 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTESS: A Multi-intent Parser for Conversational Multi-Agent Systems with Decentralized Natural Language Understanding Models
Dec 19, 2023Chatbots have become one of the main pathways for the delivery of business automation tools. Multi-agent systems offer a framework for designing chatbots at scale, making it easier to support complex conversations that span across multiple domains as well as enabling developers to maintain and expand their capabilities incrementally over time. However, multi-agent systems complicate the natural language understanding (NLU) of user intents, especially when they rely on decentralized NLU models: some utterances (termed single intent) may invoke a single agent while others (termed multi-intent) may explicitly invoke multiple agents. Without correctly parsing multi-intent inputs, decentralized NLU approaches will not achieve high prediction accuracy. In this paper, we propose an efficient parsing and orchestration pipeline algorithm to service multi-intent utterances from the user in the context of a multi-agent system. Our proposed approach achieved comparable performance to competitive deep learning models on three different datasets while being up to 48 times faster.
Guided Demonstrations Using Automated Excuse Generation
Nov 30, 2023Teaching task-level directives to robots via demonstration is a popular tool to expand the robot's capabilities to interact with its environment. While current learning from demonstration systems primarily focuses on abstracting the task-level knowledge to the robot, these systems lack the ability to understand which part of the task can be already solved given the robot's prior knowledge. Therefore, instead of only requiring demonstrations of the missing pieces, these systems will require a demonstration of the complete task, which is cumbersome, repetitive, and can discourage people from helping the robot by performing the demonstrations. Therefore, we propose to use the notion of "excuses" to identify the smallest change in the robot state that makes a task, currently not solvable by the robot, solvable -- as a means to solicit more targeted demonstrations from a human. These excuses are generated automatically using combinatorial search over possible changes that can be made to the robot's state and choosing the minimum changes that make it solvable. These excuses then serve as guidance for the demonstrator who can use it to decide what to demonstrate to the robot in order to make this requested change possible, thereby making the original task solvable for the robot without having to demonstrate it in its entirety. By working with symbolic state descriptions, the excuses can be directly communicated and intuitively understood by a human demonstrator. We show empirically and in a user study that the use of excuses reduces the demonstration time by 54% and leads to a 74% reduction in demonstration size.
Towards More Likely Models for AI Planning
Nov 22, 2023



This is the first work to look at the application of large language models (LLMs) for the purpose of model space edits in automated planning tasks. To set the stage for this sangam, we explore two different flavors of model space problems that have been studied in the AI planning literature and explore the effect of an LLM on those tasks. We empirically demonstrate how the performance of an LLM contrasts with combinatorial search (CS) - an approach that has been traditionally used to solve model space tasks in planning, both with the LLM in the role of a standalone model space reasoner as well as in the role of a statistical signal in concert with the CS approach as part of a two-stage process. Our experiments show promising results suggesting further forays of LLMs into the exciting world of model space reasoning for planning tasks in the future.
TOBY: A Tool for Exploring Data in Academic Survey Papers
Jun 13, 2023This paper describes TOBY, a visualization tool that helps a user explore the contents of an academic survey paper. The visualization consists of four components: a hierarchical view of taxonomic data in the survey, a document similarity view in the space of taxonomic classes, a network view of citations, and a new paper recommendation tool. In this paper, we will discuss these features in the context of three separate deployments of the tool.
