 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGranite-Function Calling Model: Introducing Function Calling Abilities via Multi-task Learning of Granular Tasks
Jun 27, 2024



Large language models (LLMs) have recently shown tremendous promise in serving as the backbone to agentic systems, as demonstrated by their performance in multi-faceted, challenging benchmarks like SWE-Bench and Agent-Bench. However, to realize the true potential of LLMs as autonomous agents, they must learn to identify, call, and interact with external tools and application program interfaces (APIs) to complete complex tasks. These tasks together are termed function calling. Endowing LLMs with function calling abilities leads to a myriad of advantages, such as access to current and domain-specific information in databases and knowledge sources, and the ability to outsource tasks that can be reliably performed by tools, e.g., a Python interpreter or calculator. While there has been significant progress in function calling with LLMs, there is still a dearth of open models that perform on par with proprietary LLMs like GPT, Claude, and Gemini. Therefore, in this work, we introduce the GRANITE-20B-FUNCTIONCALLING model under an Apache 2.0 license. The model is trained using a multi-task training approach on seven fundamental tasks encompassed in function calling, those being Nested Function Calling, Function Chaining, Parallel Functions, Function Name Detection, Parameter-Value Pair Detection, Next-Best Function, and Response Generation. We present a comprehensive evaluation on multiple out-of-domain datasets comparing GRANITE-20B-FUNCTIONCALLING to more than 15 other best proprietary and open models. GRANITE-20B-FUNCTIONCALLING provides the best performance among all open models on the Berkeley Function Calling Leaderboard and fourth overall. As a result of the diverse tasks and datasets used for training our model, we show that GRANITE-20B-FUNCTIONCALLING has better generalizability on multiple tasks in seven different evaluation datasets.
Granite Code Models: A Family of Open Foundation Models for Code Intelligence
May 07, 2024



Large Language Models (LLMs) trained on code are revolutionizing the software development process. Increasingly, code LLMs are being integrated into software development environments to improve the productivity of human programmers, and LLM-based agents are beginning to show promise for handling complex tasks autonomously. Realizing the full potential of code LLMs requires a wide range of capabilities, including code generation, fixing bugs, explaining and documenting code, maintaining repositories, and more. In this work, we introduce the Granite series of decoder-only code models for code generative tasks, trained with code written in 116 programming languages. The Granite Code models family consists of models ranging in size from 3 to 34 billion parameters, suitable for applications ranging from complex application modernization tasks to on-device memory-constrained use cases. Evaluation on a comprehensive set of tasks demonstrates that Granite Code models consistently reaches state-of-the-art performance among available open-source code LLMs. The Granite Code model family was optimized for enterprise software development workflows and performs well across a range of coding tasks (e.g. code generation, fixing and explanation), making it a versatile all around code model. We release all our Granite Code models under an Apache 2.0 license for both research and commercial use.
Aligners: Decoupling LLMs and Alignment
Mar 11, 2024

Large Language Models (LLMs) need to be aligned with human expectations to ensure their safety and utility in most applications. Alignment is challenging, costly, and needs to be repeated for every LLM and alignment criterion. We propose to decouple LLMs and alignment by training aligner models that can be used to align any LLM for a given criteria on an as-needed basis, thus also reducing the potential negative impacts of alignment on performance. Our recipe for training the aligner models solely relies on synthetic data generated with a (prompted) LLM and can be easily adjusted for a variety of alignment criteria. We illustrate our method by training an "ethical" aligner and verify its efficacy empirically.
Structured Code Representations Enable Data-Efficient Adaptation of Code Language Models
Jan 19, 2024


