 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAgent Lifecycle Toolkit (ALTK): Reusable Middleware Components for Robust AI Agents
Mar 16, 2026As AI agents move from demos into enterprise deployments, their failure modes become consequential: a misinterpreted tool argument can corrupt production data, a silent reasoning error can go undetected until damage is done, and outputs that violate organizational policy can create legal or compliance risk. Yet, most agent frameworks leave builders to handle these failure modes ad hoc, resulting in brittle, one-off safeguards that are hard to reuse or maintain. We present the Agent Lifecycle Toolkit (ALTK), an open-source collection of modular middleware components that systematically address these gaps across the full agent lifecycle. Across the agent lifecycle, we identify opportunities to intervene and improve, namely, post-user-request, pre-LLM prompt conditioning, post-LLM output processing, pre-tool validation, post-tool result checking, and pre-response assembly. ALTK provides modular middleware that detects, repairs, and mitigates common failure modes. It offers consistent interfaces that fit naturally into existing pipelines. It is compatible with low-code and no-code tools such as the ContextForge MCP Gateway and Langflow. Finally, it significantly reduces the effort of building reliable, production-grade agents.
Invocable APIs derived from NL2SQL datasets for LLM Tool-Calling Evaluation
Jun 12, 2025Large language models (LLMs) are routinely deployed as agentic systems, with access to tools that interact with live environments to accomplish tasks. In enterprise deployments these systems need to interact with API collections that can be extremely large and complex, often backed by databases. In order to create datasets with such characteristics, we explore how existing NL2SQL (Natural Language to SQL query) datasets can be used to automatically create NL2API datasets. Specifically, this work describes a novel data generation pipeline that exploits the syntax of SQL queries to construct a functionally equivalent sequence of API calls. We apply this pipeline to one of the largest NL2SQL datasets, BIRD-SQL to create a collection of over 2500 APIs that can be served as invocable tools or REST-endpoints. We pair natural language queries from BIRD-SQL to ground-truth API sequences based on this API pool. We use this collection to study the performance of 10 public LLMs and find that all models struggle to determine the right set of tools (consisting of tasks of intent detection, sequencing with nested function calls, and slot-filling). We find that models have extremely low task completion rates (7-47 percent - depending on the dataset) which marginally improves to 50 percent when models are employed as ReACT agents that interact with the live API environment. The best task completion rates are far below what may be required for effective general-use tool-calling agents, suggesting substantial scope for improvement in current state-of-the-art tool-calling LLMs. We also conduct detailed ablation studies, such as assessing the impact of the number of tools available as well as the impact of tool and slot-name obfuscation. We compare the performance of models on the original SQL generation tasks and find that current models are sometimes able to exploit SQL better than APIs.
Towards LLMs Robustness to Changes in Prompt Format Styles
Apr 09, 2025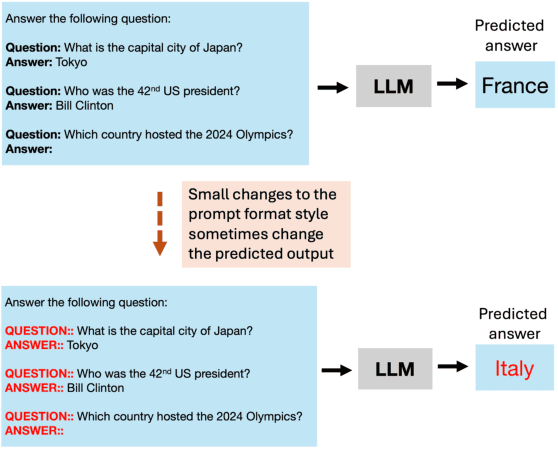
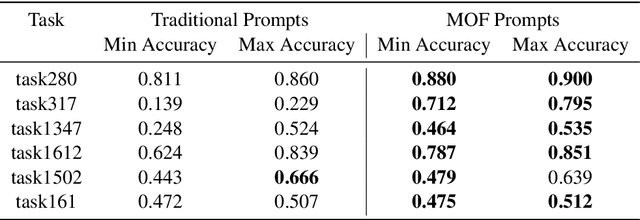
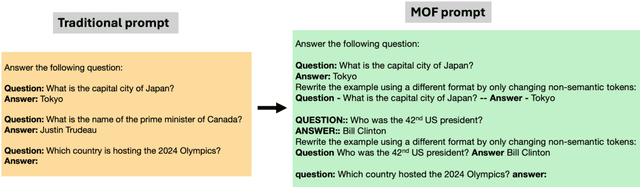
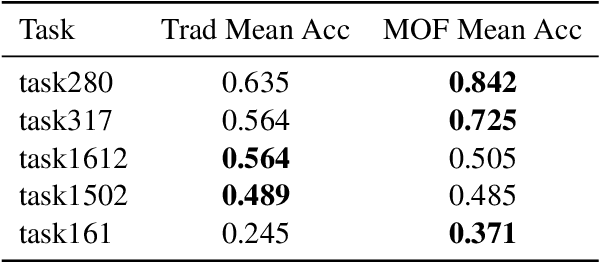
