
Oct 02, 2023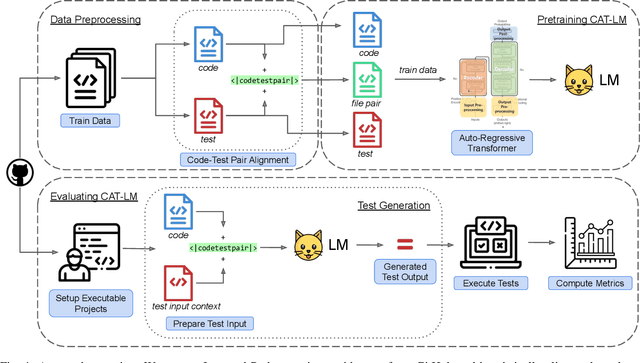

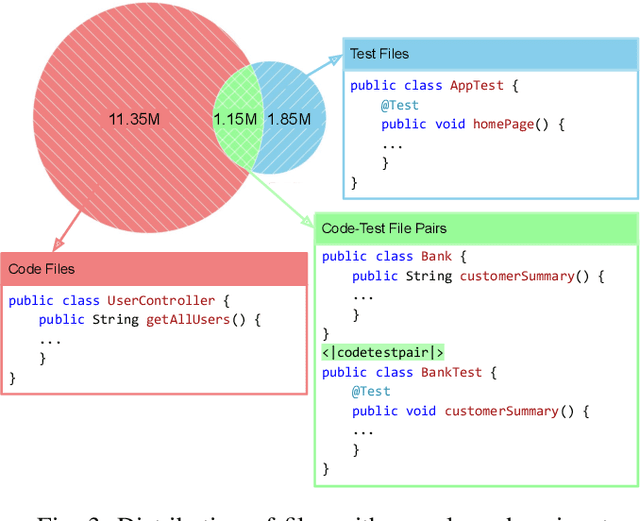
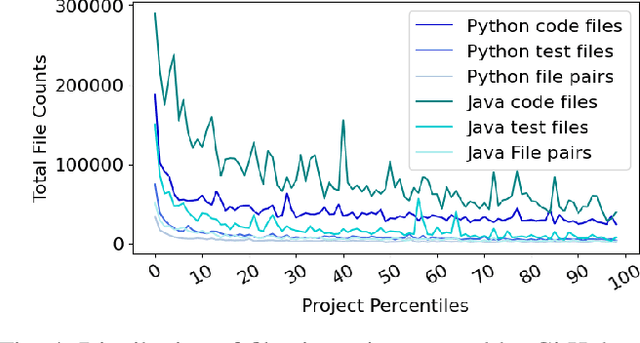
Testing is an integral part of the software development process. Yet, writing tests is time-consuming and therefore often neglected. Classical test generation tools such as EvoSuite generate behavioral test suites by optimizing for coverage, but tend to produce tests that are hard to understand. Language models trained on code can generate code that is highly similar to that written by humans, but current models are trained to generate each file separately, as is standard practice in natural language processing, and thus fail to consider the code-under-test context when producing a test file. In this work, we propose the Aligned Code And Tests Language Model (CAT-LM), a GPT-style language model with 2.7 Billion parameters, trained on a corpus of Python and Java projects. We utilize a novel pretraining signal that explicitly considers the mapping between code and test files when available. We also drastically increase the maximum sequence length of inputs to 8,192 tokens, 4x more than typical code generation models, to ensure that the code context is available to the model when generating test code. We analyze its usefulness for realistic applications, showing that sampling with filtering (e.g., by compilability, coverage) allows it to efficiently produce tests that achieve coverage similar to ones written by developers while resembling their writing style. By utilizing the code context, CAT-LM generates more valid tests than even much larger language models trained with more data (CodeGen 16B and StarCoder) and substantially outperforms a recent test-specific model (TeCo) at test completion. Overall, our work highlights the importance of incorporating software-specific insights when training language models for code and paves the way to more powerful automated test generation.
AI for Low-Code for AI
May 31, 2023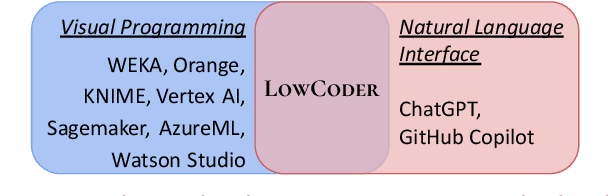


