 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhich Contributions Deserve Credit? Perceptions of Attribution in Human-AI Co-Creation
Feb 25, 2025

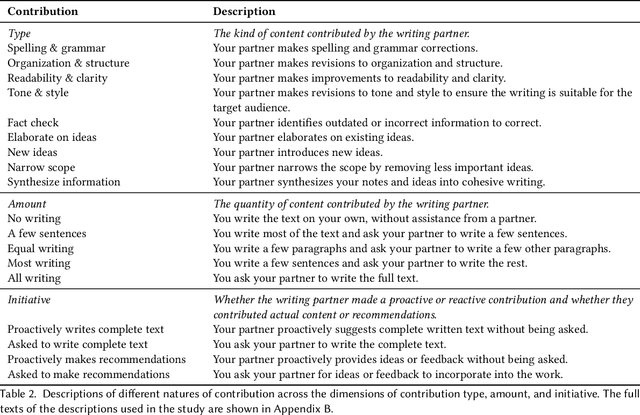

AI systems powered by large language models can act as capable assistants for writing and editing. In these tasks, the AI system acts as a co-creative partner, making novel contributions to an artifact-under-creation alongside its human partner(s). One question that arises in these scenarios is the extent to which AI should be credited for its contributions. We examined knowledge workers' views of attribution through a survey study (N=155) and found that they assigned different levels of credit across different contribution types, amounts, and initiative. Compared to a human partner, we observed a consistent pattern in which AI was assigned less credit for equivalent contributions. Participants felt that disclosing AI involvement was important and used a variety of criteria to make attribution judgments, including the quality of contributions, personal values, and technology considerations. Our results motivate and inform new approaches for crediting AI contributions to co-created work.
A Case Study in Engineering a Conversational Programming Assistant's Persona
Jan 13, 2023The Programmer's Assistant is an experimental prototype software development environment that integrates a chatbot with a code editor. Conversational capability was achieved by using an existing code-fluent Large Language Model and providing it with a prompt that establishes a conversational interaction pattern, a set of conventions, and a style of interaction appropriate for the application. A discussion of the evolution of the prompt provides a case study in how to coax an existing foundation model to behave in a desirable manner for a particular application.
Toward General Design Principles for Generative AI Applications
Jan 13, 2023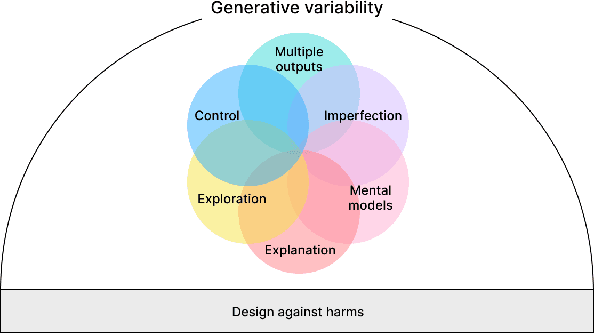
Generative AI technologies are growing in power, utility, and use. As generative technologies are being incorporated into mainstream applications, there is a need for guidance on how to design those applications to foster productive and safe use. Based on recent research on human-AI co-creation within the HCI and AI communities, we present a set of seven principles for the design of generative AI applications. These principles are grounded in an environment of generative variability. Six principles are focused on designing for characteristics of generative AI: multiple outcomes & imperfection; exploration & control; and mental models & explanations. In addition, we urge designers to design against potential harms that may be caused by a generative model's hazardous output, misuse, or potential for human displacement. We anticipate these principles to usefully inform design decisions made in the creation of novel human-AI applications, and we invite the community to apply, revise, and extend these principles to their own work.
