 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAI Explainability 360: Impact and Design
Sep 24, 2021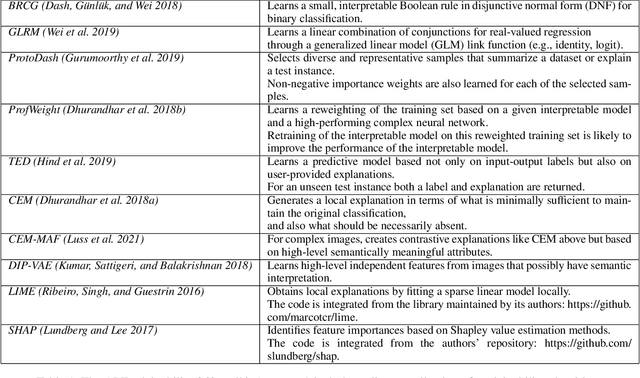
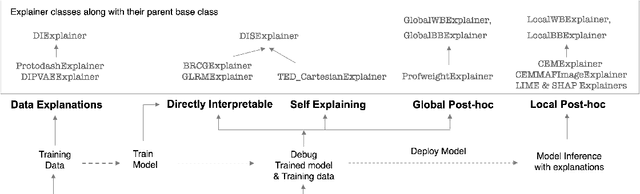

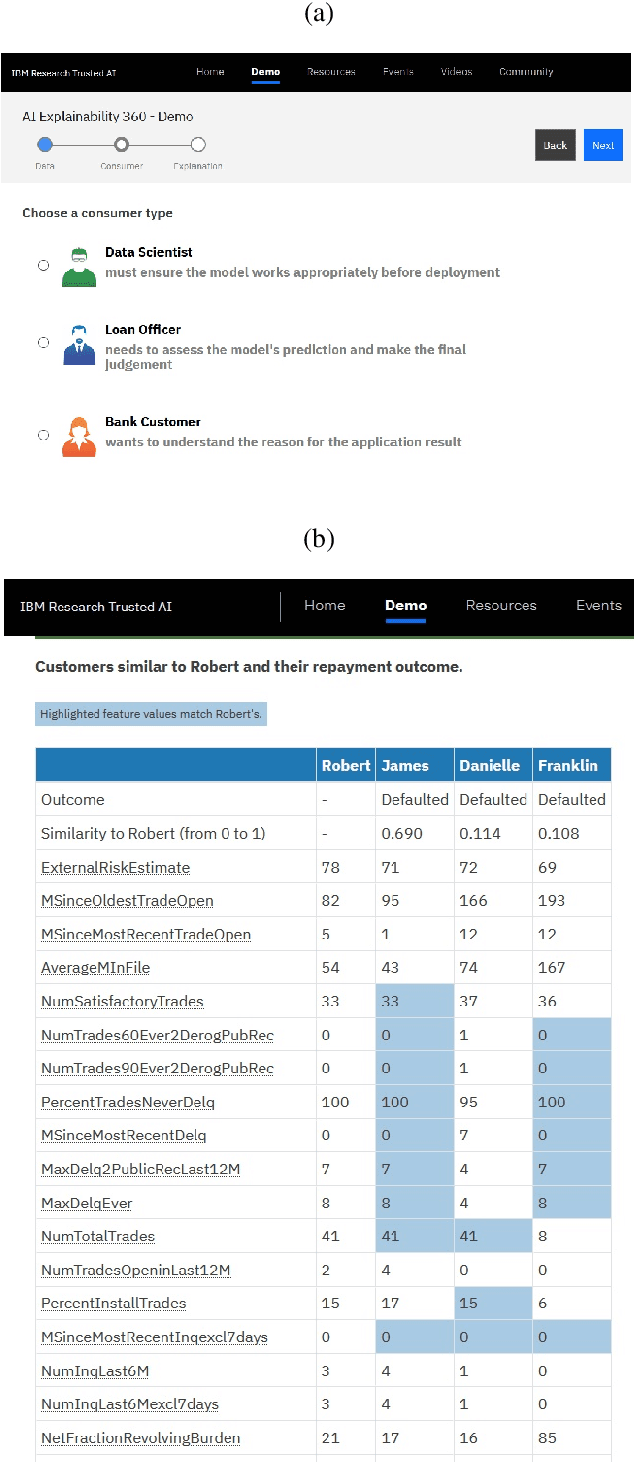
As artificial intelligence and machine learning algorithms become increasingly prevalent in society, multiple stakeholders are calling for these algorithms to provide explanations. At the same time, these stakeholders, whether they be affected citizens, government regulators, domain experts, or system developers, have different explanation needs. To address these needs, in 2019, we created AI Explainability 360 (Arya et al. 2020), an open source software toolkit featuring ten diverse and state-of-the-art explainability methods and two evaluation metrics. This paper examines the impact of the toolkit with several case studies, statistics, and community feedback. The different ways in which users have experienced AI Explainability 360 have resulted in multiple types of impact and improvements in multiple metrics, highlighted by the adoption of the toolkit by the independent LF AI & Data Foundation. The paper also describes the flexible design of the toolkit, examples of its use, and the significant educational material and documentation available to its users.