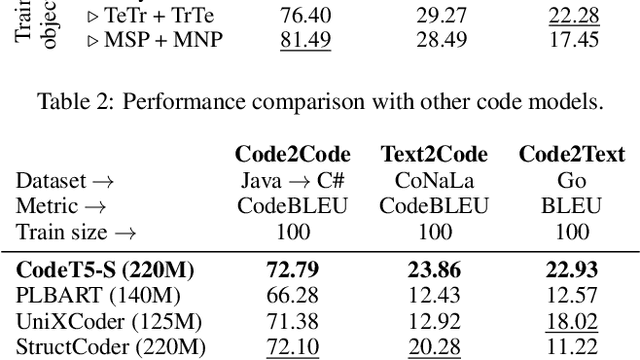
Current language models tailored for code tasks often adopt the pre-training-then-fine-tuning paradigm from natural language processing, modeling source code as plain text. This approach, however, overlooks the unambiguous structures inherent in programming languages. In this work, we explore data-efficient adaptation of pre-trained code models by further pre-training and fine-tuning them with program structures. Specifically, we represent programs as parse trees -- also known as concrete syntax trees (CSTs) -- and adapt pre-trained models on serialized CSTs. Although the models that we adapt have been pre-trained only on the surface form of programs, we find that a small amount of continual pre-training and fine-tuning on CSTs without changing the model architecture yields improvements over the baseline approach across various code tasks. The improvements are found to be particularly significant when there are limited training examples, demonstrating the effectiveness of integrating program structures with plain-text representation even when working with backbone models that have not been pre-trained with structures.
Explain-then-Translate: An Analysis on Improving Program Translation with Self-generated Explanations
Nov 13, 2023
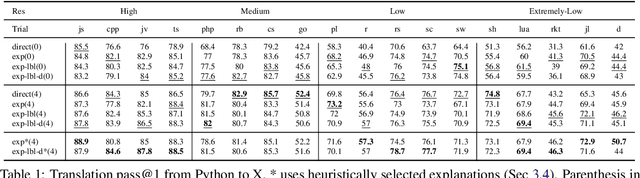
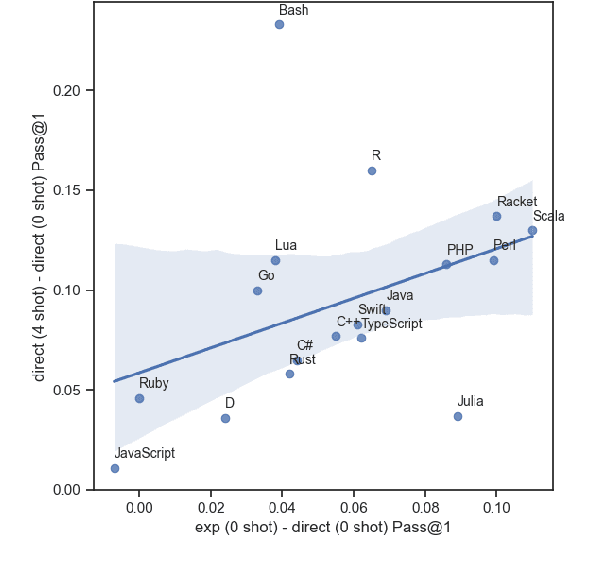
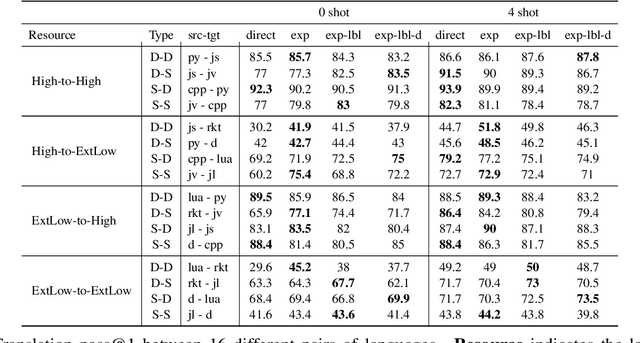
This work explores the use of self-generated natural language explanations as an intermediate step for code-to-code translation with language models. Across three types of explanations and 19 programming languages constructed from the MultiPL-E dataset, we find the explanations to be particularly effective in the zero-shot case, improving performance by 12% on average. Improvements with natural language explanations are particularly pronounced on difficult programs. We release our dataset, code, and canonical solutions in all 19 languages.
An Investigation of Representation and Allocation Harms in Contrastive Learning
Oct 02, 2023