MACQ: A Holistic View of Model Acquisition Techniques
Jun 14, 2022
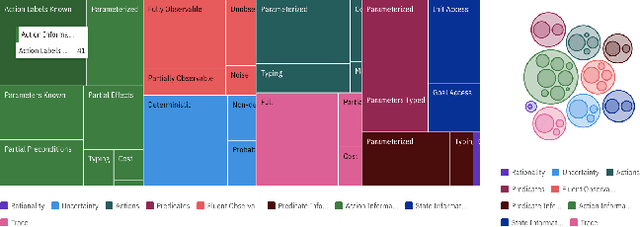
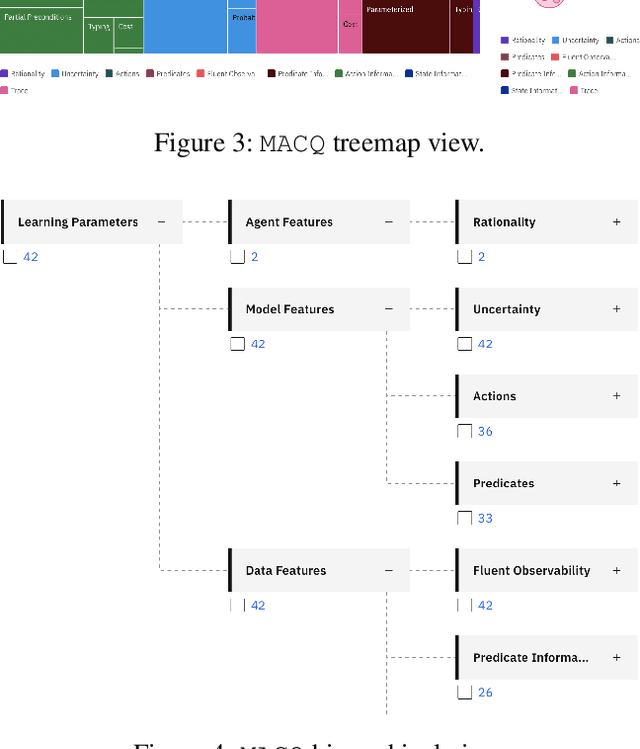
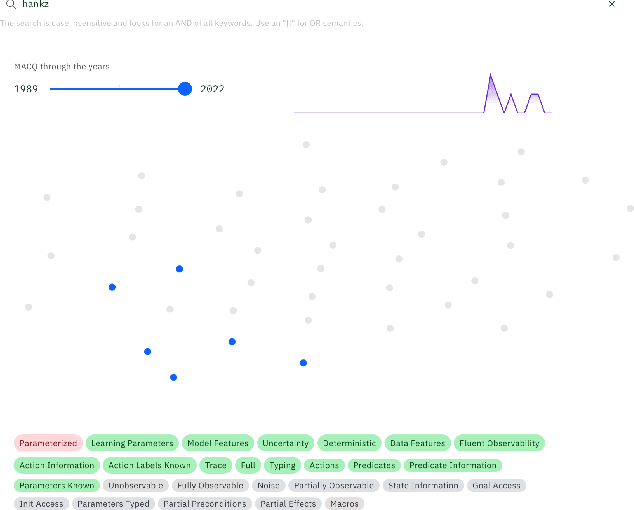
For over three decades, the planning community has explored countless methods for data-driven model acquisition. These range in sophistication (e.g., simple set operations to full-blown reformulations), methodology (e.g., logic-based vs. planing-based), and assumptions (e.g., fully vs. partially observable). With no fewer than 43 publications in the space, it can be overwhelming to understand what approach could or should be applied in a new setting. We present a holistic characterization of the action model acquisition space and further introduce a unifying framework for automated action model acquisition. We have re-implemented some of the landmark approaches in the area, and our characterization of all the techniques offers deep insight into the research opportunities that remain; i.e., those settings where no technique is capable of solving.
