 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAgentSCOPE: Evaluating Contextual Privacy Across Agentic Workflows
Mar 05, 2026Agentic systems are increasingly acting on users' behalf, accessing calendars, email, and personal files to complete everyday tasks. Privacy evaluation for these systems has focused on the input and output boundaries, but each task involves several intermediate information flows, from agent queries to tool responses, that are not currently evaluated. We argue that every boundary in an agentic pipeline is a site of potential privacy violation and must be assessed independently. To support this, we introduce the Privacy Flow Graph, a Contextual Integrity-grounded framework that decomposes agentic execution into a sequence of information flows, each annotated with the five CI parameters, and traces violations to their point of origin. We present AgentSCOPE, a benchmark of 62 multi-tool scenarios across eight regulatory domains with ground truth at every pipeline stage. Our evaluation across seven state-of-the-art LLMs show that privacy violations in the pipeline occur in over 80% of scenarios, even when final outputs appear clean (24%), with most violations arising at the tool-response stage where APIs return sensitive data indiscriminately. These results indicate that output-level evaluation alone substantially underestimates the privacy risk of agentic systems.
Proceedings of 1st Workshop on Advancing Artificial Intelligence through Theory of Mind
Apr 28, 2025



This volume includes a selection of papers presented at the Workshop on Advancing Artificial Intelligence through Theory of Mind held at AAAI 2025 in Philadelphia US on 3rd March 2025. The purpose of this volume is to provide an open access and curated anthology for the ToM and AI research community.
Which Contributions Deserve Credit? Perceptions of Attribution in Human-AI Co-Creation
Feb 25, 2025

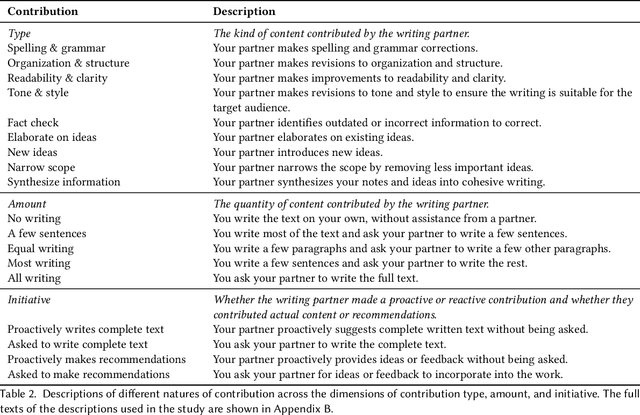

AI systems powered by large language models can act as capable assistants for writing and editing. In these tasks, the AI system acts as a co-creative partner, making novel contributions to an artifact-under-creation alongside its human partner(s). One question that arises in these scenarios is the extent to which AI should be credited for its contributions. We examined knowledge workers' views of attribution through a survey study (N=155) and found that they assigned different levels of credit across different contribution types, amounts, and initiative. Compared to a human partner, we observed a consistent pattern in which AI was assigned less credit for equivalent contributions. Participants felt that disclosing AI involvement was important and used a variety of criteria to make attribution judgments, including the quality of contributions, personal values, and technology considerations. Our results motivate and inform new approaches for crediting AI contributions to co-created work.
Protecting Users From Themselves: Safeguarding Contextual Privacy in Interactions with Conversational Agents
Feb 22, 2025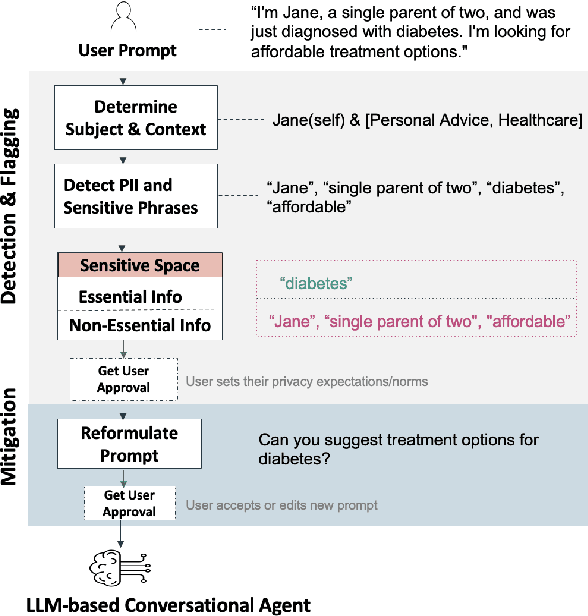

