 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQuantitative AI Risk Assessments: Opportunities and Challenges
Sep 13, 2022Although AI-based systems are increasingly being leveraged to provide value to organizations, individuals, and society, significant attendant risks have been identified. These risks have led to proposed regulations, litigation, and general societal concerns. As with any promising technology, organizations want to benefit from the positive capabilities of AI technology while reducing the risks. The best way to reduce risks is to implement comprehensive AI lifecycle governance where policies and procedures are described and enforced during the design, development, deployment, and monitoring of an AI system. While support for comprehensive governance is beginning to emerge, organizations often need to identify the risks of deploying an already-built model without knowledge of how it was constructed or access to its original developers. Such an assessment will quantitatively assess the risks of an existing model in a manner analogous to how a home inspector might assess the energy efficiency of an already-built home or a physician might assess overall patient health based on a battery of tests. This paper explores the concept of a quantitative AI Risk Assessment, exploring the opportunities, challenges, and potential impacts of such an approach, and discussing how it might improve AI regulations.
Evaluating a Methodology for Increasing AI Transparency: A Case Study
Jan 24, 2022



In reaction to growing concerns about the potential harms of artificial intelligence (AI), societies have begun to demand more transparency about how AI models and systems are created and used. To address these concerns, several efforts have proposed documentation templates containing questions to be answered by model developers. These templates provide a useful starting point, but no single template can cover the needs of diverse documentation consumers. It is possible in principle, however, to create a repeatable methodology to generate truly useful documentation. Richards et al. [25] proposed such a methodology for identifying specific documentation needs and creating templates to address those needs. Although this is a promising proposal, it has not been evaluated. This paper presents the first evaluation of this user-centered methodology in practice, reporting on the experiences of a team in the domain of AI for healthcare that adopted it to increase transparency for several AI models. The methodology was found to be usable by developers not trained in user-centered techniques, guiding them to creating a documentation template that addressed the specific needs of their consumers while still being reusable across different models and use cases. Analysis of the benefits and costs of this methodology are reviewed and suggestions for further improvement in both the methodology and supporting tools are summarized.
Using Document Similarity Methods to create Parallel Datasets for Code Translation
Oct 11, 2021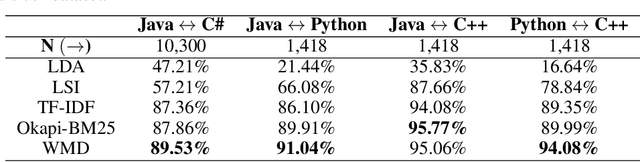
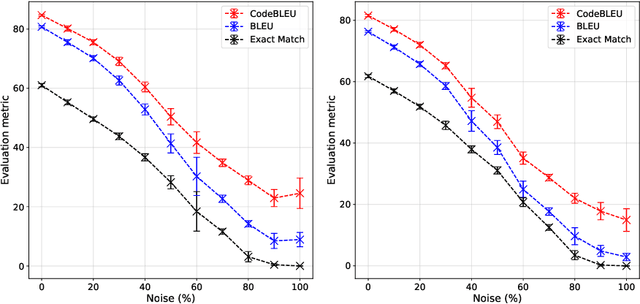
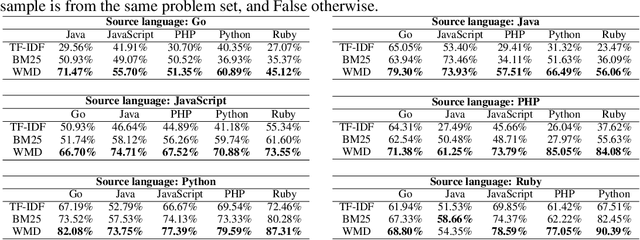
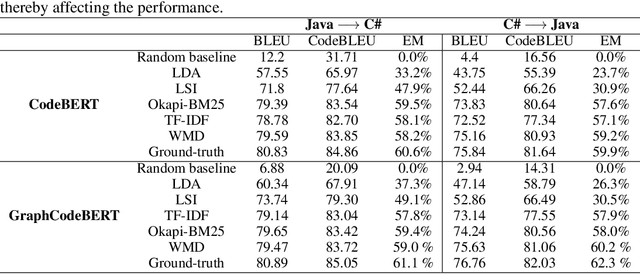
Translating source code from one programming language to another is a critical, time-consuming task in modernizing legacy applications and codebases. Recent work in this space has drawn inspiration from the software naturalness hypothesis by applying natural language processing techniques towards automating the code translation task. However, due to the paucity of parallel data in this domain, supervised techniques have only been applied to a limited set of popular programming languages. To bypass this limitation, unsupervised neural machine translation techniques have been proposed to learn code translation using only monolingual corpora. In this work, we propose to use document similarity methods to create noisy parallel datasets of code, thus enabling supervised techniques to be applied for automated code translation without having to rely on the availability or expensive curation of parallel code datasets. We explore the noise tolerance of models trained on such automatically-created datasets and show that these models perform comparably to models trained on ground truth for reasonable levels of noise. Finally, we exhibit the practical utility of the proposed method by creating parallel datasets for languages beyond the ones explored in prior work, thus expanding the set of programming languages for automated code translation.