Virtual, Augmented, and Mixed Reality for Human-Robot Interaction: A Survey and Virtual Design Element Taxonomy
Feb 23, 2022
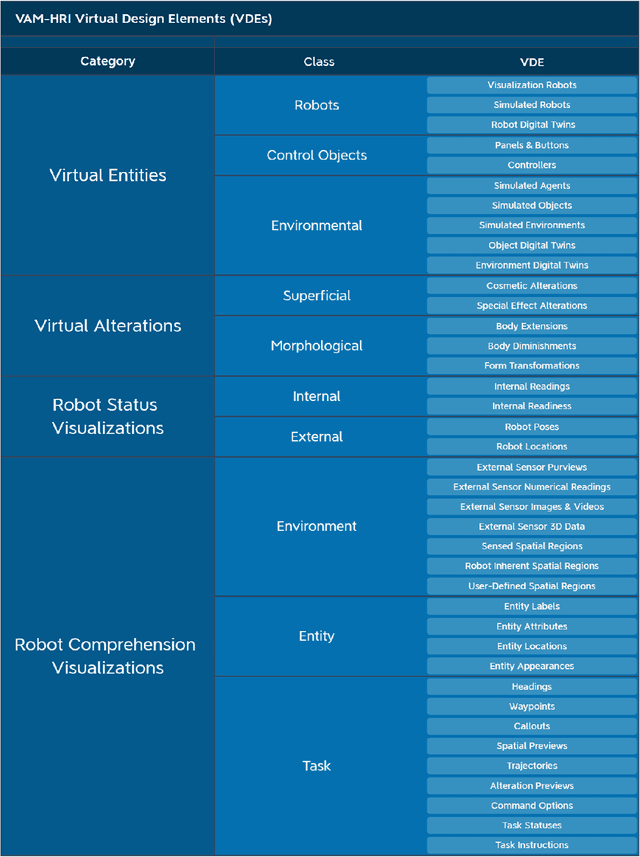


Virtual, Augmented, and Mixed Reality for Human-Robot Interaction (VAM-HRI) has been gaining considerable attention in research in recent years. However, the HRI community lacks a set of shared terminology and framework for characterizing aspects of mixed reality interfaces, presenting serious problems for future research. Therefore, it is important to have a common set of terms and concepts that can be used to precisely describe and organize the diverse array of work being done within the field. In this paper, we present a novel taxonomic framework for different types of VAM-HRI interfaces, composed of four main categories of virtual design elements (VDEs). We present and justify our taxonomy and explain how its elements have been developed over the last 30 years as well as the current directions VAM-HRI is headed in the coming decade.
COVID-19 India Dataset: Parsing Detailed COVID-19 Data in Daily Health Bulletins from States in India
Sep 27, 2021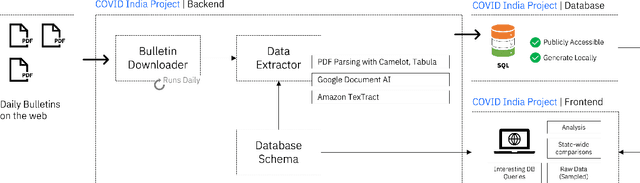
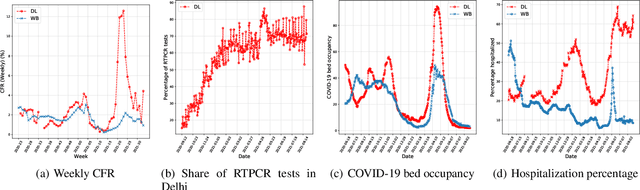
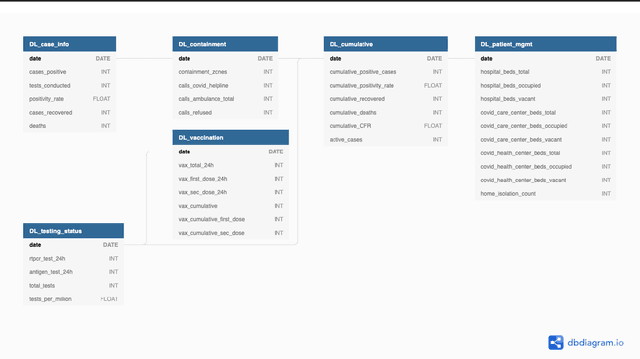
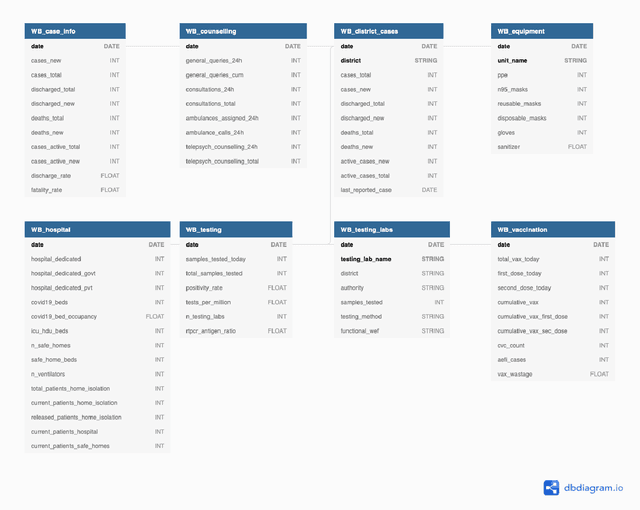
While India remains one of the hotspots of the COVID-19 pandemic, data about the pandemic from the country has proved to be largely inaccessible for use at scale. Much of the data exists in an unstructured form on the web, and limited aspects of such data are available through public APIs maintained manually through volunteer efforts. This has proved to be difficult both in terms of ease of access to detailed data as well as with regards to the maintenance of manual data-keeping over time. This paper reports on a recently launched project aimed at automating the extraction of such data from public health bulletins with the help of a combination of classical PDF parsers as well as state-of-the-art ML-based documents extraction APIs. In this paper, we will describe the automated data-extraction technique, the nature of the generated data, and exciting avenues of ongoing work.