The effect of underrepresentation on the performance of minority groups is known to be a serious problem in supervised learning settings; however, it has been underexplored so far in the context of self-supervised learning (SSL). In this paper, we demonstrate that contrastive learning (CL), a popular variant of SSL, tends to collapse representations of minority groups with certain majority groups. We refer to this phenomenon as representation harm and demonstrate it on image and text datasets using the corresponding popular CL methods. Furthermore, our causal mediation analysis of allocation harm on a downstream classification task reveals that representation harm is partly responsible for it, thus emphasizing the importance of studying and mitigating representation harm. Finally, we provide a theoretical explanation for representation harm using a stochastic block model that leads to a representational neural collapse in a contrastive learning setting.
Fairness Evaluation in Text Classification: Machine Learning Practitioner Perspectives of Individual and Group Fairness
Mar 01, 2023Mitigating algorithmic bias is a critical task in the development and deployment of machine learning models. While several toolkits exist to aid machine learning practitioners in addressing fairness issues, little is known about the strategies practitioners employ to evaluate model fairness and what factors influence their assessment, particularly in the context of text classification. Two common approaches of evaluating the fairness of a model are group fairness and individual fairness. We run a study with Machine Learning practitioners (n=24) to understand the strategies used to evaluate models. Metrics presented to practitioners (group vs. individual fairness) impact which models they consider fair. Participants focused on risks associated with underpredicting/overpredicting and model sensitivity relative to identity token manipulations. We discover fairness assessment strategies involving personal experiences or how users form groups of identity tokens to test model fairness. We provide recommendations for interactive tools for evaluating fairness in text classification.
Geometry-biased Transformers for Novel View Synthesis
Jan 11, 2023



We tackle the task of synthesizing novel views of an object given a few input images and associated camera viewpoints. Our work is inspired by recent 'geometry-free' approaches where multi-view images are encoded as a (global) set-latent representation, which is then used to predict the color for arbitrary query rays. While this representation yields (coarsely) accurate images corresponding to novel viewpoints, the lack of geometric reasoning limits the quality of these outputs. To overcome this limitation, we propose 'Geometry-biased Transformers' (GBTs) that incorporate geometric inductive biases in the set-latent representation-based inference to encourage multi-view geometric consistency. We induce the geometric bias by augmenting the dot-product attention mechanism to also incorporate 3D distances between rays associated with tokens as a learnable bias. We find that this, along with camera-aware embeddings as input, allows our models to generate significantly more accurate outputs. We validate our approach on the real-world CO3D dataset, where we train our system over 10 categories and evaluate its view-synthesis ability for novel objects as well as unseen categories. We empirically validate the benefits of the proposed geometric biases and show that our approach significantly improves over prior works.
Investigating Explainability of Generative AI for Code through Scenario-based Design
Feb 10, 2022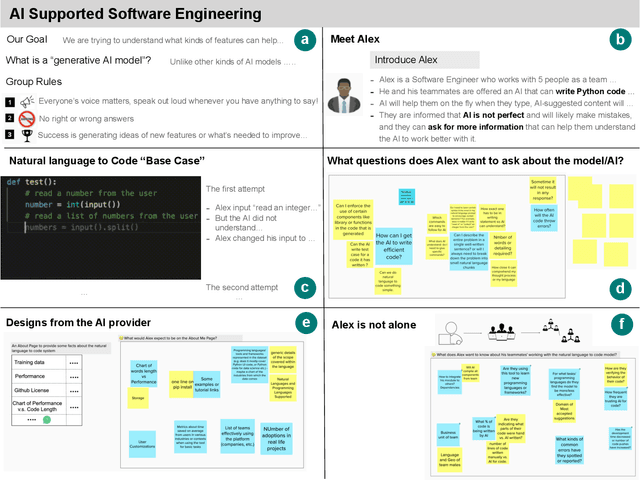
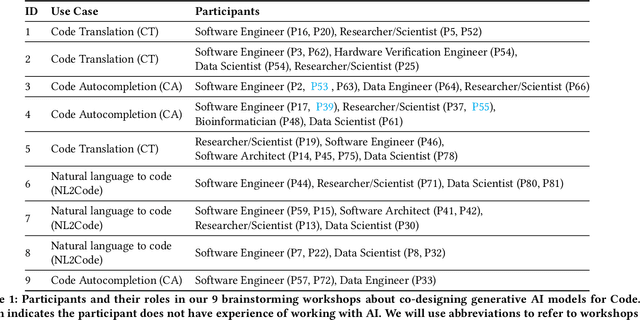