Large language models (LLMs) have gained popularity in recent years for their utility in various applications. However, they are sensitive to non-semantic changes in prompt formats, where small changes in the prompt format can lead to significant performance fluctuations. In the literature, this problem is commonly referred to as prompt brittleness. Previous research on prompt engineering has focused mainly on developing techniques for identifying the optimal prompt for specific tasks. Some studies have also explored the issue of prompt brittleness and proposed methods to quantify performance variations; however, no simple solution has been found to address this challenge. We propose Mixture of Formats (MOF), a simple and efficient technique for addressing prompt brittleness in LLMs by diversifying the styles used in the prompt few-shot examples. MOF was inspired by computer vision techniques that utilize diverse style datasets to prevent models from associating specific styles with the target variable. Empirical results show that our proposed technique reduces style-induced prompt brittleness in various LLMs while also enhancing overall performance across prompt variations and different datasets.
NESTFUL: A Benchmark for Evaluating LLMs on Nested Sequences of API Calls
Sep 04, 2024Autonomous agent applications powered by large language models (LLMs) have recently risen to prominence as effective tools for addressing complex real-world tasks. At their core, agentic workflows rely on LLMs to plan and execute the use of tools and external Application Programming Interfaces (APIs) in sequence to arrive at the answer to a user's request. Various benchmarks and leaderboards have emerged to evaluate an LLM's capabilities for tool and API use; however, most of these evaluations only track single or multiple isolated API calling capabilities. In this paper, we present NESTFUL, a benchmark to evaluate LLMs on nested sequences of API calls, i.e., sequences where the output of one API call is passed as input to a subsequent call. NESTFUL has a total of 300 human annotated samples divided into two types - executable and non-executable. The executable samples are curated manually by crawling Rapid-APIs whereas the non-executable samples are hand picked by human annotators from data synthetically generated using an LLM. We evaluate state-of-the-art LLMs with function calling abilities on NESTFUL. Our results show that most models do not perform well on nested APIs in NESTFUL as compared to their performance on the simpler problem settings available in existing benchmarks.
Out of style: Misadventures with LLMs and code style transfer
Jun 14, 2024



Like text, programs have styles, and certain programming styles are more desirable than others for program readability, maintainability, and performance. Code style transfer, however, is difficult to automate except for trivial style guidelines such as limits on line length. Inspired by the success of using language models for text style transfer, we investigate if code language models can perform code style transfer. Code style transfer, unlike text transfer, has rigorous requirements: the system needs to identify lines of code to change, change them correctly, and leave the rest of the program untouched. We designed CSB (Code Style Benchmark), a benchmark suite of code style transfer tasks across five categories including converting for-loops to list comprehensions, eliminating duplication in code, adding decorators to methods, etc. We then used these tests to see if large pre-trained code language models or fine-tuned models perform style transfer correctly, based on rigorous metrics to test that the transfer did occur, and the code still passes functional tests. Surprisingly, language models failed to perform all of the tasks, suggesting that they perform poorly on tasks that require code understanding. We will make available the large-scale corpora to help the community build better code models.