NeurIPS 2020 NLC2CMD Competition: Translating Natural Language to Bash Commands
Mar 03, 2021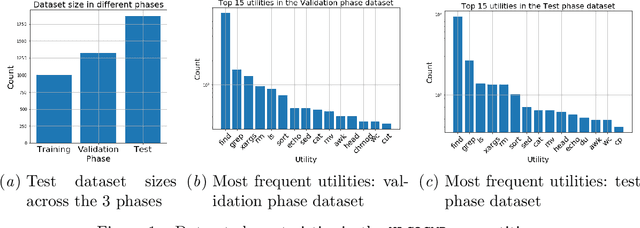
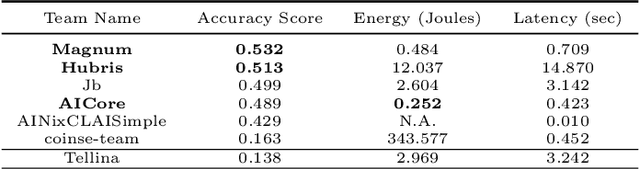

The NLC2CMD Competition hosted at NeurIPS 2020 aimed to bring the power of natural language processing to the command line. Participants were tasked with building models that can transform descriptions of command line tasks in English to their Bash syntax. This is a report on the competition with details of the task, metrics, data, attempted solutions, and lessons learned.
A Bayesian Account of Measures of Interpretability in Human-AI Interaction
Nov 22, 2020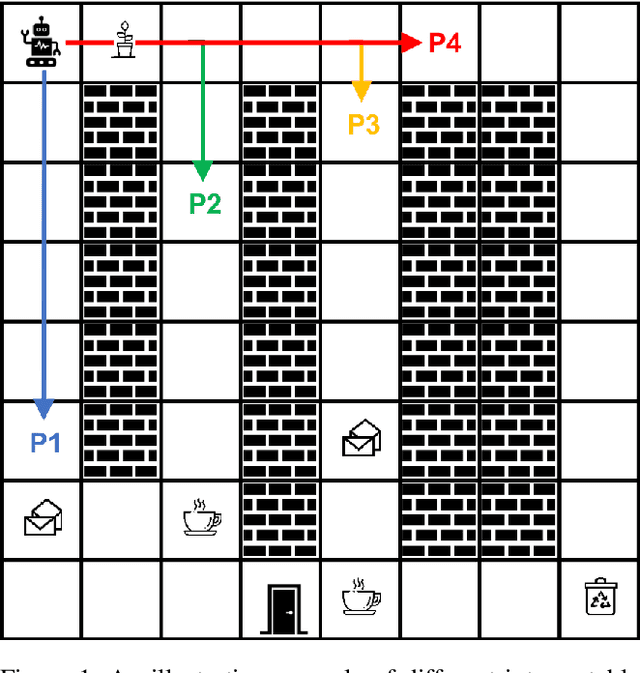
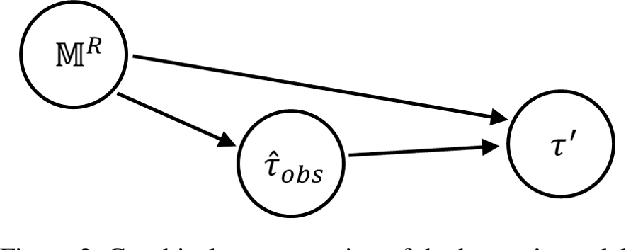
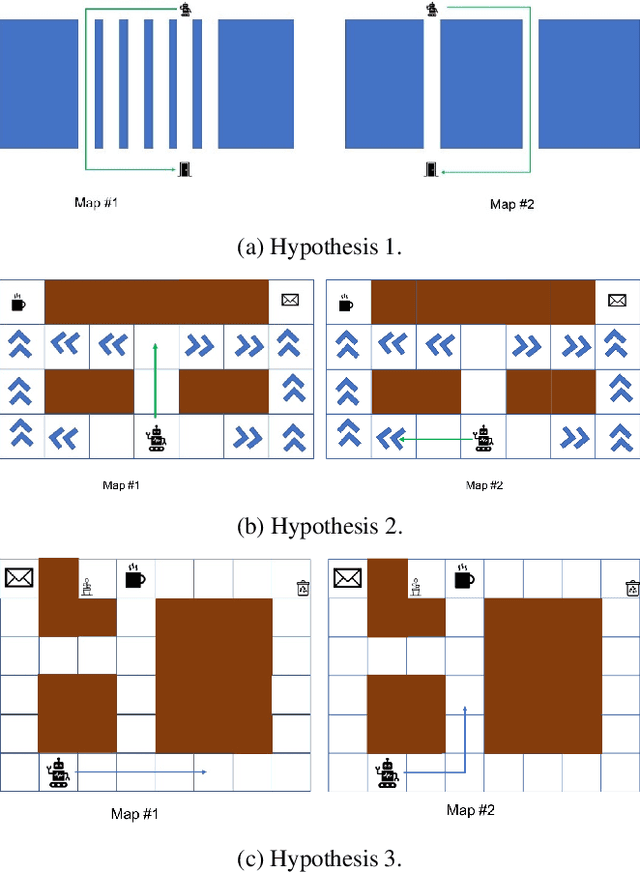
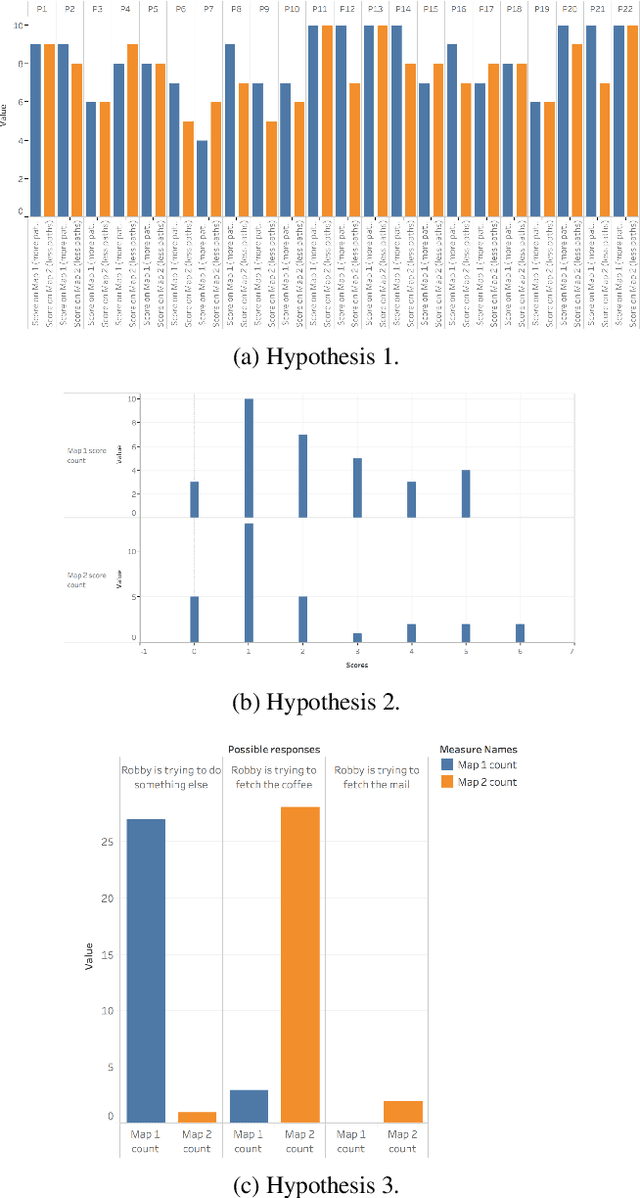
Existing approaches for the design of interpretable agent behavior consider different measures of interpretability in isolation. In this paper we posit that, in the design and deployment of human-aware agents in the real world, notions of interpretability are just some among many considerations; and the techniques developed in isolation lack two key properties to be useful when considered together: they need to be able to 1) deal with their mutually competing properties; and 2) an open world where the human is not just there to interpret behavior in one specific form. To this end, we consider three well-known instances of interpretable behavior studied in existing literature -- namely, explicability, legibility, and predictability -- and propose a revised model where all these behaviors can be meaningfully modeled together. We will highlight interesting consequences of this unified model and motivate, through results of a user study, why this revision is necessary.
