 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards LLMs Robustness to Changes in Prompt Format Styles
Apr 09, 2025Large language models (LLMs) have gained popularity in recent years for their utility in various applications. However, they are sensitive to non-semantic changes in prompt formats, where small changes in the prompt format can lead to significant performance fluctuations. In the literature, this problem is commonly referred to as prompt brittleness. Previous research on prompt engineering has focused mainly on developing techniques for identifying the optimal prompt for specific tasks. Some studies have also explored the issue of prompt brittleness and proposed methods to quantify performance variations; however, no simple solution has been found to address this challenge. We propose Mixture of Formats (MOF), a simple and efficient technique for addressing prompt brittleness in LLMs by diversifying the styles used in the prompt few-shot examples. MOF was inspired by computer vision techniques that utilize diverse style datasets to prevent models from associating specific styles with the target variable. Empirical results show that our proposed technique reduces style-induced prompt brittleness in various LLMs while also enhancing overall performance across prompt variations and different datasets.
NESTFUL: A Benchmark for Evaluating LLMs on Nested Sequences of API Calls
Sep 04, 2024Autonomous agent applications powered by large language models (LLMs) have recently risen to prominence as effective tools for addressing complex real-world tasks. At their core, agentic workflows rely on LLMs to plan and execute the use of tools and external Application Programming Interfaces (APIs) in sequence to arrive at the answer to a user's request. Various benchmarks and leaderboards have emerged to evaluate an LLM's capabilities for tool and API use; however, most of these evaluations only track single or multiple isolated API calling capabilities. In this paper, we present NESTFUL, a benchmark to evaluate LLMs on nested sequences of API calls, i.e., sequences where the output of one API call is passed as input to a subsequent call. NESTFUL has a total of 300 human annotated samples divided into two types - executable and non-executable. The executable samples are curated manually by crawling Rapid-APIs whereas the non-executable samples are hand picked by human annotators from data synthetically generated using an LLM. We evaluate state-of-the-art LLMs with function calling abilities on NESTFUL. Our results show that most models do not perform well on nested APIs in NESTFUL as compared to their performance on the simpler problem settings available in existing benchmarks.
Granite-Function Calling Model: Introducing Function Calling Abilities via Multi-task Learning of Granular Tasks
Jun 27, 2024



Large language models (LLMs) have recently shown tremendous promise in serving as the backbone to agentic systems, as demonstrated by their performance in multi-faceted, challenging benchmarks like SWE-Bench and Agent-Bench. However, to realize the true potential of LLMs as autonomous agents, they must learn to identify, call, and interact with external tools and application program interfaces (APIs) to complete complex tasks. These tasks together are termed function calling. Endowing LLMs with function calling abilities leads to a myriad of advantages, such as access to current and domain-specific information in databases and knowledge sources, and the ability to outsource tasks that can be reliably performed by tools, e.g., a Python interpreter or calculator. While there has been significant progress in function calling with LLMs, there is still a dearth of open models that perform on par with proprietary LLMs like GPT, Claude, and Gemini. Therefore, in this work, we introduce the GRANITE-20B-FUNCTIONCALLING model under an Apache 2.0 license. The model is trained using a multi-task training approach on seven fundamental tasks encompassed in function calling, those being Nested Function Calling, Function Chaining, Parallel Functions, Function Name Detection, Parameter-Value Pair Detection, Next-Best Function, and Response Generation. We present a comprehensive evaluation on multiple out-of-domain datasets comparing GRANITE-20B-FUNCTIONCALLING to more than 15 other best proprietary and open models. GRANITE-20B-FUNCTIONCALLING provides the best performance among all open models on the Berkeley Function Calling Leaderboard and fourth overall. As a result of the diverse tasks and datasets used for training our model, we show that GRANITE-20B-FUNCTIONCALLING has better generalizability on multiple tasks in seven different evaluation datasets.
TESS: A Multi-intent Parser for Conversational Multi-Agent Systems with Decentralized Natural Language Understanding Models
Dec 19, 2023Chatbots have become one of the main pathways for the delivery of business automation tools. Multi-agent systems offer a framework for designing chatbots at scale, making it easier to support complex conversations that span across multiple domains as well as enabling developers to maintain and expand their capabilities incrementally over time. However, multi-agent systems complicate the natural language understanding (NLU) of user intents, especially when they rely on decentralized NLU models: some utterances (termed single intent) may invoke a single agent while others (termed multi-intent) may explicitly invoke multiple agents. Without correctly parsing multi-intent inputs, decentralized NLU approaches will not achieve high prediction accuracy. In this paper, we propose an efficient parsing and orchestration pipeline algorithm to service multi-intent utterances from the user in the context of a multi-agent system. Our proposed approach achieved comparable performance to competitive deep learning models on three different datasets while being up to 48 times faster.
TaskDiff: A Similarity Metric for Task-Oriented Conversations
Oct 25, 2023The popularity of conversational digital assistants has resulted in the availability of large amounts of conversational data which can be utilized for improved user experience and personalized response generation. Building these assistants using popular large language models like ChatGPT also require additional emphasis on prompt engineering and evaluation methods. Textual similarity metrics are a key ingredient for such analysis and evaluations. While many similarity metrics have been proposed in the literature, they have not proven effective for task-oriented conversations as they do not take advantage of unique conversational features. To address this gap, we present TaskDiff, a novel conversational similarity metric that utilizes different dialogue components (utterances, intents, and slots) and their distributions to compute similarity. Extensive experimental evaluation of TaskDiff on a benchmark dataset demonstrates its superior performance and improved robustness over other related approaches.
A Case for Business Process-Specific Foundation Models
Oct 26, 2022