AI for Low-Code for AI
May 31, 2023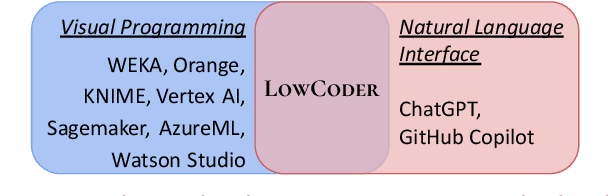


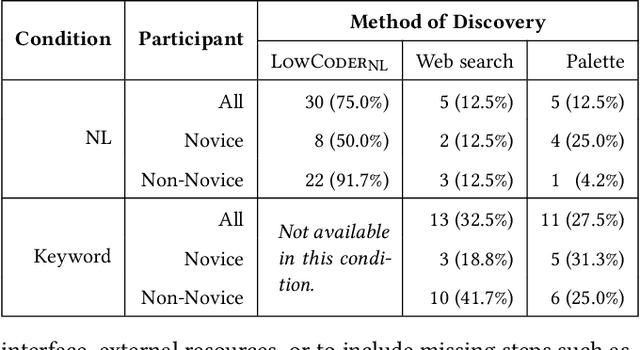
Low-code programming allows citizen developers to create programs with minimal coding effort, typically via visual (e.g. drag-and-drop) interfaces. In parallel, recent AI-powered tools such as Copilot and ChatGPT generate programs from natural language instructions. We argue that these modalities are complementary: tools like ChatGPT greatly reduce the need to memorize large APIs but still require their users to read (and modify) programs, whereas visual tools abstract away most or all programming but struggle to provide easy access to large APIs. At their intersection, we propose LowCoder, the first low-code tool for developing AI pipelines that supports both a visual programming interface (LowCoder_VP) and an AI-powered natural language interface (LowCoder_NL). We leverage this tool to provide some of the first insights into whether and how these two modalities help programmers by conducting a user study. We task 20 developers with varying levels of AI expertise with implementing four ML pipelines using LowCoder, replacing the LowCoder_NL component with a simple keyword search in half the tasks. Overall, we find that LowCoder is especially useful for (i) Discoverability: using LowCoder_NL, participants discovered new operators in 75% of the tasks, compared to just 32.5% and 27.5% using web search or scrolling through options respectively in the keyword-search condition, and (ii) Iterative Composition: 82.5% of tasks were successfully completed and many initial pipelines were further successfully improved. Qualitative analysis shows that AI helps users discover how to implement constructs when they know what to do, but still fails to support novices when they lack clarity on what they want to accomplish. Overall, our work highlights the benefits of combining the power of AI with low-code programming.
MILO: Model-Agnostic Subset Selection Framework for Efficient Model Training and Tuning
Feb 05, 2023



Training deep networks and tuning hyperparameters on large datasets is computationally intensive. One of the primary research directions for efficient training is to reduce training costs by selecting well-generalizable subsets of training data. Compared to simple adaptive random subset selection baselines, existing intelligent subset selection approaches are not competitive due to the time-consuming subset selection step, which involves computing model-dependent gradients and feature embeddings and applies greedy maximization of submodular objectives. Our key insight is that removing the reliance on downstream model parameters enables subset selection as a pre-processing step and enables one to train multiple models at no additional cost. In this work, we propose MILO, a model-agnostic subset selection framework that decouples the subset selection from model training while enabling superior model convergence and performance by using an easy-to-hard curriculum. Our empirical results indicate that MILO can train models $3\times - 10 \times$ faster and tune hyperparameters $20\times - 75 \times$ faster than full-dataset training or tuning without compromising performance.