Explainable Composition of Aggregated Assistants
Nov 21, 2020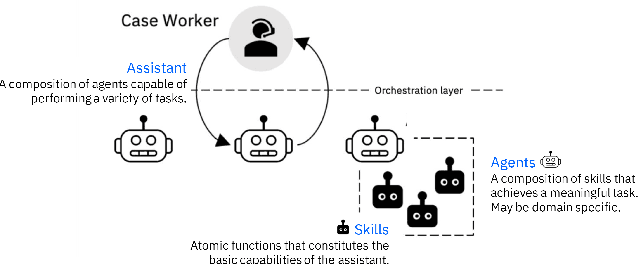
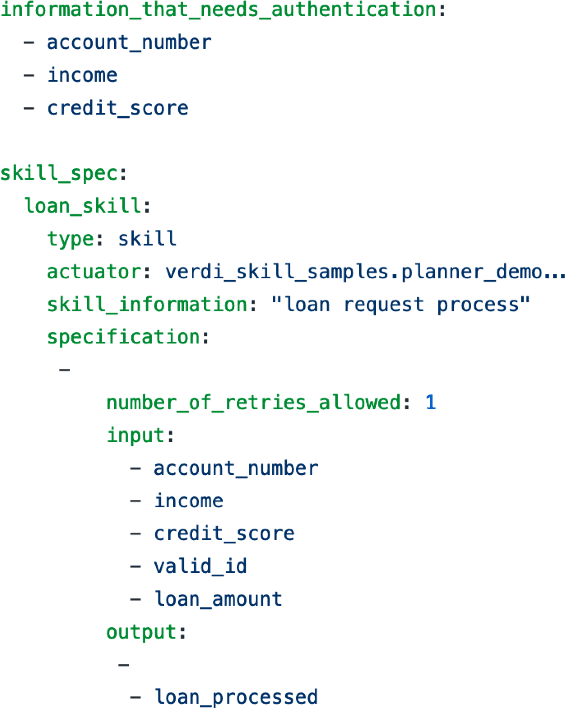
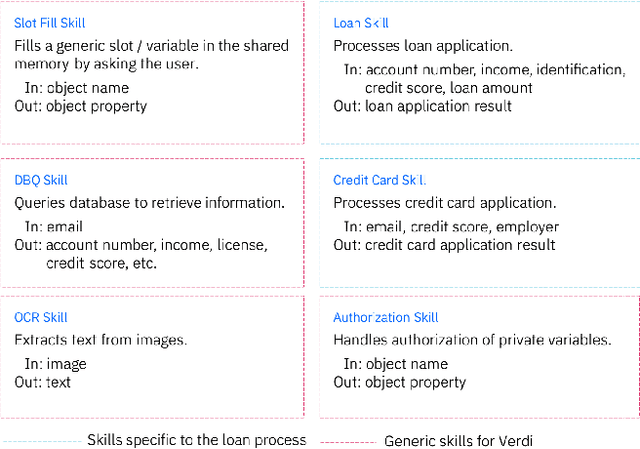

A new design of an AI assistant that has become increasingly popular is that of an "aggregated assistant" -- realized as an orchestrated composition of several individual skills or agents that can each perform atomic tasks. In this paper, we will talk about the role of planning in the automated composition of such assistants and explore how concepts in automated planning can help to establish transparency of the inner workings of the assistant to the end-user.