 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeChatGPT Prompt Patterns for Improving Code Quality, Refactoring, Requirements Elicitation, and Software Design
Mar 11, 2023

This paper presents prompt design techniques for software engineering, in the form of patterns, to solve common problems when using large language models (LLMs), such as ChatGPT to automate common software engineering activities, such as ensuring code is decoupled from third-party libraries and simulating a web application API before it is implemented. This paper provides two contributions to research on using LLMs for software engineering. First, it provides a catalog of patterns for software engineering that classifies patterns according to the types of problems they solve. Second, it explores several prompt patterns that have been applied to improve requirements elicitation, rapid prototyping, code quality, refactoring, and system design.
A Prompt Pattern Catalog to Enhance Prompt Engineering with ChatGPT
Feb 21, 2023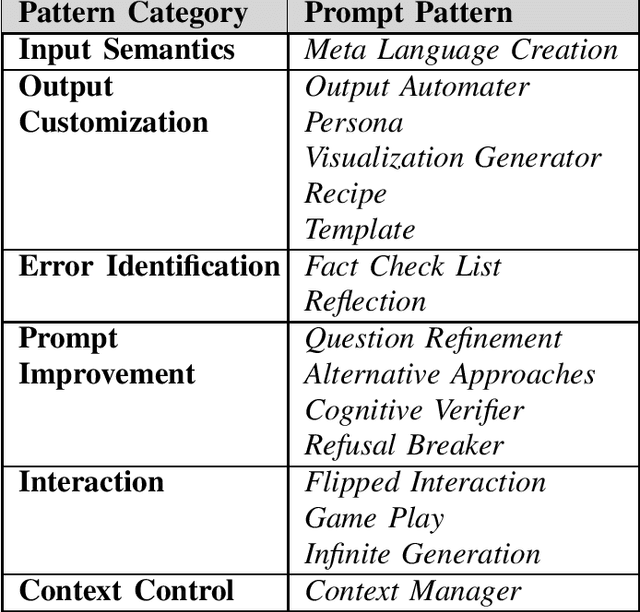
Prompt engineering is an increasingly important skill set needed to converse effectively with large language models (LLMs), such as ChatGPT. Prompts are instructions given to an LLM to enforce rules, automate processes, and ensure specific qualities (and quantities) of generated output. Prompts are also a form of programming that can customize the outputs and interactions with an LLM. This paper describes a catalog of prompt engineering techniques presented in pattern form that have been applied to solve common problems when conversing with LLMs. Prompt patterns are a knowledge transfer method analogous to software patterns since they provide reusable solutions to common problems faced in a particular context, i.e., output generation and interaction when working with LLMs. This paper provides the following contributions to research on prompt engineering that apply LLMs to automate software development tasks. First, it provides a framework for documenting patterns for structuring prompts to solve a range of problems so that they can be adapted to different domains. Second, it presents a catalog of patterns that have been applied successfully to improve the outputs of LLM conversations. Third, it explains how prompts can be built from multiple patterns and illustrates prompt patterns that benefit from combination with other prompt patterns.