The inception of large language models has helped advance state-of-the-art performance on numerous natural language tasks. This has also opened the door for the development of foundation models for other domains and data modalities such as images, code, and music. In this paper, we argue that business process data representations have unique characteristics that warrant the development of a new class of foundation models to handle tasks like process mining, optimization, and decision making. These models should also tackle the unique challenges of applying AI to business processes which include data scarcity, multi-modal representations, domain specific terminology, and privacy concerns.
Extending LIME for Business Process Automation
Aug 09, 2021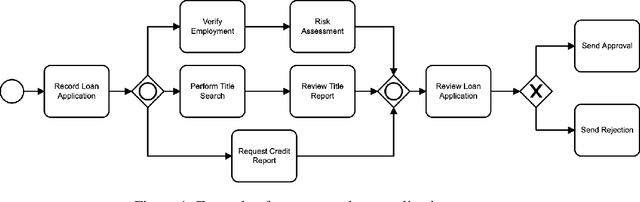

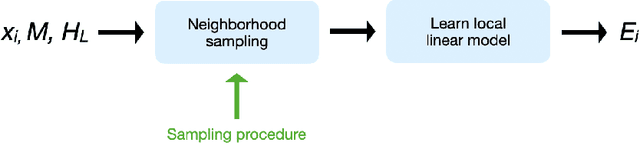
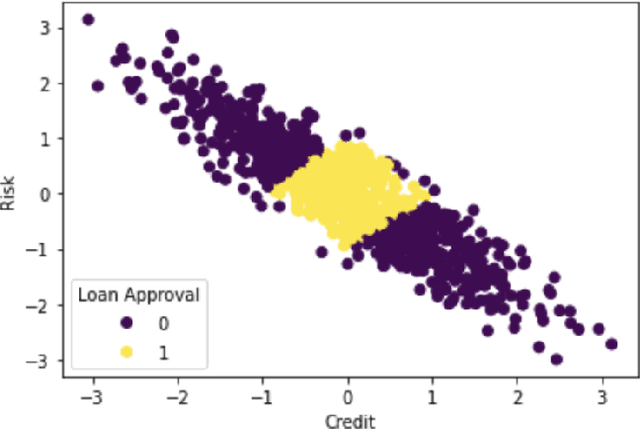
AI business process applications automate high-stakes business decisions where there is an increasing demand to justify or explain the rationale behind algorithmic decisions. Business process applications have ordering or constraints on tasks and feature values that cause lightweight, model-agnostic, existing explanation methods like LIME to fail. In response, we propose a local explanation framework extending LIME for explaining AI business process applications. Empirical evaluation of our extension underscores the advantage of our approach in the business process setting.
Explainable Composition of Aggregated Assistants
Nov 21, 2020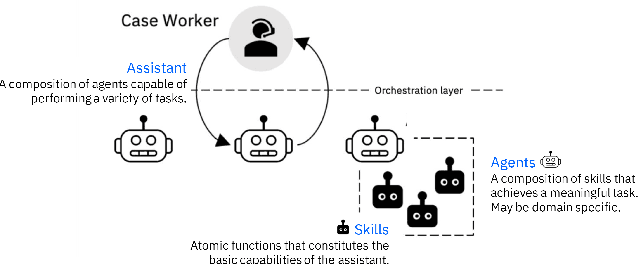
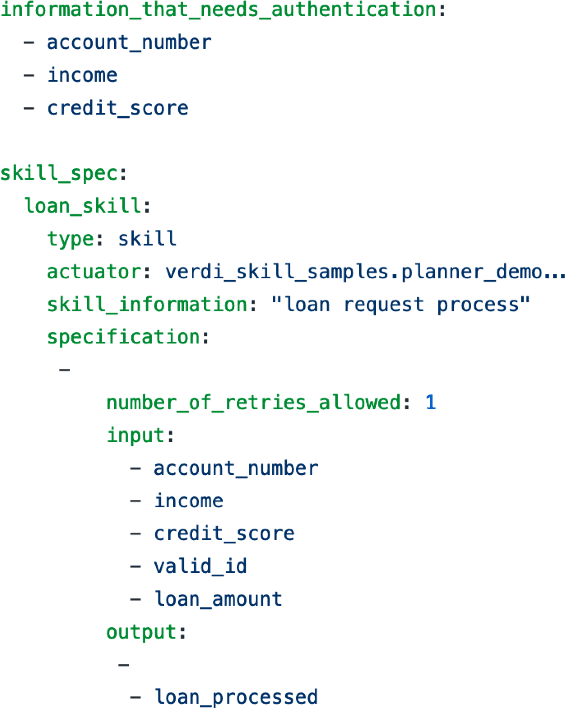
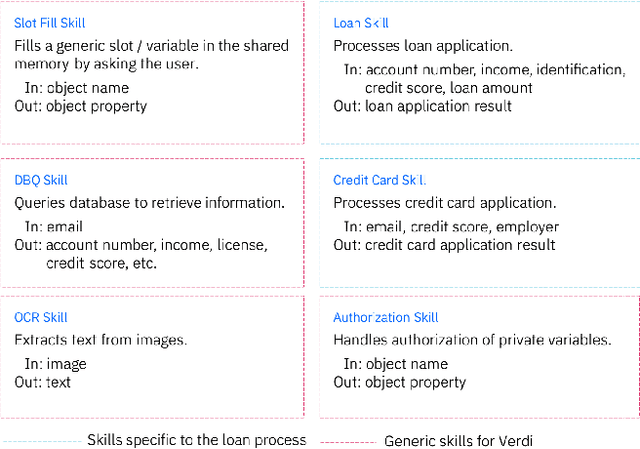