Investigating Explainability of Generative AI for Code through Scenario-based Design
Feb 10, 2022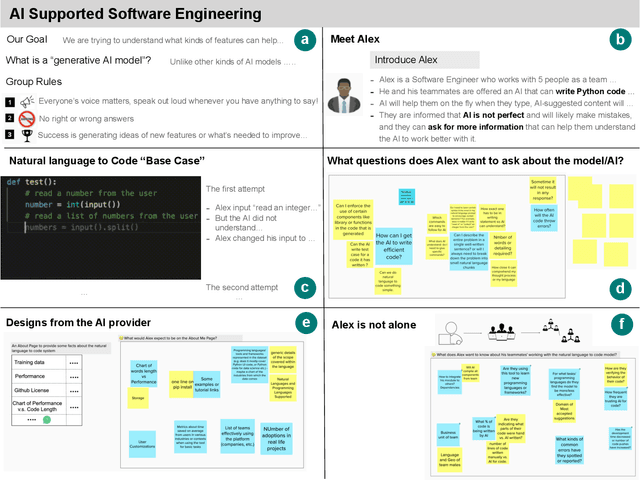
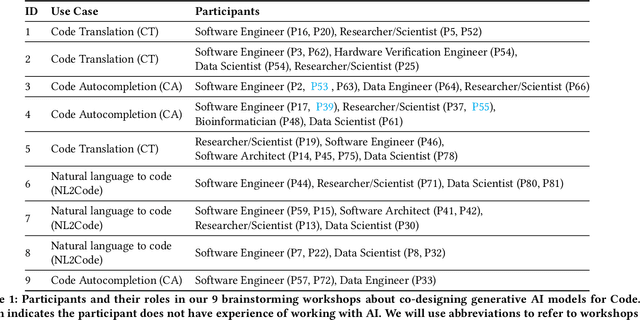

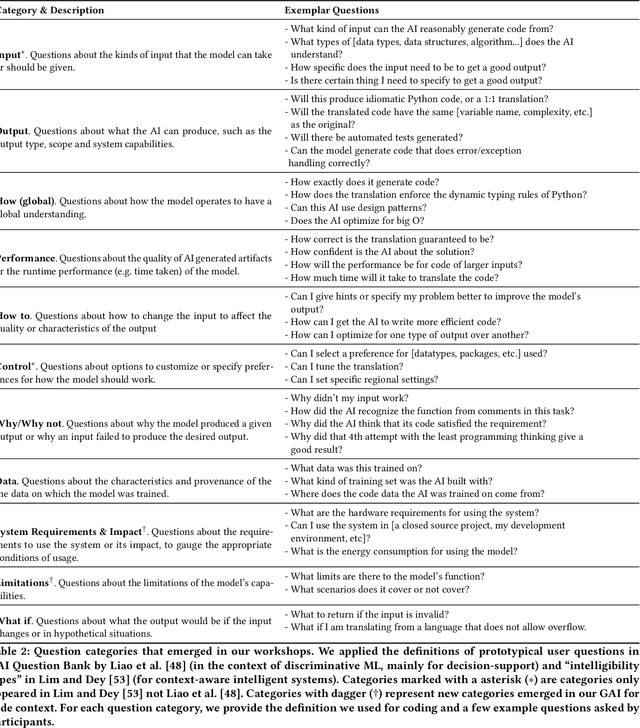
What does it mean for a generative AI model to be explainable? The emergent discipline of explainable AI (XAI) has made great strides in helping people understand discriminative models. Less attention has been paid to generative models that produce artifacts, rather than decisions, as output. Meanwhile, generative AI (GenAI) technologies are maturing and being applied to application domains such as software engineering. Using scenario-based design and question-driven XAI design approaches, we explore users' explainability needs for GenAI in three software engineering use cases: natural language to code, code translation, and code auto-completion. We conducted 9 workshops with 43 software engineers in which real examples from state-of-the-art generative AI models were used to elicit users' explainability needs. Drawing from prior work, we also propose 4 types of XAI features for GenAI for code and gathered additional design ideas from participants. Our work explores explainability needs for GenAI for code and demonstrates how human-centered approaches can drive the technical development of XAI in novel domains.