NL2CMD: An Updated Workflow for Natural Language to Bash Commands Translation
Feb 15, 2023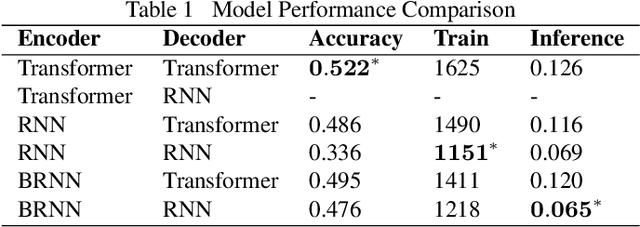
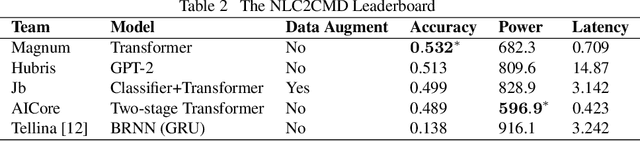
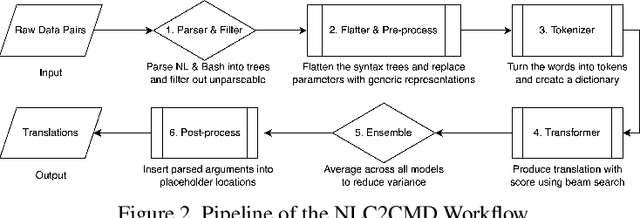
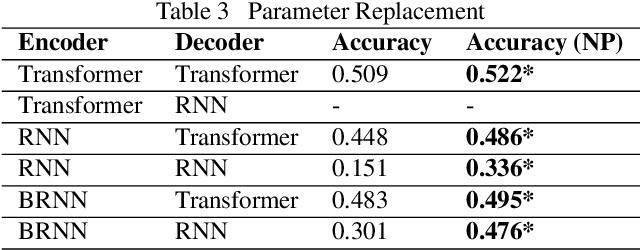
Translating natural language into Bash Commands is an emerging research field that has gained attention in recent years. Most efforts have focused on producing more accurate translation models. To the best of our knowledge, only two datasets are available, with one based on the other. Both datasets involve scraping through known data sources (through platforms like stack overflow, crowdsourcing, etc.) and hiring experts to validate and correct either the English text or Bash Commands. This paper provides two contributions to research on synthesizing Bash Commands from scratch. First, we describe a state-of-the-art translation model used to generate Bash Commands from the corresponding English text. Second, we introduce a new NL2CMD dataset that is automatically generated, involves minimal human intervention, and is over six times larger than prior datasets. Since the generation pipeline does not rely on existing Bash Commands, the distribution and types of commands can be custom adjusted. Our empirical results show how the scale and diversity of our dataset can offer unique opportunities for semantic parsing researchers.
Real-time Speech Interruption Analysis: From Cloud to Client Deployment
Oct 24, 2022



Meetings are an essential form of communication for all types of organizations, and remote collaboration systems have been much more widely used since the COVID-19 pandemic. One major issue with remote meetings is that it is challenging for remote participants to interrupt and speak. We have recently developed the first speech interruption analysis model, which detects failed speech interruptions, shows very promising performance, and is being deployed in the cloud. To deliver this feature in a more cost-efficient and environment-friendly way, we reduced the model complexity and size to ship the WavLM_SI model in client devices. In this paper, we first describe how we successfully improved the True Positive Rate (TPR) at a 1% False Positive Rate (FPR) from 50.9% to 68.3% for the failed speech interruption detection model by training on a larger dataset and fine-tuning. We then shrank the model size from 222.7 MB to 9.3 MB with an acceptable loss in accuracy and reduced the complexity from 31.2 GMACS (Giga Multiply-Accumulate Operations per Second) to 4.3 GMACS. We also estimated the environmental impact of the complexity reduction, which can be used as a general guideline for large Transformer-based models, and thus make those models more accessible with less computation overhead.