AI Explainability 360: Impact and Design
Sep 24, 2021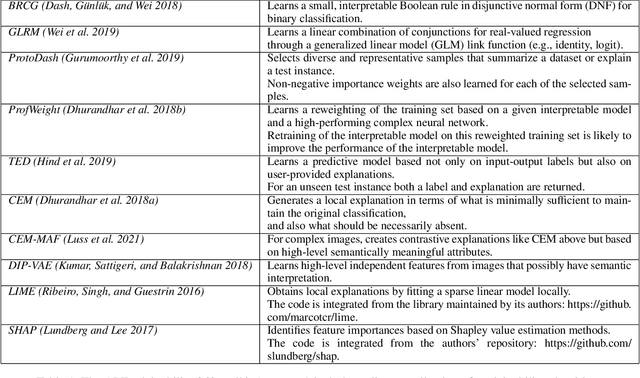
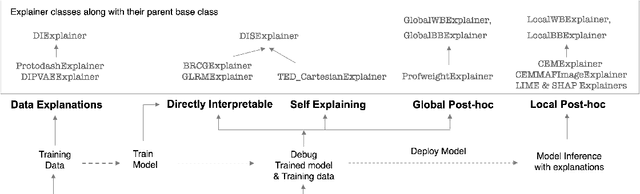

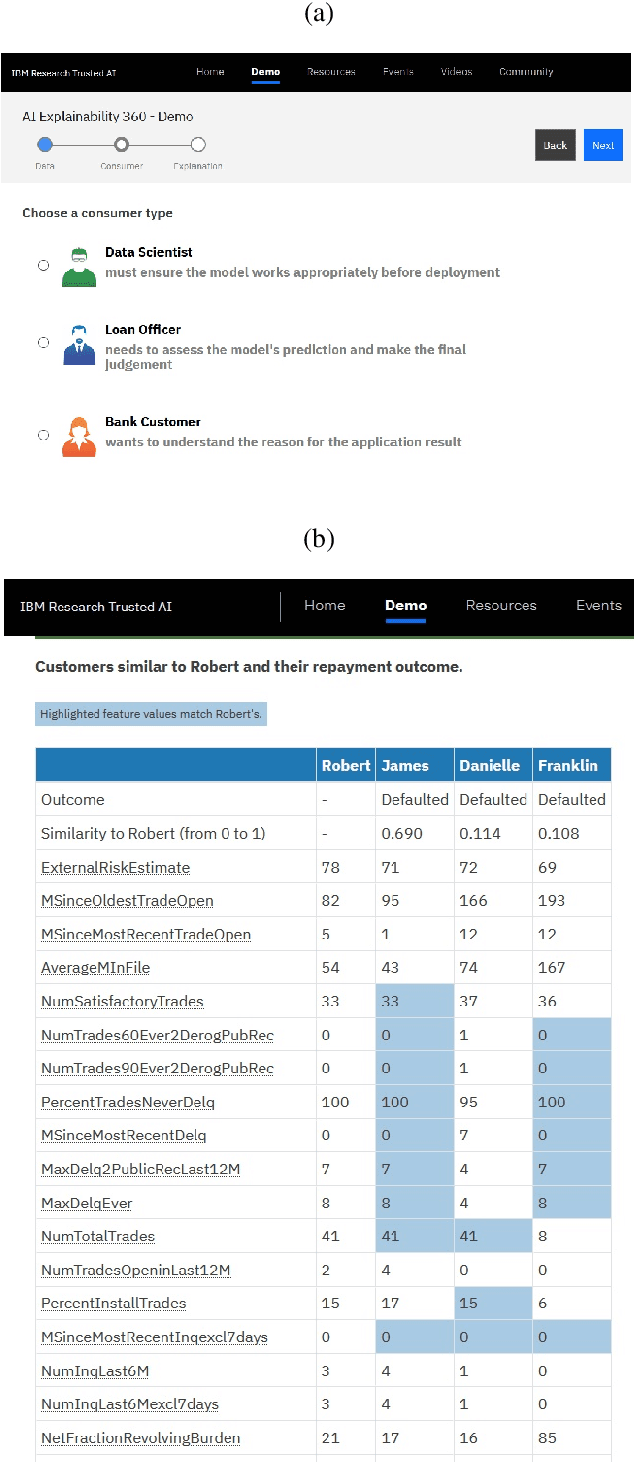
As artificial intelligence and machine learning algorithms become increasingly prevalent in society, multiple stakeholders are calling for these algorithms to provide explanations. At the same time, these stakeholders, whether they be affected citizens, government regulators, domain experts, or system developers, have different explanation needs. To address these needs, in 2019, we created AI Explainability 360 (Arya et al. 2020), an open source software toolkit featuring ten diverse and state-of-the-art explainability methods and two evaluation metrics. This paper examines the impact of the toolkit with several case studies, statistics, and community feedback. The different ways in which users have experienced AI Explainability 360 have resulted in multiple types of impact and improvements in multiple metrics, highlighted by the adoption of the toolkit by the independent LF AI & Data Foundation. The paper also describes the flexible design of the toolkit, examples of its use, and the significant educational material and documentation available to its users.