Using Document Similarity Methods to create Parallel Datasets for Code Translation
Oct 11, 2021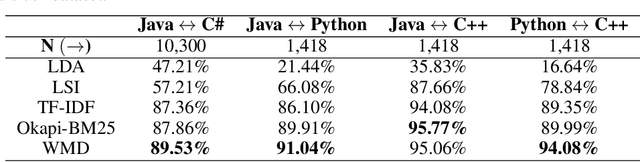
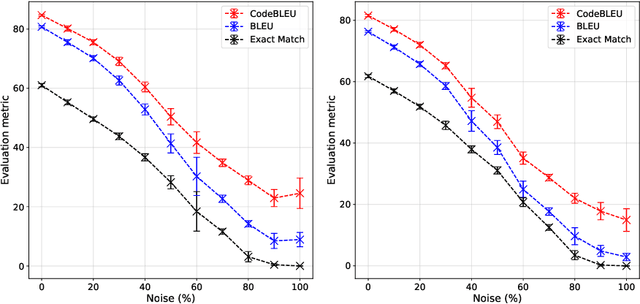
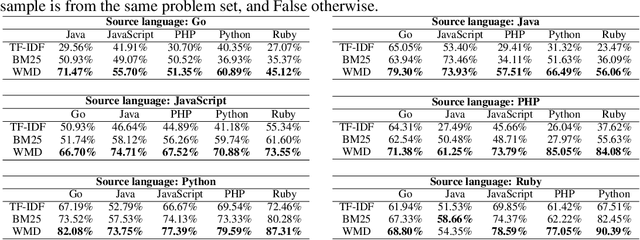
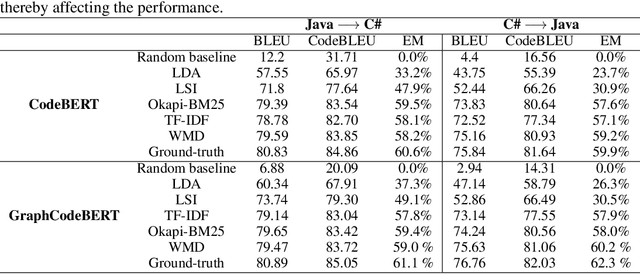
Translating source code from one programming language to another is a critical, time-consuming task in modernizing legacy applications and codebases. Recent work in this space has drawn inspiration from the software naturalness hypothesis by applying natural language processing techniques towards automating the code translation task. However, due to the paucity of parallel data in this domain, supervised techniques have only been applied to a limited set of popular programming languages. To bypass this limitation, unsupervised neural machine translation techniques have been proposed to learn code translation using only monolingual corpora. In this work, we propose to use document similarity methods to create noisy parallel datasets of code, thus enabling supervised techniques to be applied for automated code translation without having to rely on the availability or expensive curation of parallel code datasets. We explore the noise tolerance of models trained on such automatically-created datasets and show that these models perform comparably to models trained on ground truth for reasonable levels of noise. Finally, we exhibit the practical utility of the proposed method by creating parallel datasets for languages beyond the ones explored in prior work, thus expanding the set of programming languages for automated code translation.