Deep Learning Models on CPUs: A Methodology for Efficient Training
Jun 20, 2022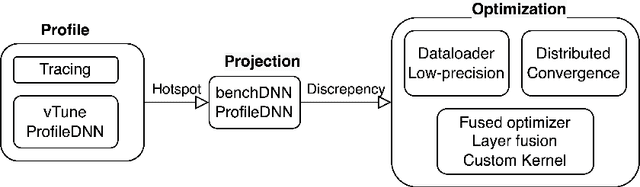

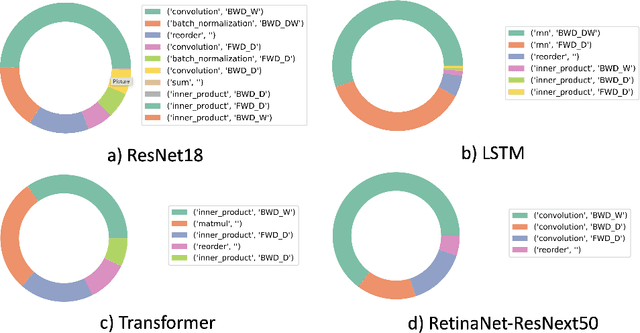
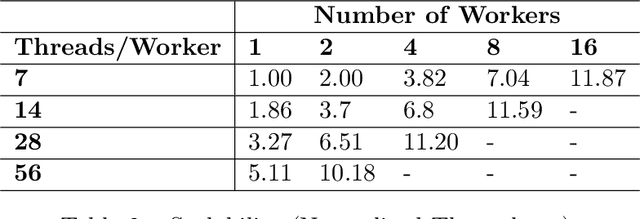
GPUs have been favored for training deep learning models due to their highly parallelized architecture. As a result, most studies on training optimization focus on GPUs. There is often a trade-off, however, between cost and efficiency when deciding on how to choose the proper hardware for training. In particular, CPU servers can be beneficial if training on CPUs was more efficient, as they incur fewer hardware update costs and better utilizing existing infrastructure. This paper makes several contributions to research on training deep learning models using CPUs. First, it presents a method for optimizing the training of deep learning models on Intel CPUs and a toolkit called ProfileDNN, which we developed to improve performance profiling. Second, we describe a generic training optimization method that guides our workflow and explores several case studies where we identified performance issues and then optimized the Intel Extension for PyTorch, resulting in an overall 2x training performance increase for the RetinaNet-ResNext50 model. Third, we show how to leverage the visualization capabilities of ProfileDNN, which enabled us to pinpoint bottlenecks and create a custom focal loss kernel that was two times faster than the official reference PyTorch implementation.
SA-SASV: An End-to-End Spoof-Aggregated Spoofing-Aware Speaker Verification System
Mar 24, 2022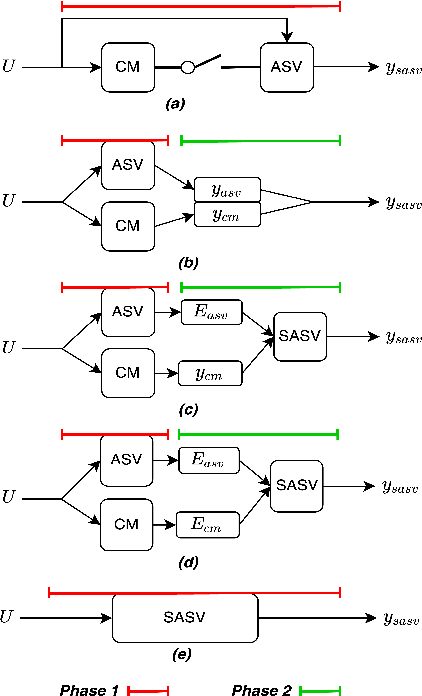
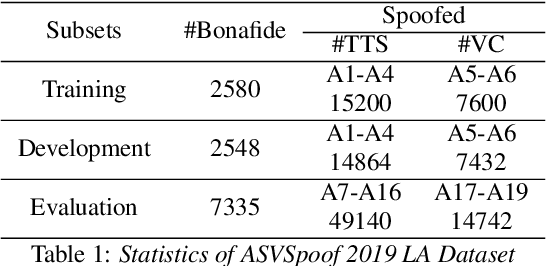
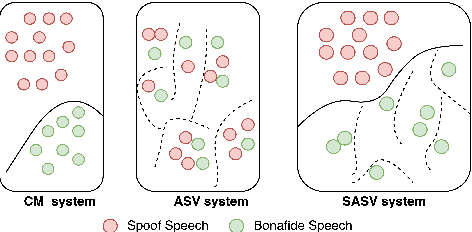
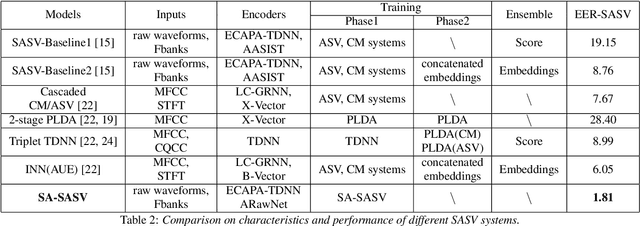
Research in the past several years has boosted the performance of automatic speaker verification systems and countermeasure systems to deliver low Equal Error Rates (EERs) on each system. However, research on joint optimization of both systems is still limited. The Spoofing-Aware Speaker Verification (SASV) 2022 challenge was proposed to encourage the development of integrated SASV systems with new metrics to evaluate joint model performance. This paper proposes an ensemble-free end-to-end solution, known as Spoof-Aggregated-SASV (SA-SASV) to