 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExperimental Framework for Generating Reliable Ground Truth for Laryngeal Spatial Segmentation Tasks
Sep 04, 2024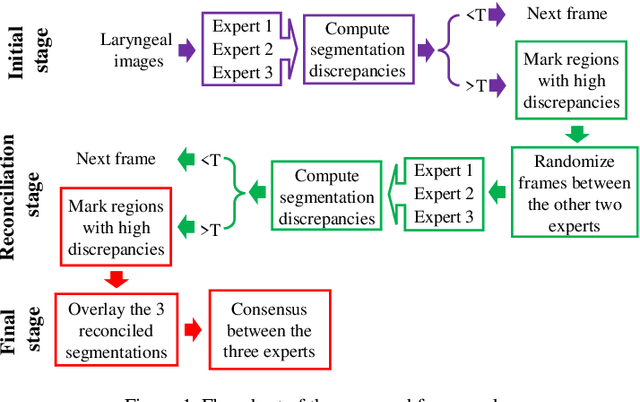
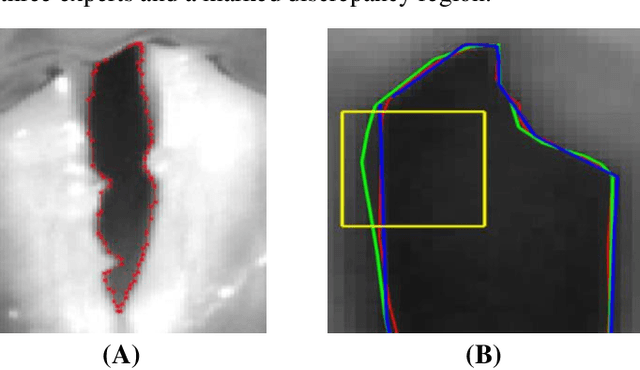
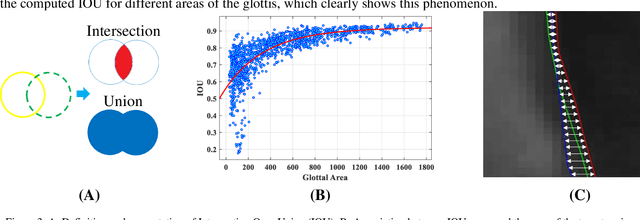
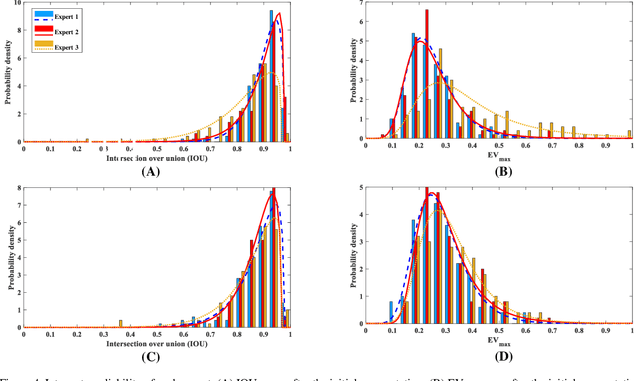
Objective: The validity of objective measures derived from high-speed videoendoscopy (HSV) depends, among other factors, on the validity of spatial segmentation. Evaluation of the validity of spatial segmentation requires the existence of reliable ground truths. This study presents a framework for creating reliable ground truth with sub-pixel resolution and then evaluates its performance. Method: The proposed framework is a three-stage process. First, three laryngeal imaging experts performed the spatial segmentation task. Second, regions with high discrepancies between experts were determined and then overlaid onto the segmentation outcomes of each expert. The marked HSV frames from each expert were randomly assigned to the two remaining experts, and they were tasked to make proper adjustments and modifications to the initial segmentation within disparity regions. Third, the outcomes of this reconciliation phase were analyzed again and regions with continued high discrepancies were identified and adjusted based on the consensus among the three experts. This three-stage framework was tested using a custom graphical user interface that allowed precise piece-wise linear segmentation of the vocal fold edges. Inter-rate reliability of segmentation was evaluated using 12 HSV recordings. 10% of the frames from each HSV file were randomly selected to assess the intra-rater reliability. Result and conclusion: The reliability of spatial segmentation progressively improved as it went through the three stages of the framework. The proposed framework generated highly reliable and valid ground truths for evaluating the validity of automated spatial segmentation methods.