Towards evaluating and eliciting high-quality documentation for intelligent systems
Nov 17, 2020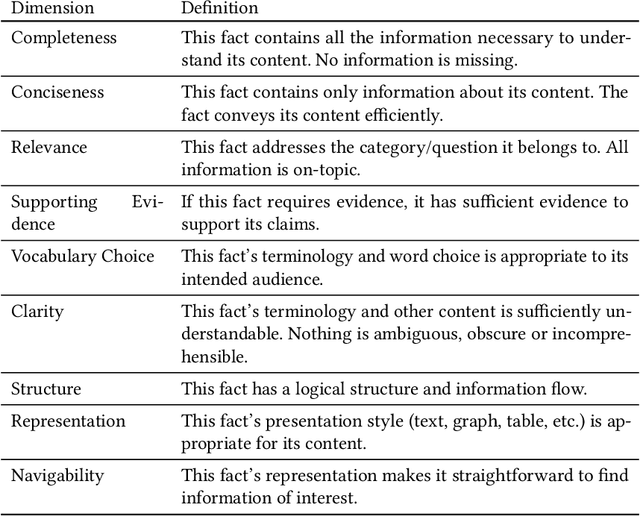

A vital component of trust and transparency in intelligent systems built on machine learning and artificial intelligence is the development of clear, understandable documentation. However, such systems are notorious for their complexity and opaqueness making quality documentation a non-trivial task. Furthermore, little is known about what makes such documentation "good." In this paper, we propose and evaluate a set of quality dimensions to identify in what ways this type of documentation falls short. Then, using those dimensions, we evaluate three different approaches for eliciting intelligent system documentation. We show how the dimensions identify shortcomings in such documentation and posit how such dimensions can be use to further enable users to provide documentation that is suitable to a given persona or use case.