AI Explainability 360: Impact and Design
Sep 24, 2021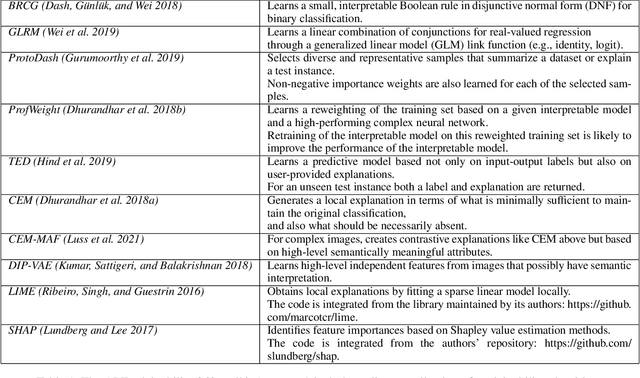
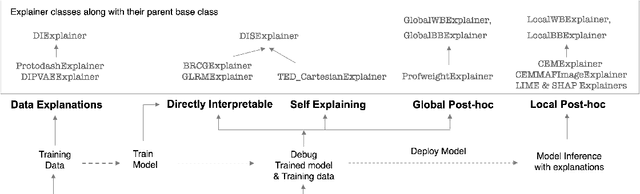

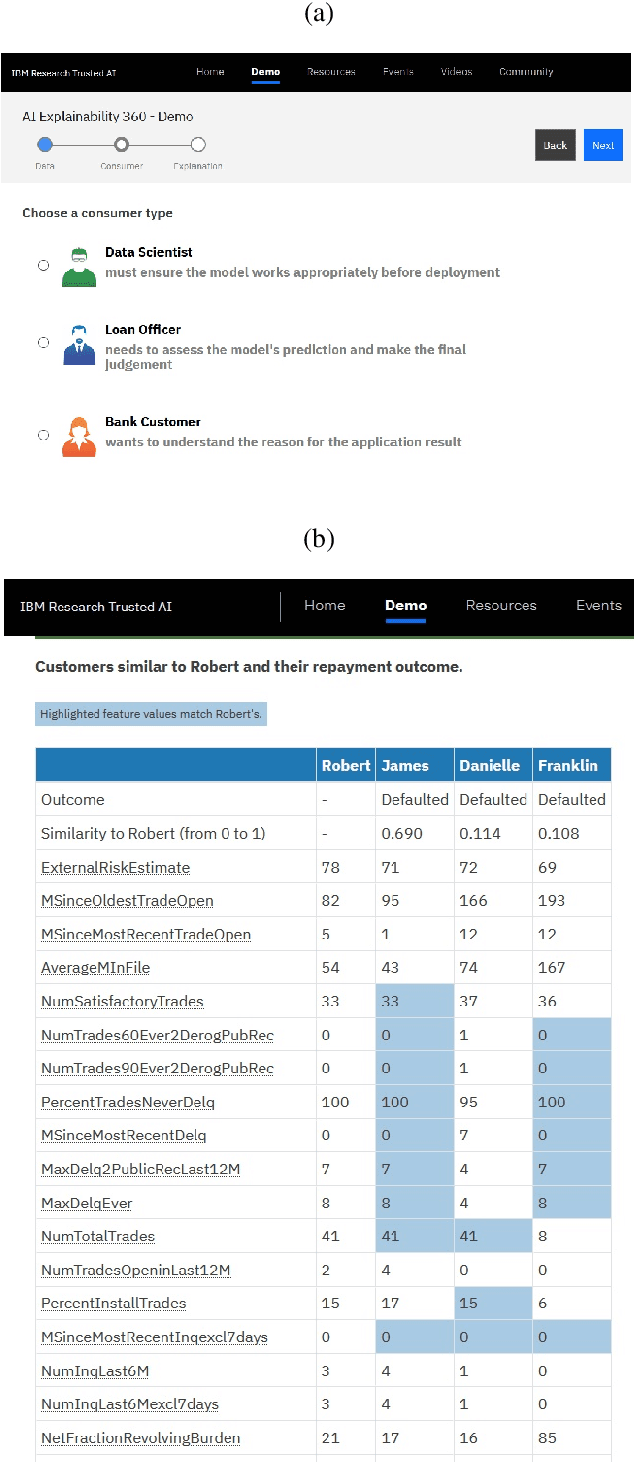
As artificial intelligence and machine learning algorithms become increasingly prevalent in society, multiple stakeholders are calling for these algorithms to provide explanations. At the same time, these stakeholders, whether they be affected citizens, government regulators, domain experts, or system developers, have different explanation needs. To address these needs, in 2019, we created AI Explainability 360 (Arya et al. 2020), an open source software toolkit featuring ten diverse and state-of-the-art explainability methods and two evaluation metrics. This paper examines the impact of the toolkit with several case studies, statistics, and community feedback. The different ways in which users have experienced AI Explainability 360 have resulted in multiple types of impact and improvements in multiple metrics, highlighted by the adoption of the toolkit by the independent LF AI & Data Foundation. The paper also describes the flexible design of the toolkit, examples of its use, and the significant educational material and documentation available to its users.