build a SASV system with multi-task classifiers, which are optimized by multiple losses and has more flexible requirements in training set. The proposed system is trained on the ASVSpoof 2019 LA dataset, a spoof verification dataset with small number of bonafide speakers. Results of SASV-EER indicate that the model performance can be further improved by training in complete automatic speaker verification and countermeasure datasets.
FastAudio: A Learnable Audio Front-End for Spoof Speech Detection
Sep 06, 2021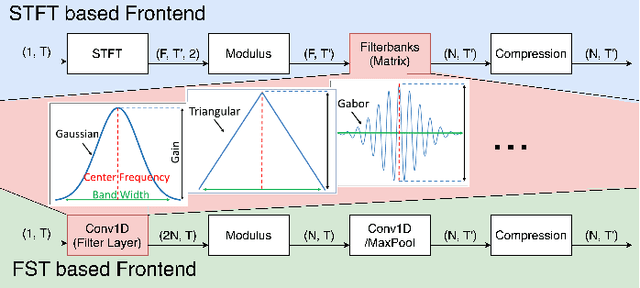
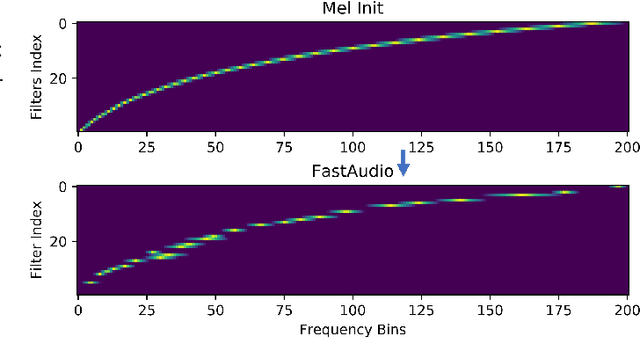
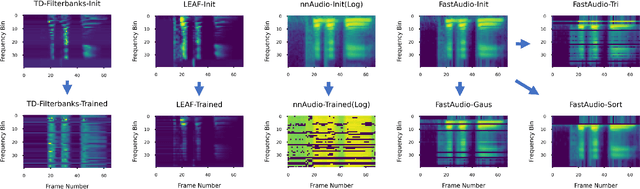
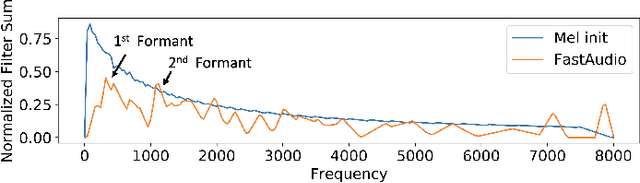
Voice assistants, such as smart speakers, have exploded in popularity. It is currently estimated that the smart speaker adoption rate has exceeded 35% in the US adult population. Manufacturers have integrated speaker identification technology, which attempts to determine the identity of the person speaking, to provide personalized services to different members of the same family. Speaker identification can also play an important role in controlling how the smart speaker is used. For example, it is not critical to correctly identify the user when playing music. However, when reading the user's email out loud, it is critical to correctly verify the speaker that making the request is the authorized user. Speaker verification systems, which authenticate the speaker identity, are therefore needed as a gatekeeper to protect against various spoofing attacks that aim to impersonate the enrolled user. This paper compares popular learnable front-ends which learn the representations of audio by joint training with downstream tasks (End-to-End). We categorize the front-ends by defining two generic architectures and then analyze the filtering stages of both types in terms of learning constraints. We propose replacing fixed filterbanks with a learnable layer that can better adapt to anti-spoofing tasks. The proposed FastAudio front-end is then tested with two popular back-ends to measure the performance on the LA track of the ASVspoof 2019 dataset. The FastAudio front-end achieves a relative improvement of 27% when compared with fixed front-ends, outperforming all other learnable front-ends on this task.