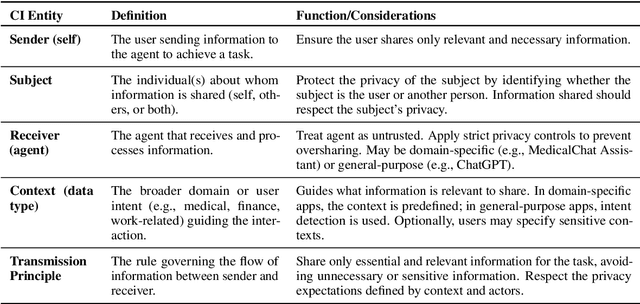
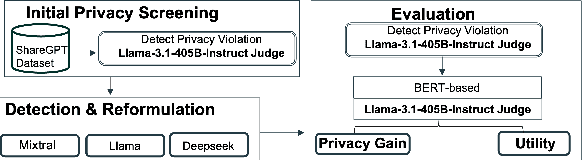
Conversational agents are increasingly woven into individuals' personal lives, yet users often underestimate the privacy risks involved. The moment users share information with these agents (e.g., LLMs), their private information becomes vulnerable to exposure. In this paper, we characterize the notion of contextual privacy for user interactions with LLMs. It aims to minimize privacy risks by ensuring that users (sender) disclose only information that is both relevant and necessary for achieving their intended goals when interacting with LLMs (untrusted receivers). Through a formative design user study, we observe how even "privacy-conscious" users inadvertently reveal sensitive information through indirect disclosures. Based on insights from this study, we propose a locally-deployable framework that operates between users and LLMs, and identifies and reformulates out-of-context information in user prompts. Our evaluation using examples from ShareGPT shows that lightweight models can effectively implement this framework, achieving strong gains in contextual privacy while preserving the user's intended interaction goals through different approaches to classify information relevant to the intended goals.
Can Large Language Models Adapt to Other Agents In-Context?
Dec 27, 2024As the research community aims to build better AI assistants that are more dynamic and personalized to the diversity of humans that they interact with, there is increased interest in evaluating the theory of mind capabilities of large language models (LLMs). Indeed, several recent studies suggest that LLM theory of mind capabilities are quite impressive, approximating human-level performance. Our paper aims to rebuke this narrative and argues instead that past studies were not directly measuring agent performance, potentially leading to findings that are illusory in nature as a result. We draw a strong distinction between what we call literal theory of mind i.e. measuring the agent's ability to predict the behavior of others and functional theory of mind i.e. adapting to agents in-context based on a rational response to predictions of their behavior. We find that top performing open source LLMs may display strong capabilities in literal theory of mind, depending on how they are prompted, but seem to struggle with functional theory of mind -- even when partner policies are exceedingly simple. Our work serves to highlight the double sided nature of inductive bias in LLMs when adapting to new situations. While this bias can lead to strong performance over limited horizons, it often hinders convergence to optimal long-term behavior.
Facilitating Human-LLM Collaboration through Factuality Scores and Source Attributions
May 30, 2024



While humans increasingly rely on large language models (LLMs), they are susceptible to generating inaccurate or false information, also known as "hallucinations". Technical advancements have been made in algorithms that detect hallucinated content by assessing the factuality of the model's responses and attributing sections of those responses to specific source documents. However, there is limited research on how to effectively communicate this information to users in ways that will help them appropriately calibrate their trust toward LLMs. To address this issue, we conducted a scenario-based study (N=104) to systematically compare the impact of various design strategies for communicating factuality and source attribution on participants' ratings of trust, preferences, and ease in validating response accuracy. Our findings reveal that participants preferred a design in which phrases within a response were color-coded based on the computed factuality scores. Additionally, participants increased their trust ratings when relevant sections of the source material were highlighted or responses were annotated with reference numbers corresponding to those sources, compared to when they received no annotation in the source material. Our study offers practical design guidelines to facilitate human-LLM collaboration and it promotes a new human role to carefully evaluate and take responsibility for their use of LLM outputs.
Design Principles for Generative AI Applications
Jan 25, 2024