Towards evaluating and eliciting high-quality documentation for intelligent systems
Nov 17, 2020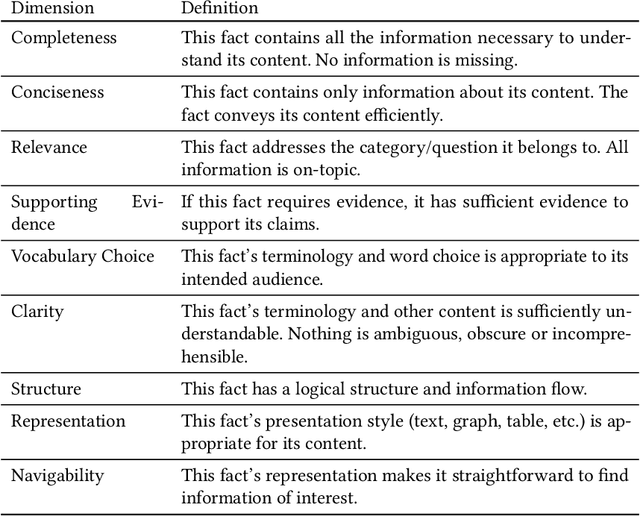
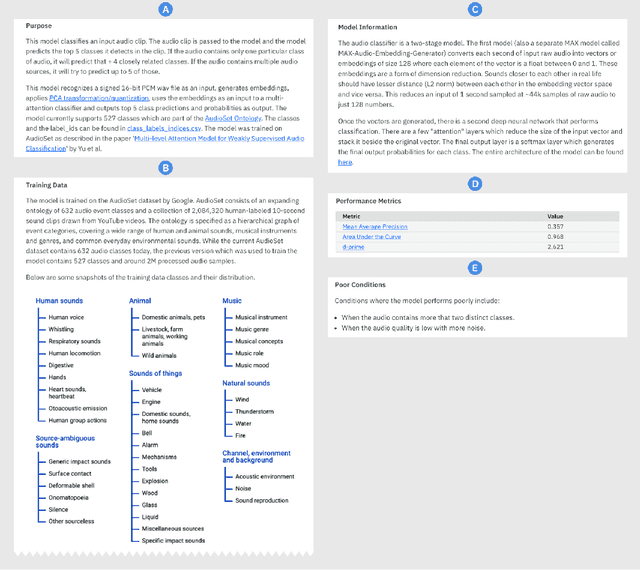

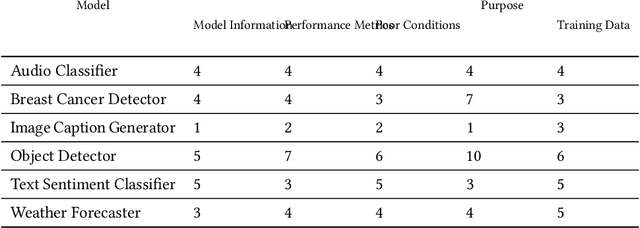
A vital component of trust and transparency in intelligent systems built on machine learning and artificial intelligence is the development of clear, understandable documentation. However, such systems are notorious for their complexity and opaqueness making quality documentation a non-trivial task. Furthermore, little is known about what makes such documentation "good." In this paper, we propose and evaluate a set of quality dimensions to identify in what ways this type of documentation falls short. Then, using those dimensions, we evaluate three different approaches for eliciting intelligent system documentation. We show how the dimensions identify shortcomings in such documentation and posit how such dimensions can be use to further enable users to provide documentation that is suitable to a given persona or use case.
A Methodology for Creating AI FactSheets
Jun 28, 2020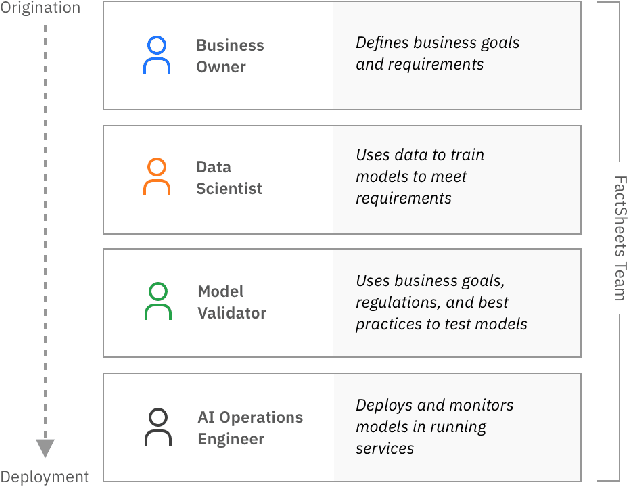


As AI models and services are used in a growing number of highstakes areas, a consensus is forming around the need for a clearer record of how these models and services are developed to increase trust. Several proposals for higher quality and more consistent AI documentation have emerged to address ethical and legal concerns and general social impacts of such systems. However, there is little published work on how to create this documentation. This is the first work to describe a methodology for creating the form of AI documentation we call FactSheets. We have used this methodology to create useful FactSheets for nearly two dozen models. This paper describes this methodology and shares the insights we have gathered. Within each step of the methodology, we describe the issues to consider and the questions to explore with the relevant people in an organization who will be creating and consuming the AI facts in a FactSheet. This methodology will accelerate the broader adoption of transparent AI documentation.