Complementing Handcrafted Features with Raw Waveform Using a Light-weight Auxiliary Model
Sep 06, 2021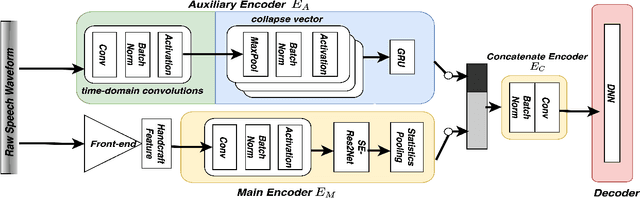
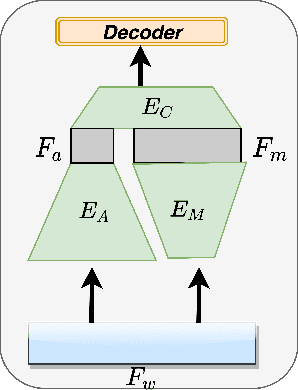

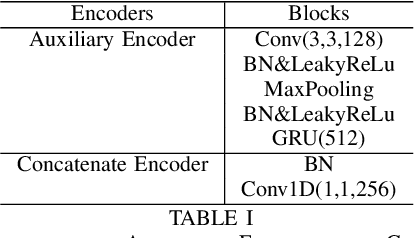
An emerging trend in audio processing is capturing low-level speech representations from raw waveforms. These representations have shown promising results on a variety of tasks, such as speech recognition and speech separation. Compared to handcrafted features, learning speech features via backpropagation provides the model greater flexibility in how it represents data for different tasks theoretically. However, results from empirical study shows that, in some tasks, such as voice spoof detection, handcrafted features are more competitive than learned features. Instead of evaluating handcrafted features and raw waveforms independently, this paper proposes an Auxiliary Rawnet model to complement handcrafted features with features learned from raw waveforms. A key benefit of the approach is that it can improve accuracy at a relatively low computational cost. The proposed Auxiliary Rawnet model is tested using the ASVspoof 2019 dataset and the results from this dataset indicate that a light-weight waveform encoder can potentially boost the performance of handcrafted-features-based encoders in exchange for a small amount of additional computational work.
NeurIPS 2020 NLC2CMD Competition: Translating Natural Language to Bash Commands
Mar 03, 2021
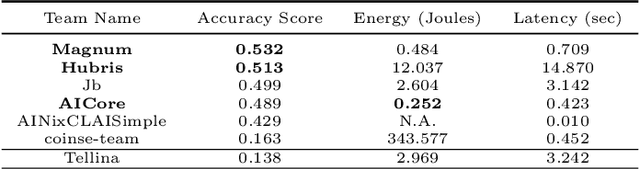

The NLC2CMD Competition hosted at NeurIPS 2020 aimed to bring the power of natural language processing to the command line. Participants were tasked with building models that can transform descriptions of command line tasks in English to their Bash syntax. This is a report on the competition with details of the task, metrics, data, attempted solutions, and lessons learned.