A new design of an AI assistant that has become increasingly popular is that of an "aggregated assistant" -- realized as an orchestrated composition of several individual skills or agents that can each perform atomic tasks. In this paper, we will talk about the role of planning in the automated composition of such assistants and explore how concepts in automated planning can help to establish transparency of the inner workings of the assistant to the end-user.
From Robotic Process Automation to Intelligent Process Automation: Emerging Trends
Jul 27, 2020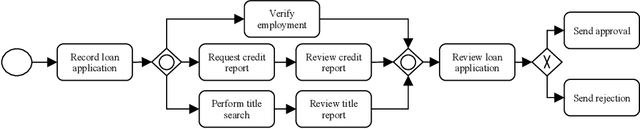
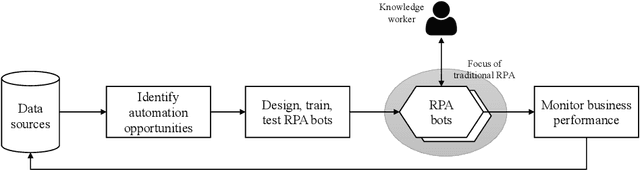
In this survey, we study how recent advances in machine intelligence are disrupting the world of business processes. Over the last decade, there has been steady progress towards the automation of business processes under the umbrella of ``robotic process automation'' (RPA). However, we are currently at an inflection point in this evolution, as a new paradigm called ``Intelligent Process Automation'' (IPA) emerges, bringing machine learning (ML) and artificial intelligence (AI) technologies to bear in order to improve business process outcomes. The purpose of this paper is to provide a survey of this emerging theme and identify key open research challenges at the intersection of AI and business processes. We hope that this emerging theme will spark engaging conversations at the RPA Forum.
A Conversational Digital Assistant for Intelligent Process Automation
Jul 27, 2020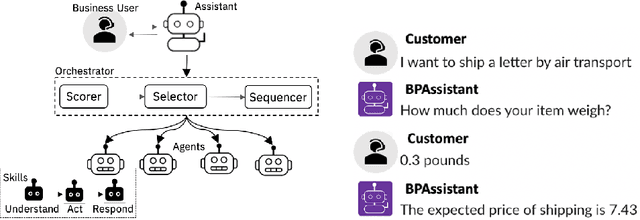

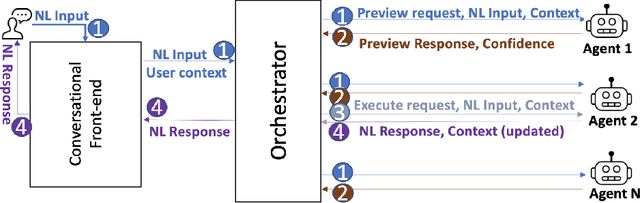

Robotic process automation (RPA) has emerged as the leading approach to automate tasks in business processes. Moving away from back-end automation, RPA automated the mouse-click on user interfaces; this outside-in approach reduced the overhead of updating legacy software. However, its many shortcomings, namely its lack of accessibility to business users, have prevented its widespread adoption in highly regulated industries. In this work, we explore interactive automation in the form of a conversational digital assistant. It allows business users to interact with and customize their automation solutions through natural language. The framework, which creates such assistants, relies on a multi-agent orchestration model and conversational wrappers for autonomous agents including RPAs. We demonstrate the effectiveness of our proposed approach on a loan approval business process and a travel preapproval business process.