One Explanation Does Not Fit All: A Toolkit and Taxonomy of AI Explainability Techniques
Sep 14, 2019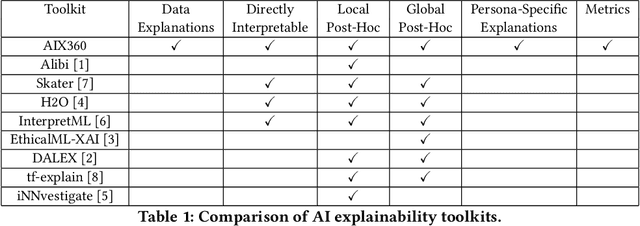
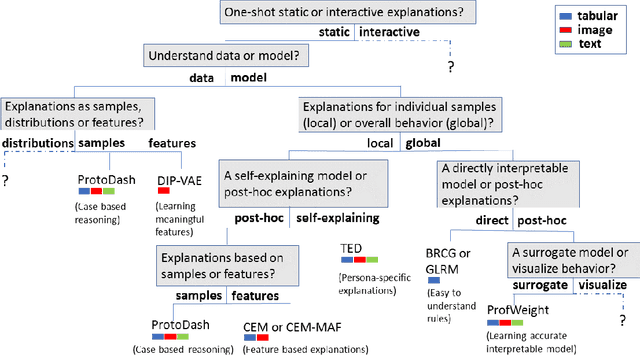
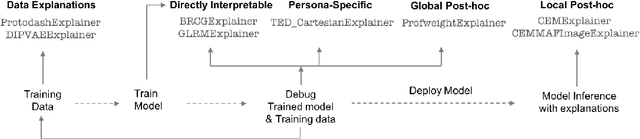
As artificial intelligence and machine learning algorithms make further inroads into society, calls are increasing from multiple stakeholders for these algorithms to explain their outputs. At the same time, these stakeholders, whether they be affected citizens, government regulators, domain experts, or system developers, present different requirements for explanations. Toward addressing these needs, we introduce AI Explainability 360 (http://aix360.mybluemix.net/), an open-source software toolkit featuring eight diverse and state-of-the-art explainability methods and two evaluation metrics. Equally important, we provide a taxonomy to help entities requiring explanations to navigate the space of explanation methods, not only those in the toolkit but also in the broader literature on explainability. For data scientists and other users of the toolkit, we have implemented an extensible software architecture that organizes methods according to their place in the AI modeling pipeline. We also discuss enhancements to bring research innovations closer to consumers of explanations, ranging from simplified, more accessible versions of algorithms, to tutorials and an interactive web demo to introduce AI explainability to different audiences and application domains. Together, our toolkit and taxonomy can help identify gaps where more explainability methods are needed and provide a platform to incorporate them as they are developed.
