 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStackelberg Coupling of Online Representation Learning and Reinforcement Learning
Aug 10, 2025Integrated, end-to-end learning of representations and policies remains a cornerstone of deep reinforcement learning (RL). However, to address the challenge of learning effective features from a sparse reward signal, recent trends have shifted towards adding complex auxiliary objectives or fully decoupling the two processes, often at the cost of increased design complexity. This work proposes an alternative to both decoupling and naive end-to-end learning, arguing that performance can be significantly improved by structuring the interaction between distinct perception and control networks with a principled, game-theoretic dynamic. We formalize this dynamic by introducing the Stackelberg Coupled Representation and Reinforcement Learning (SCORER) framework, which models the interaction between perception and control as a Stackelberg game. The perception network (leader) strategically learns features to benefit the control network (follower), whose own objective is to minimize its Bellman error. We approximate the game's equilibrium with a practical two-timescale algorithm. Applied to standard DQN variants on benchmark tasks, SCORER improves sample efficiency and final performance. Our results show that performance gains can be achieved through principled algorithmic design of the perception-control dynamic, without requiring complex auxiliary objectives or architectures.
Redefining DDoS Attack Detection Using A Dual-Space Prototypical Network-Based Approach
Jun 04, 2024Distributed Denial of Service (DDoS) attacks pose an increasingly substantial cybersecurity threat to organizations across the globe. In this paper, we introduce a new deep learning-based technique for detecting DDoS attacks, a paramount cybersecurity challenge with evolving complexity and scale. Specifically, we propose a new dual-space prototypical network that leverages a unique dual-space loss function to enhance detection accuracy for various attack patterns through geometric and angular similarity measures. This approach capitalizes on the strengths of representation learning within the latent space (a lower-dimensional representation of data that captures complex patterns for machine learning analysis), improving the model's adaptability and sensitivity towards varying DDoS attack vectors. Our comprehensive evaluation spans multiple training environments, including offline training, simulated online training, and prototypical network scenarios, to validate the model's robustness under diverse data abundance and scarcity conditions. The Multilayer Perceptron (MLP) with Attention, trained with our dual-space prototypical design over a reduced training set, achieves an average accuracy of 94.85% and an F1-Score of 94.71% across our tests, showcasing its effectiveness in dynamic and constrained real-world scenarios.
A Case Study in Engineering a Conversational Programming Assistant's Persona
Jan 13, 2023The Programmer's Assistant is an experimental prototype software development environment that integrates a chatbot with a code editor. Conversational capability was achieved by using an existing code-fluent Large Language Model and providing it with a prompt that establishes a conversational interaction pattern, a set of conventions, and a style of interaction appropriate for the application. A discussion of the evolution of the prompt provides a case study in how to coax an existing foundation model to behave in a desirable manner for a particular application.
Using Document Similarity Methods to create Parallel Datasets for Code Translation
Oct 11, 2021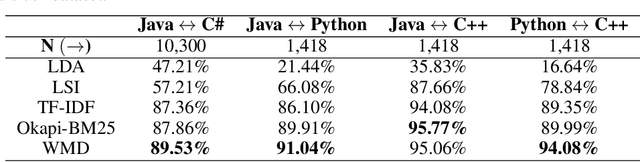
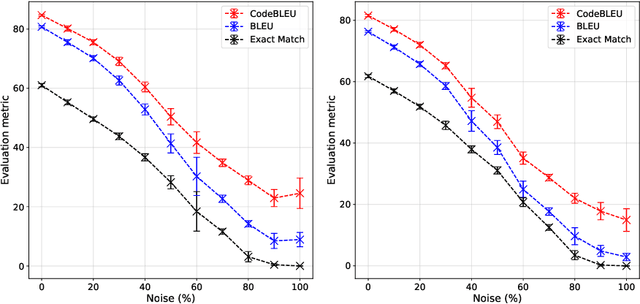
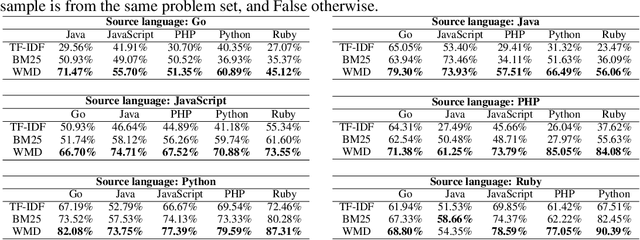
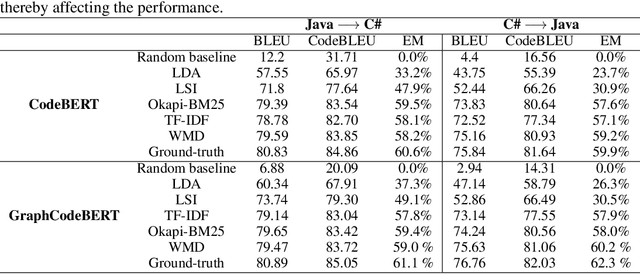
Translating source code from one programming language to another is a critical, time-consuming task in modernizing legacy applications and codebases. Recent work in this space has drawn inspiration from the software naturalness hypothesis by applying natural language processing techniques towards automating the code translation task. However, due to the paucity of parallel data in this domain, supervised techniques have only been applied to a limited set of popular programming languages. To bypass this limitation, unsupervised neural machine translation techniques have been proposed to learn code translation using only monolingual corpora. In this work, we propose to use document similarity methods to create noisy parallel datasets of code, thus enabling supervised techniques to be applied for automated code translation without having to rely on the availability or expensive curation of parallel code datasets. We explore the noise tolerance of models trained on such automatically-created datasets and show that these models perform comparably to models trained on ground truth for reasonable levels of noise. Finally, we exhibit the practical utility of the proposed method by creating parallel datasets for languages beyond the ones explored in prior work, thus expanding the set of programming languages for automated code translation.