A Methodology for Creating AI FactSheets
Jun 28, 2020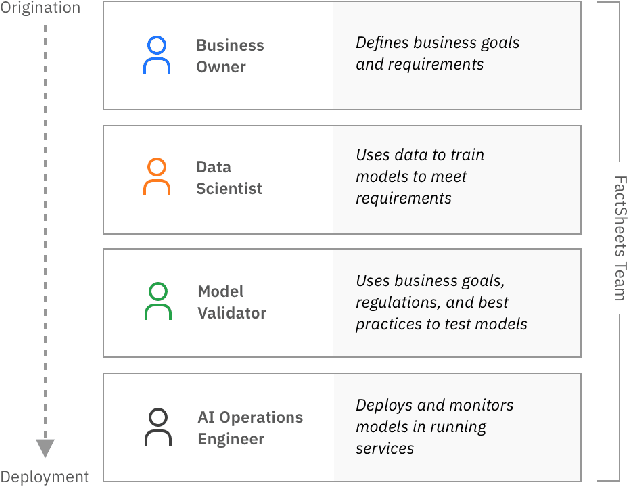


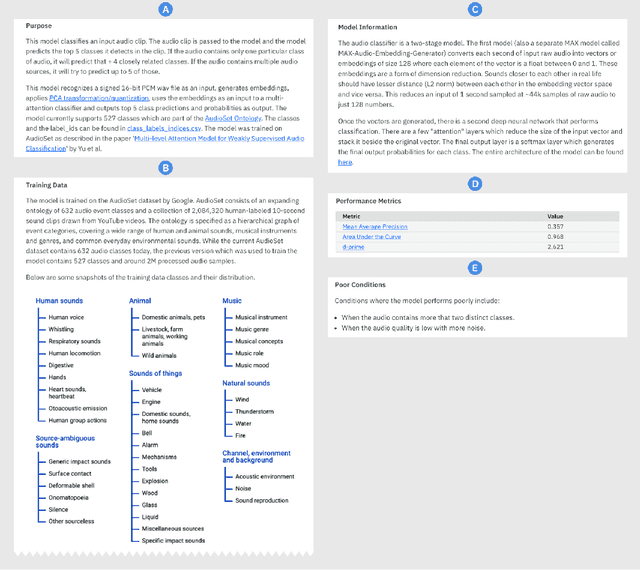
As AI models and services are used in a growing number of highstakes areas, a consensus is forming around the need for a clearer record of how these models and services are developed to increase trust. Several proposals for higher quality and more consistent AI documentation have emerged to address ethical and legal concerns and general social impacts of such systems. However, there is little published work on how to create this documentation. This is the first work to describe a methodology for creating the form of AI documentation we call FactSheets. We have used this methodology to create useful FactSheets for nearly two dozen models. This paper describes this methodology and shares the insights we have gathered. Within each step of the methodology, we describe the issues to consider and the questions to explore with the relevant people in an organization who will be creating and consuming the AI facts in a FactSheet. This methodology will accelerate the broader adoption of transparent AI documentation.