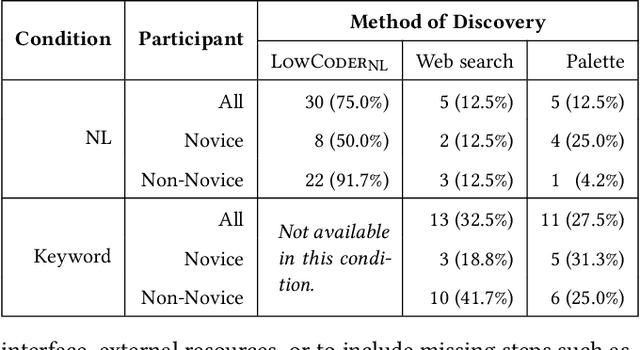
Low-code programming allows citizen developers to create programs with minimal coding effort, typically via visual (e.g. drag-and-drop) interfaces. In parallel, recent AI-powered tools such as Copilot and ChatGPT generate programs from natural language instructions. We argue that these modalities are complementary: tools like ChatGPT greatly reduce the need to memorize large APIs but still require their users to read (and modify) programs, whereas visual tools abstract away most or all programming but struggle to provide easy access to large APIs. At their intersection, we propose LowCoder, the first low-code tool for developing AI pipelines that supports both a visual programming interface (LowCoder_VP) and an AI-powered natural language interface (LowCoder_NL). We leverage this tool to provide some of the first insights into whether and how these two modalities help programmers by conducting a user study. We task 20 developers with varying levels of AI expertise with implementing four ML pipelines using LowCoder, replacing the LowCoder_NL component with a simple keyword search in half the tasks. Overall, we find that LowCoder is especially useful for (i) Discoverability: using LowCoder_NL, participants discovered new operators in 75% of the tasks, compared to just 32.5% and 27.5% using web search or scrolling through options respectively in the keyword-search condition, and (ii) Iterative Composition: 82.5% of tasks were successfully completed and many initial pipelines were further successfully improved. Qualitative analysis shows that AI helps users discover how to implement constructs when they know what to do, but still fails to support novices when they lack clarity on what they want to accomplish. Overall, our work highlights the benefits of combining the power of AI with low-code programming.
Code Search Intent Classification Using Weak Supervision
Nov 25, 2020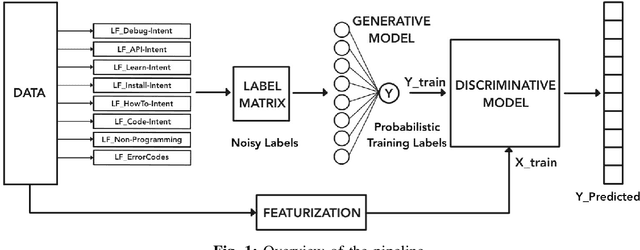

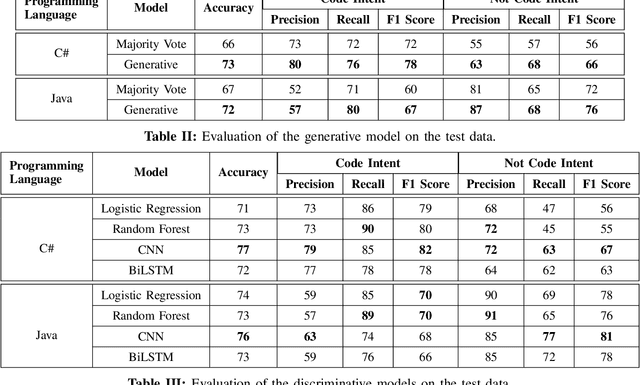

Developers use search for various tasks such as finding code, documentation, debugging information, etc. In particular, web search is heavily used by developers for finding code examples and snippets during the coding process. Recently, natural language based code search has been an active area of research. However, the lack of real-world large-scale datasets is a significant bottleneck. In this work, we propose a weak supervision based approach for detecting code search intent in search queries for C# and Java programming languages. We evaluate the approach against several baselines on a real-world dataset comprised of over 1 million queries mined from Bing web search engine and show that the CNN based model can achieve an accuracy of 77% and 76% for C# and Java respectively. Furthermore, we are also releasing the first large-scale real-world dataset of code search queries mined from Bing web search engine. We hope that the dataset will aid future research on code search.
Neural Knowledge Extraction From Cloud Service Incidents
Jul 15, 2020
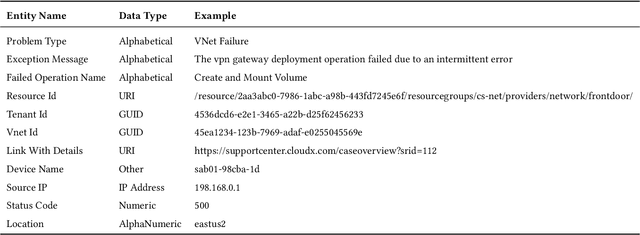

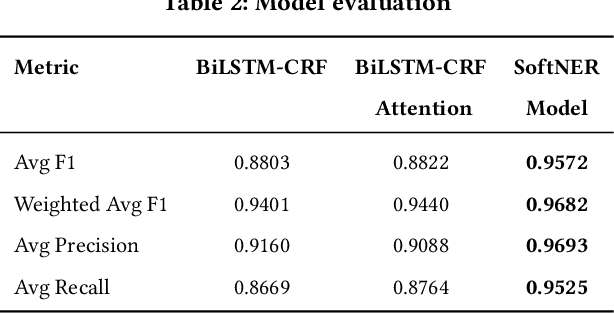
In the last decade, two paradigm shifts have reshaped the software industry - the move from boxed products to services and the widespread adoption of cloud computing. This has had a huge impact on the software development life cycle and the DevOps processes. Particularly, incident management has become critical for developing and operating large-scale services. Incidents are created to ensure timely communication of service issues and, also, their resolution. Prior work on incident management has been heavily focused on the challenges with incident triaging and de-duplication. In this work, we address the fundamental problem of structured knowledge extraction from service incidents. We have built SoftNER, a framework for unsupervised knowledge extraction from service incidents. We frame the knowledge extraction problem as a Named-entity Recognition task for extracting factual information. SoftNER leverages structural patterns like key,value pairs and tables for bootstrapping the training data. Further, we build a novel multi-task learning based BiLSTM-CRF model which leverages not just the semantic context but also the data-types for named-entity extraction. We have deployed SoftNER at Microsoft, a major cloud service provider and have evaluated it on more than 2 months of cloud incidents. We show that the unsupervised machine learning based approach has a high precision of 0.96. Our multi-task learning based deep learning model also outperforms the state of the art NER models. Lastly, using the knowledge extracted by SoftNER we are able to build significantly more accurate models for important downstream tasks like incident triaging.