SA-SASV: An End-to-End Spoof-Aggregated Spoofing-Aware Speaker Verification System
Mar 24, 2022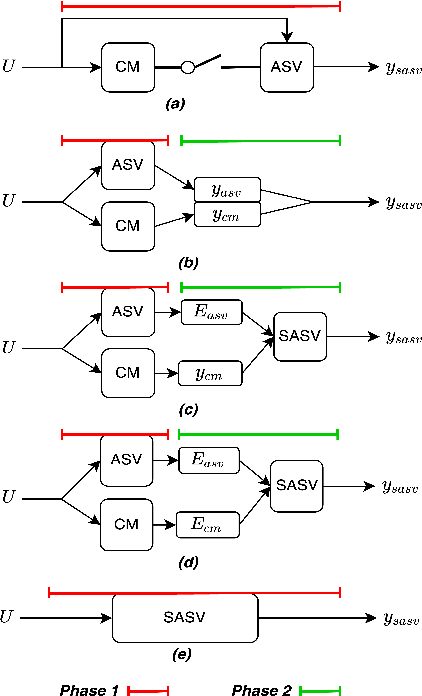
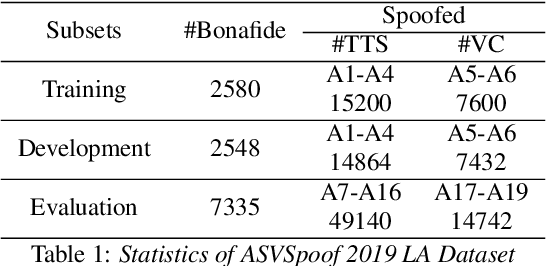
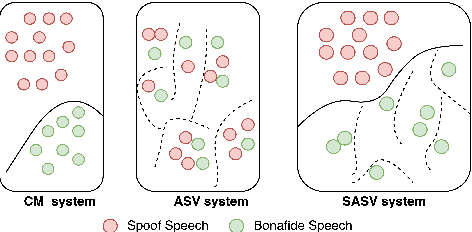
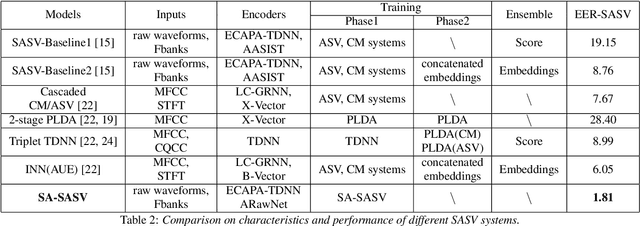
Research in the past several years has boosted the performance of automatic speaker verification systems and countermeasure systems to deliver low Equal Error Rates (EERs) on each system. However, research on joint optimization of both systems is still limited. The Spoofing-Aware Speaker Verification (SASV) 2022 challenge was proposed to encourage the development of integrated SASV systems with new metrics to evaluate joint model performance. This paper proposes an ensemble-free end-to-end solution, known as Spoof-Aggregated-SASV (SA-SASV) to build a SASV system with multi-task classifiers, which are optimized by multiple losses and has more flexible requirements in training set. The proposed system is trained on the ASVSpoof 2019 LA dataset, a spoof verification dataset with small number of bonafide speakers. Results of SASV-EER indicate that the model performance can be further improved by training in complete automatic speaker verification and countermeasure datasets.