One Explanation Does Not Fit All: A Toolkit and Taxonomy of AI Explainability Techniques
Sep 14, 2019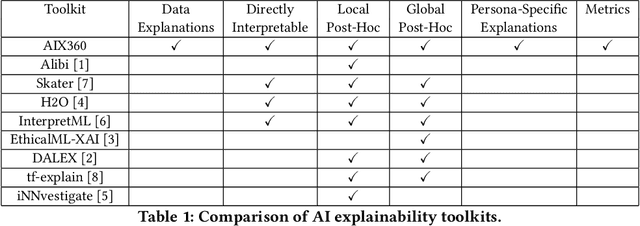
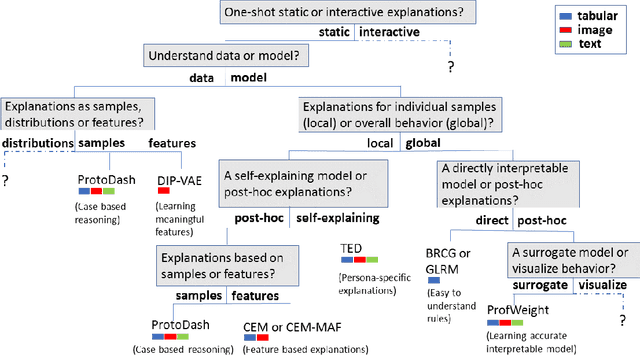
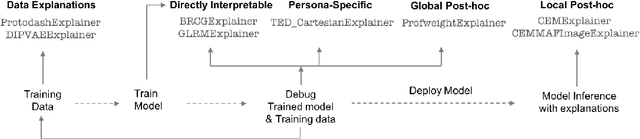
As artificial intelligence and machine learning algorithms make further inroads into society, calls are increasing from multiple stakeholders for these algorithms to explain their outputs. At the same time, these stakeholders, whether they be affected citizens, government regulators, domain experts, or system developers, present different requirements for explanations. Toward addressing these needs, we introduce AI Explainability 360 (http://aix360.mybluemix.net/), an open-source software toolkit featuring eight diverse and state-of-the-art explainability methods and two evaluation metrics. Equally important, we provide a taxonomy to help entities requiring explanations to navigate the space of explanation methods, not only those in the toolkit but also in the broader literature on explainability. For data scientists and other users of the toolkit, we have implemented an extensible software architecture that organizes methods according to their place in the AI modeling pipeline. We also discuss enhancements to bring research innovations closer to consumers of explanations, ranging from simplified, more accessible versions of algorithms, to tutorials and an interactive web demo to introduce AI explainability to different audiences and application domains. Together, our toolkit and taxonomy can help identify gaps where more explainability methods are needed and provide a platform to incorporate them as they are developed.
AI Fairness 360: An Extensible Toolkit for Detecting, Understanding, and Mitigating Unwanted Algorithmic Bias
Oct 03, 2018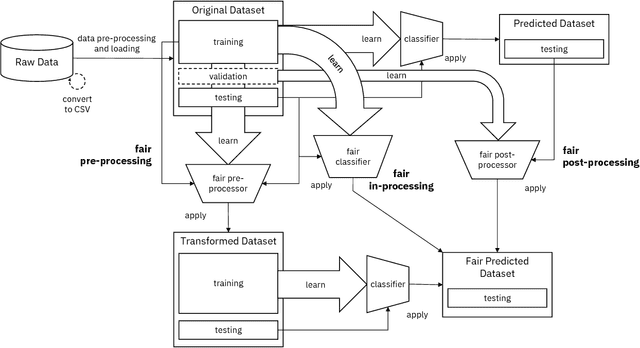
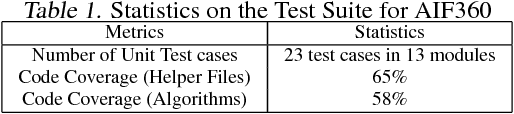
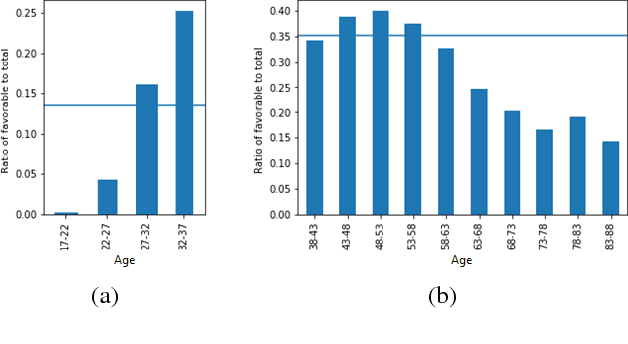
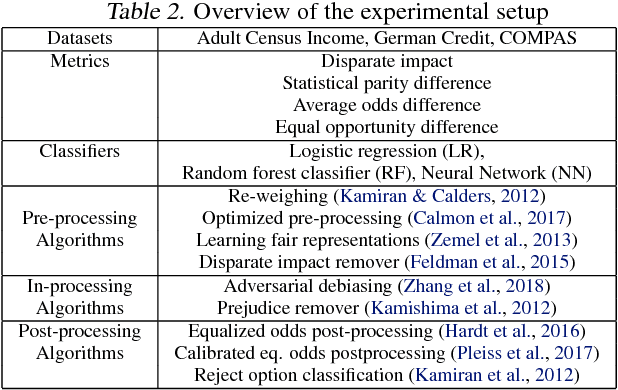