Generative AI applications present unique design challenges. As generative AI technologies are increasingly being incorporated into mainstream applications, there is an urgent need for guidance on how to design user experiences that foster effective and safe use. We present six principles for the design of generative AI applications that address unique characteristics of generative AI UX and offer new interpretations and extensions of known issues in the design of AI applications. Each principle is coupled with a set of design strategies for implementing that principle via UX capabilities or through the design process. The principles and strategies were developed through an iterative process involving literature review, feedback from design practitioners, validation against real-world generative AI applications, and incorporation into the design process of two generative AI applications. We anticipate the principles to usefully inform the design of generative AI applications by driving actionable design recommendations.
A Case Study in Engineering a Conversational Programming Assistant's Persona
Jan 13, 2023The Programmer's Assistant is an experimental prototype software development environment that integrates a chatbot with a code editor. Conversational capability was achieved by using an existing code-fluent Large Language Model and providing it with a prompt that establishes a conversational interaction pattern, a set of conventions, and a style of interaction appropriate for the application. A discussion of the evolution of the prompt provides a case study in how to coax an existing foundation model to behave in a desirable manner for a particular application.
Toward General Design Principles for Generative AI Applications
Jan 13, 2023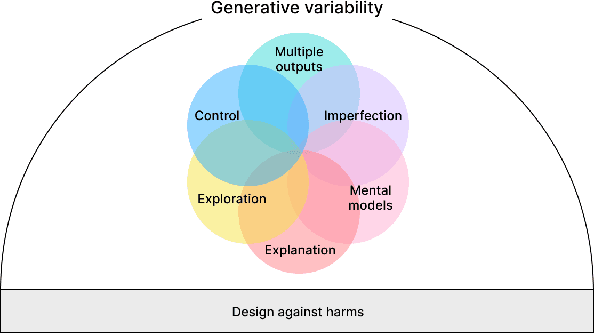
Generative AI technologies are growing in power, utility, and use. As generative technologies are being incorporated into mainstream applications, there is a need for guidance on how to design those applications to foster productive and safe use. Based on recent research on human-AI co-creation within the HCI and AI communities, we present a set of seven principles for the design of generative AI applications. These principles are grounded in an environment of generative variability. Six principles are focused on designing for characteristics of generative AI: multiple outcomes & imperfection; exploration & control; and mental models & explanations. In addition, we urge designers to design against potential harms that may be caused by a generative model's hazardous output, misuse, or potential for human displacement. We anticipate these principles to usefully inform design decisions made in the creation of novel human-AI applications, and we invite the community to apply, revise, and extend these principles to their own work.
Investigating Explainability of Generative AI for Code through Scenario-based Design
Feb 10, 2022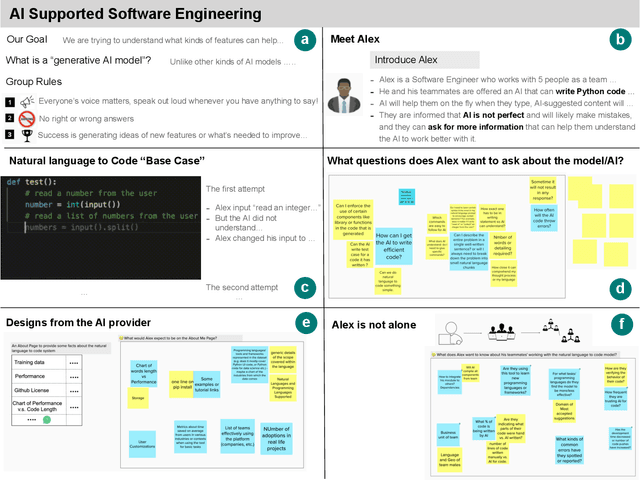
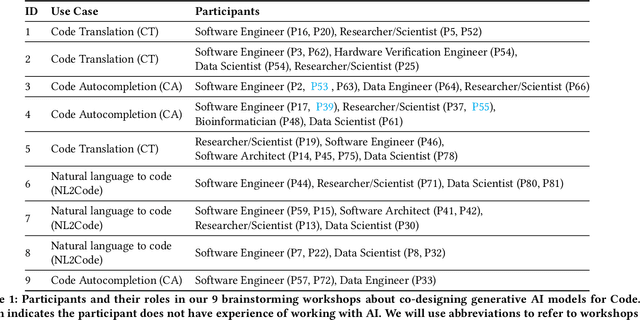

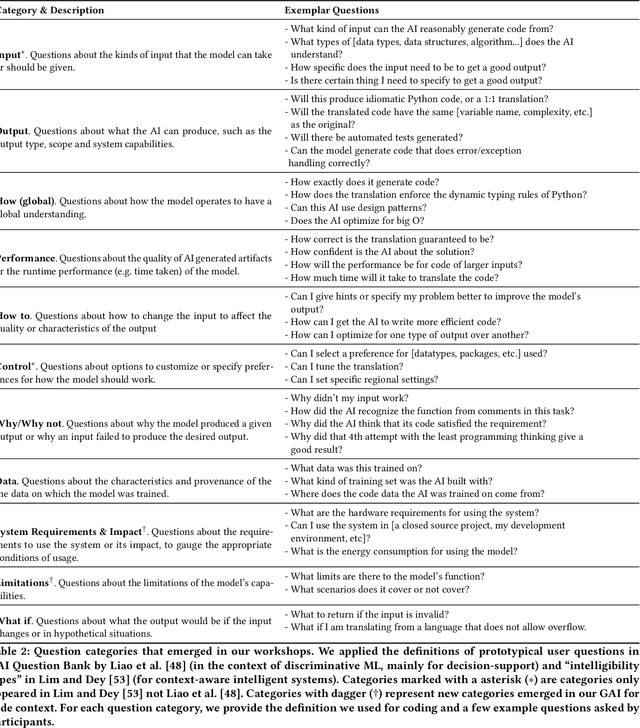
What does it mean for a generative AI model to be explainable? The emergent discipline of explainable AI (XAI) has made great strides in helping people understand discriminative models. Less attention has been paid to generative models that produce artifacts, rather than decisions, as output. Meanwhile, generative AI (GenAI) technologies are maturing and being applied to application domains such as software engineering. Using scenario-based design and question-driven XAI design approaches, we explore users' explainability needs for GenAI in three software engineering use cases: natural language to code, code translation, and code auto-completion. We conducted 9 workshops with 43 software engineers in which real examples from state-of-the-art generative AI models were used to elicit users' explainability needs. Drawing from prior work, we also propose 4 types of XAI features for GenAI for code and gathered additional design ideas from participants. Our work explores explainability needs for GenAI for code and demonstrates how human-centered approaches can drive the technical development of XAI in novel domains.