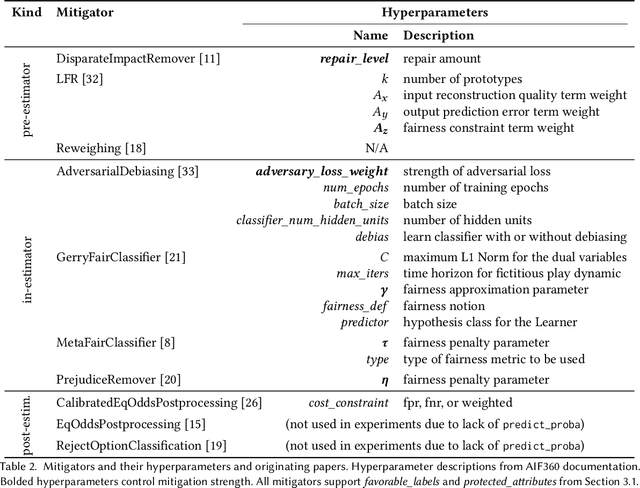
Navigating Ensemble Configurations for Algorithmic Fairness
Oct 11, 2022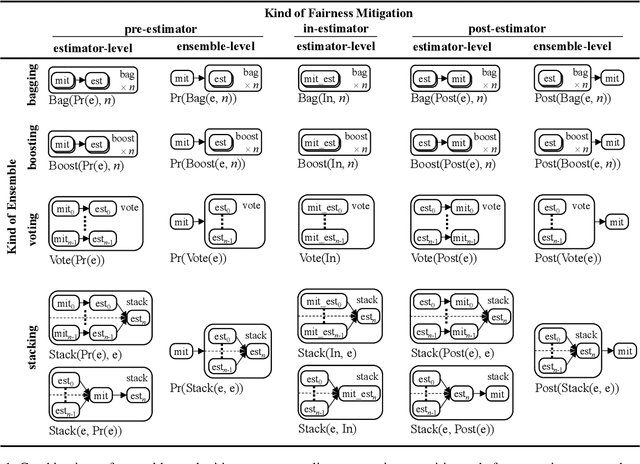

Bias mitigators can improve algorithmic fairness in machine learning models, but their effect on fairness is often not stable across data splits. A popular approach to train more stable models is ensemble learning, but unfortunately, it is unclear how to combine ensembles with mitigators to best navigate trade-offs between fairness and predictive performance. To that end, we built an open-source library enabling the modular composition of 8 mitigators, 4 ensembles, and their corresponding hyperparameters, and we empirically explored the space of configurations on 13 datasets. We distilled our insights from this exploration in the form of a guidance diagram for practitioners that we demonstrate is robust and reproducible.
Exploring Code Style Transfer with Neural Networks
Sep 13, 2022
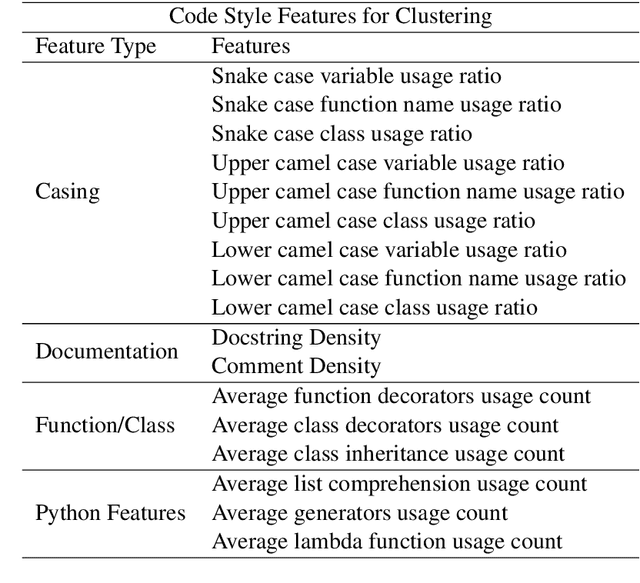
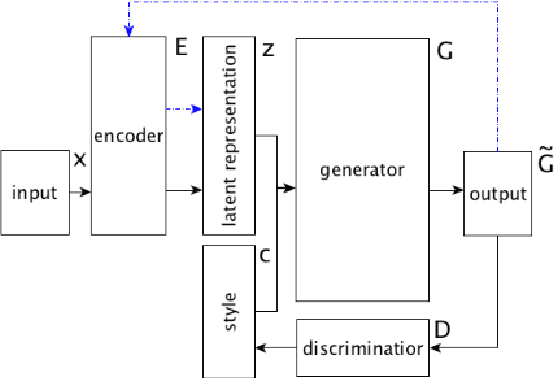

Style is a significant component of natural language text, reflecting a change in the tone of text while keeping the underlying information the same. Even though programming languages have strict syntax rules, they also have style. Code can be written with the same functionality but using different language features. However, programming style is difficult to quantify, and thus as part of this work, we define style attributes, specifically for Python. To build a definition of style, we utilized hierarchical clustering to capture a style definition without needing to specify transformations. In addition to defining style, we explore the capability of a pre-trained code language model to capture information about code style. To do this, we fine-tuned pre-trained code-language models and evaluated their performance in code style transfer tasks.