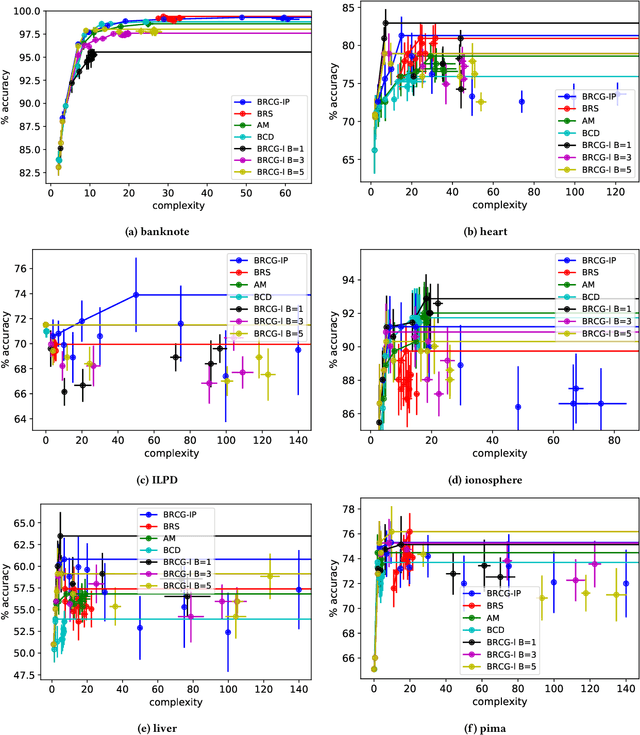
AI Fairness 360: An Extensible Toolkit for Detecting, Understanding, and Mitigating Unwanted Algorithmic Bias
Oct 03, 2018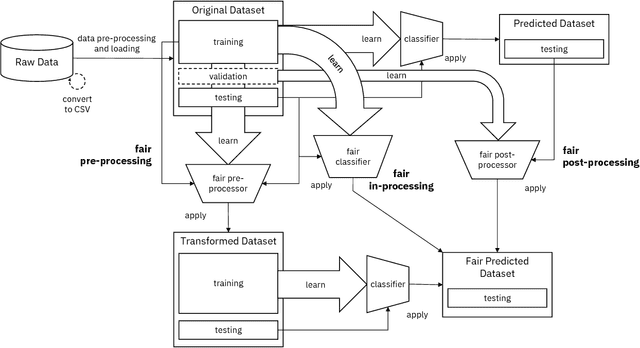
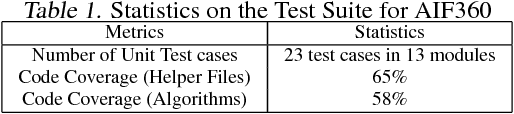
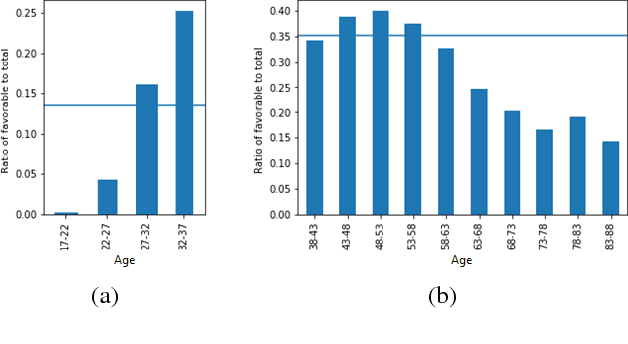
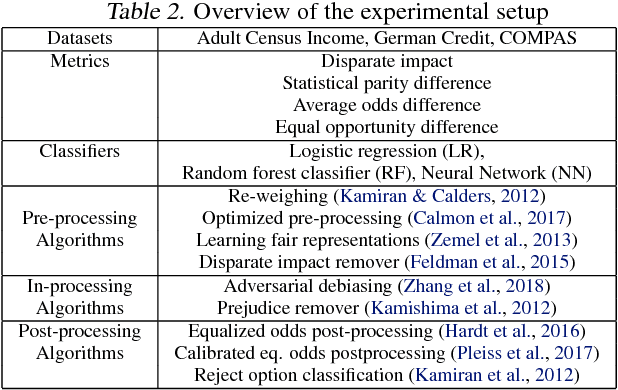
Fairness is an increasingly important concern as machine learning models are used to support decision making in high-stakes applications such as mortgage lending, hiring, and prison sentencing. This paper introduces a new open source Python toolkit for algorithmic fairness, AI Fairness 360 (AIF360), released under an Apache v2.0 license {https://github.com/ibm/aif360). The main objectives of this toolkit are to help facilitate the transition of fairness research algorithms to use in an industrial setting and to provide a common framework for fairness researchers to share and evaluate algorithms. The package includes a comprehensive set of fairness metrics for datasets and models, explanations for these metrics, and algorithms to mitigate bias in datasets and models. It also includes an interactive Web experience (https://aif360.mybluemix.net) that provides a gentle introduction to the concepts and capabilities for line-of-business users, as well as extensive documentation, usage guidance, and industry-specific tutorials to enable data scientists and practitioners to incorporate the most appropriate tool for their problem into their work products. The architecture of the package has been engineered to conform to a standard paradigm used in data science, thereby further improving usability for practitioners. Such architectural design and abstractions enable researchers and developers to extend the toolkit with their new algorithms and improvements, and to use it for performance benchmarking. A built-in testing infrastructure maintains code quality.