Fairness is an increasingly important concern as machine learning models are used to support decision making in high-stakes applications such as mortgage lending, hiring, and prison sentencing. This paper introduces a new open source Python toolkit for algorithmic fairness, AI Fairness 360 (AIF360), released under an Apache v2.0 license {https://github.com/ibm/aif360). The main objectives of this toolkit are to help facilitate the transition of fairness research algorithms to use in an industrial setting and to provide a common framework for fairness researchers to share and evaluate algorithms. The package includes a comprehensive set of fairness metrics for datasets and models, explanations for these metrics, and algorithms to mitigate bias in datasets and models. It also includes an interactive Web experience (https://aif360.mybluemix.net) that provides a gentle introduction to the concepts and capabilities for line-of-business users, as well as extensive documentation, usage guidance, and industry-specific tutorials to enable data scientists and practitioners to incorporate the most appropriate tool for their problem into their work products. The architecture of the package has been engineered to conform to a standard paradigm used in data science, thereby further improving usability for practitioners. Such architectural design and abstractions enable researchers and developers to extend the toolkit with their new algorithms and improvements, and to use it for performance benchmarking. A built-in testing infrastructure maintains code quality.
Detecting Egregious Conversations between Customers and Virtual Agents
Apr 16, 2018
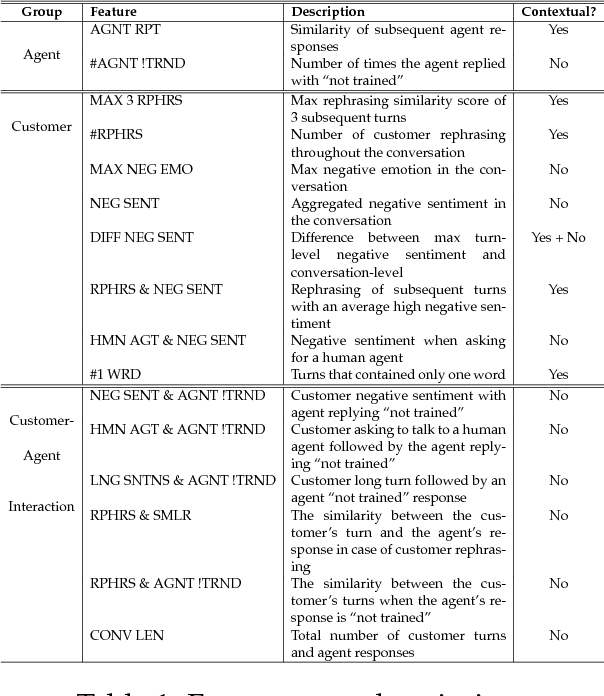
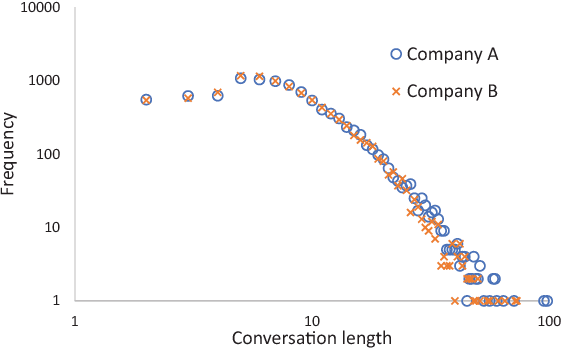

Virtual agents are becoming a prominent channel of interaction in customer service. Not all customer interactions are smooth, however, and some can become almost comically bad. In such instances, a human agent might need to step in and salvage the conversation. Detecting bad conversations is important since disappointing customer service may threaten customer loyalty and impact revenue. In this paper, we outline an approach to detecting such egregious conversations, using behavioral cues from the user, patterns in agent responses, and user-agent interaction. Using logs of two commercial systems, we show that using these features improves the detection F1-score by around 20% over using textual features alone. In addition, we show that those features are common across two quite different domains and, arguably, universal.