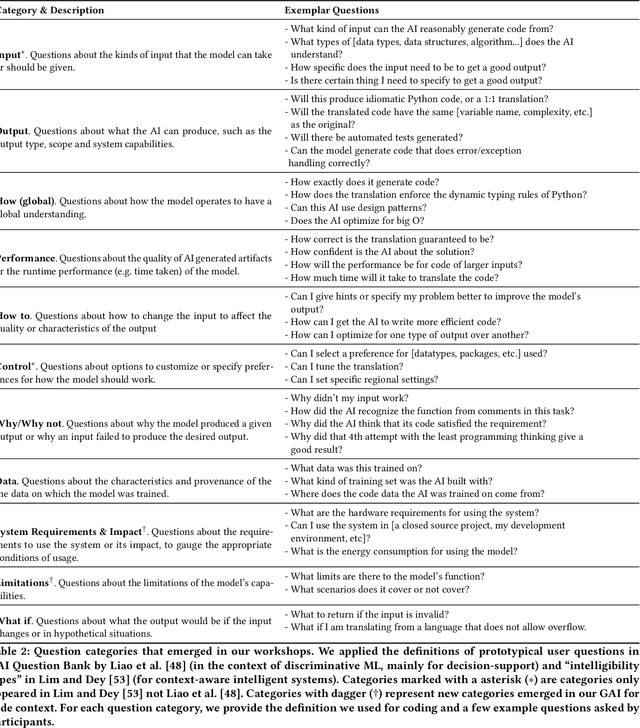
What does it mean for a generative AI model to be explainable? The emergent discipline of explainable AI (XAI) has made great strides in helping people understand discriminative models. Less attention has been paid to generative models that produce artifacts, rather than decisions, as output. Meanwhile, generative AI (GenAI) technologies are maturing and being applied to application domains such as software engineering. Using scenario-based design and question-driven XAI design approaches, we explore users' explainability needs for GenAI in three software engineering use cases: natural language to code, code translation, and code auto-completion. We conducted 9 workshops with 43 software engineers in which real examples from state-of-the-art generative AI models were used to elicit users' explainability needs. Drawing from prior work, we also propose 4 types of XAI features for GenAI for code and gathered additional design ideas from participants. Our work explores explainability needs for GenAI for code and demonstrates how human-centered approaches can drive the technical development of XAI in novel domains.
On sensitivity of meta-learning to support data
Oct 26, 2021
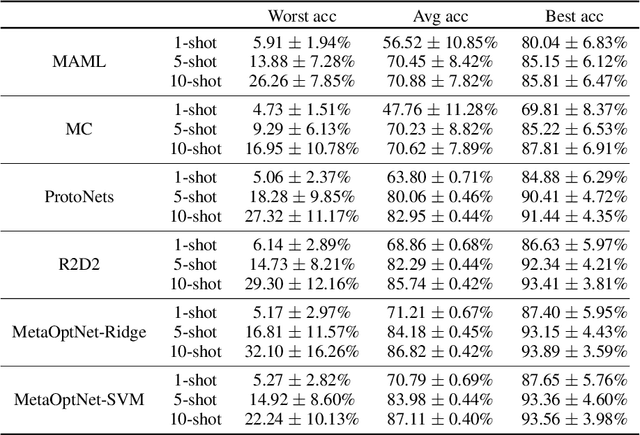

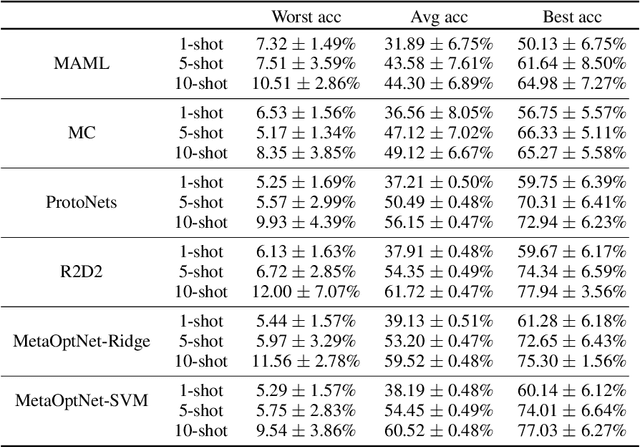
Meta-learning algorithms are widely used for few-shot learning. For example, image recognition systems that readily adapt to unseen classes after seeing only a few labeled examples. Despite their success, we show that modern meta-learning algorithms are extremely sensitive to the data used for adaptation, i.e. support data. In particular, we demonstrate the existence of (unaltered, in-distribution, natural) images that, when used for adaptation, yield accuracy as low as 4\% or as high as 95\% on standard few-shot image classification benchmarks. We explain our empirical findings in terms of class margins, which in turn suggests that robust and safe meta-learning requires larger margins than supervised learning.