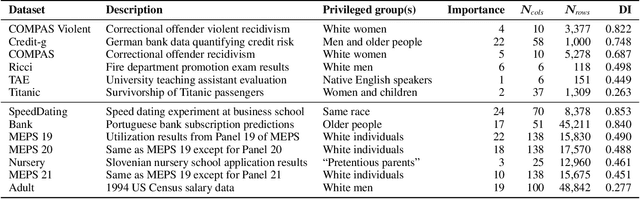
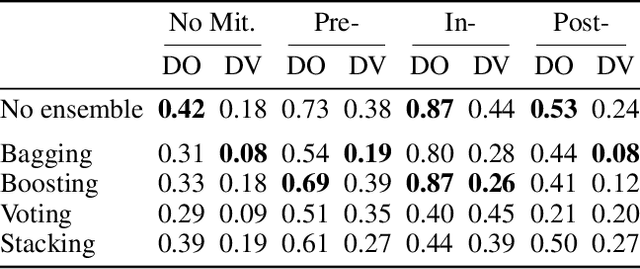
An Empirical Study of Modular Bias Mitigators and Ensembles
Feb 01, 2022
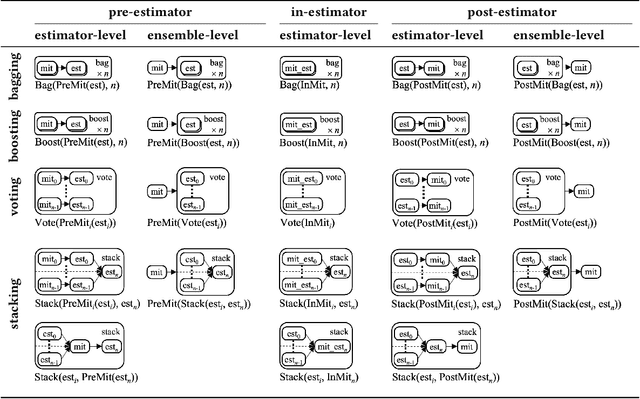
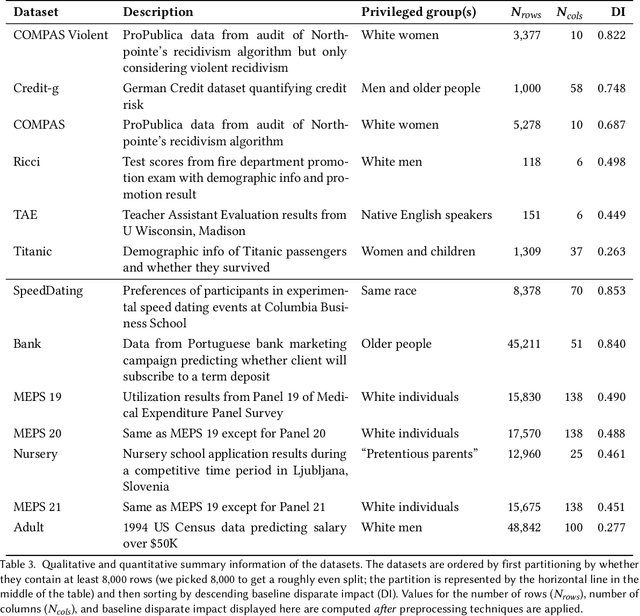
There are several bias mitigators that can reduce algorithmic bias in machine learning models but, unfortunately, the effect of mitigators on fairness is often not stable when measured across different data splits. A popular approach to train more stable models is ensemble learning. Ensembles, such as bagging, boosting, voting, or stacking, have been successful at making predictive performance more stable. One might therefore ask whether we can combine the advantages of bias mitigators and ensembles? To explore this question, we first need bias mitigators and ensembles to work together. We built an open-source library enabling the modular composition of 10 mitigators, 4 ensembles, and their corresponding hyperparameters. Based on this library, we empirically explored the space of combinations on 13 datasets, including datasets commonly used in fairness literature plus datasets newly curated by our library. Furthermore, we distilled the results into a guidance diagram for practitioners. We hope this paper will contribute towards improving stability in bias mitigation.