 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOptimizing Domain-Adaptive Self-Supervised Learning for Clinical Voice-Based Disease Classification
Jan 29, 2026The human voice is a promising non-invasive digital biomarker, yet deep learning for voice-based health analysis is hindered by data scarcity and domain mismatch, where models pre-trained on general audio fail to capture the subtle pathological features characteristic of clinical voice data. To address these challenges, we investigate domain-adaptive self-supervised learning (SSL) with Masked Autoencoders (MAE) and demonstrate that standard configurations are suboptimal for health-related audio. Using the Bridge2AI-Voice dataset, a multi-institutional collection of pathological voices, we systematically examine three performance-critical factors: reconstruction loss (Mean Absolute Error vs. Mean Squared Error), normalization (patch-wise vs. global), and masking (random vs. content-aware). Our optimized design, which combines Mean Absolute Error (MA-Error) loss, patch-wise normalization, and content-aware masking, achieves a Macro F1 of $0.688 \pm 0.009$ (over 10 fine-tuning runs), outperforming a strong out-of-domain SSL baseline pre-trained on large-scale general audio, which has a Macro F1 of $0.663 \pm 0.011$. The results show that MA-Error loss improves robustness and content-aware masking boosts performance by emphasizing information-rich regions. These findings highlight the importance of component-level optimization in data-constrained medical applications that rely on audio data.
Complementing Handcrafted Features with Raw Waveform Using a Light-weight Auxiliary Model
Sep 06, 2021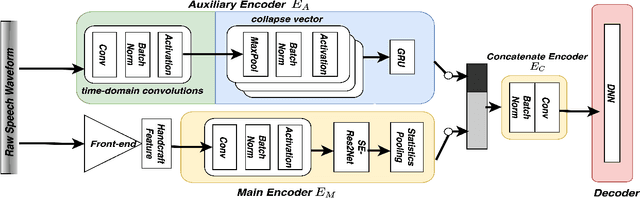
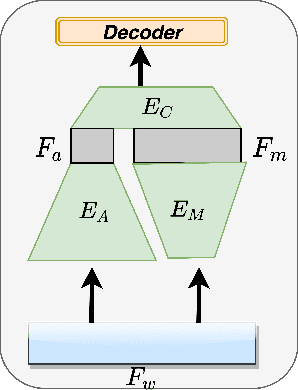

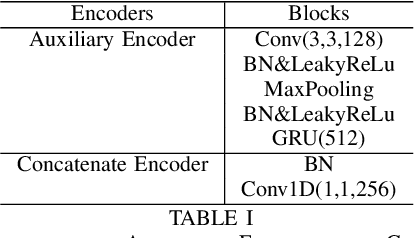
An emerging trend in audio processing is capturing low-level speech representations from raw waveforms. These representations have shown promising results on a variety of tasks, such as speech recognition and speech separation. Compared to handcrafted features, learning speech features via backpropagation provides the model greater flexibility in how it represents data for different tasks theoretically. However, results from empirical study shows that, in some tasks, such as voice spoof detection, handcrafted features are more competitive than learned features. Instead of evaluating handcrafted features and raw waveforms independently, this paper proposes an Auxiliary Rawnet model to complement handcrafted features with features learned from raw waveforms. A key benefit of the approach is that it can improve accuracy at a relatively low computational cost. The proposed Auxiliary Rawnet model is tested using the ASVspoof 2019 dataset and the results from this dataset indicate that a light-weight waveform encoder can potentially boost the performance of handcrafted-features-based encoders in exchange for a small amount of additional computational work.
FastAudio: A Learnable Audio Front-End for Spoof Speech Detection
Sep 06, 2021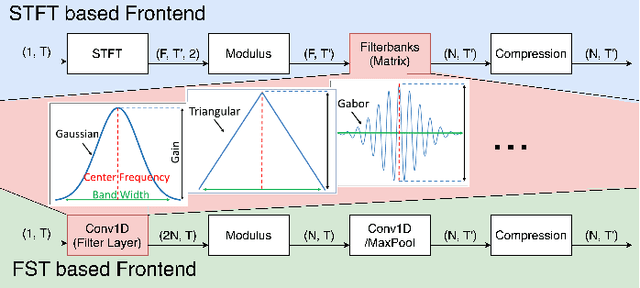
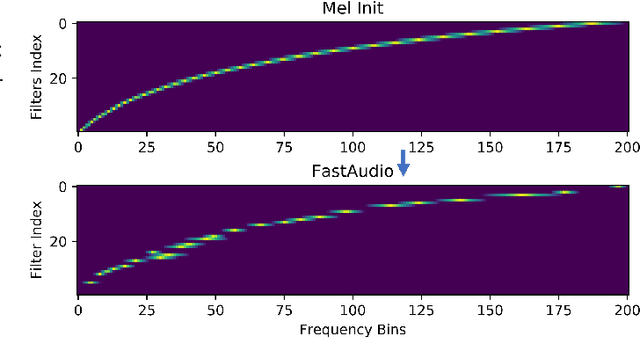
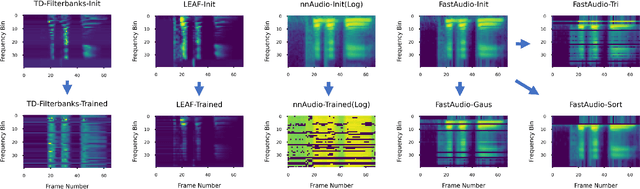
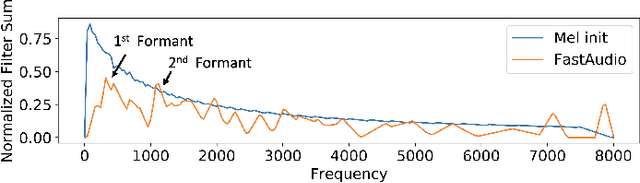
Voice assistants, such as smart speakers, have exploded in popularity. It is currently estimated that the smart speaker adoption rate has exceeded 35% in the US adult population. Manufacturers have integrated speaker identification technology, which attempts to determine the identity of the person speaking, to provide personalized services to different members of the same family. Speaker identification can also play an important role in controlling how the smart speaker is used. For example, it is not critical to correctly identify the user when playing music. However, when reading the user's email out loud, it is critical to correctly verify the speaker that making the request is the authorized user. Speaker verification systems, which authenticate the speaker identity, are therefore needed as a gatekeeper to protect against various spoofing attacks that aim to impersonate the enrolled user. This paper compares popular learnable front-ends which learn the representations of audio by joint training with downstream tasks (End-to-End). We categorize the front-ends by defining two generic architectures and then analyze the filtering stages of both types in terms of learning constraints. We propose replacing fixed filterbanks with a learnable layer that can better adapt to anti-spoofing tasks. The proposed FastAudio front-end is then tested with two popular back-ends to measure the performance on the LA track of the ASVspoof 2019 dataset. The FastAudio front-end achieves a relative improvement of 27% when compared with fixed front-ends, outperforming all other learnable front-ends on this task.