Joint Optimization of AI Fairness and Utility: A Human-Centered Approach
Feb 05, 2020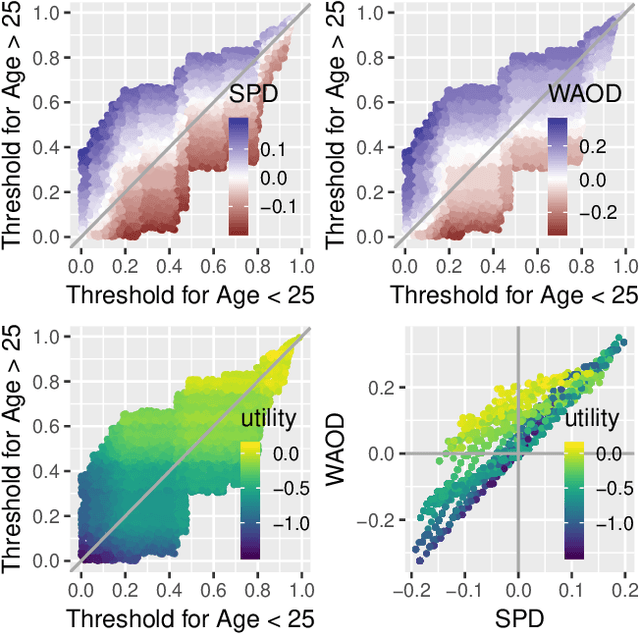
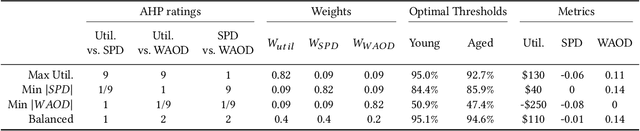
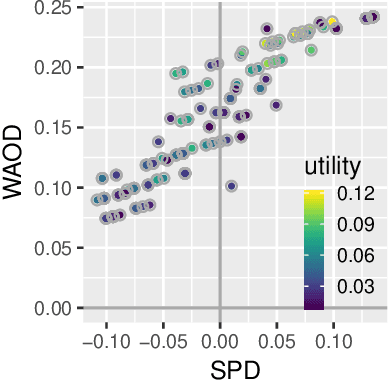

Today, AI is increasingly being used in many high-stakes decision-making applications in which fairness is an important concern. Already, there are many examples of AI being biased and making questionable and unfair decisions. The AI research community has proposed many methods to measure and mitigate unwanted biases, but few of them involve inputs from human policy makers. We argue that because different fairness criteria sometimes cannot be simultaneously satisfied, and because achieving fairness often requires sacrificing other objectives such as model accuracy, it is key to acquire and adhere to human policy makers' preferences on how to make the tradeoff among these objectives. In this paper, we propose a framework and some exemplar methods for eliciting such preferences and for optimizing an AI model according to these preferences.
Effect of Confidence and Explanation on Accuracy and Trust Calibration in AI-Assisted Decision Making
Jan 07, 2020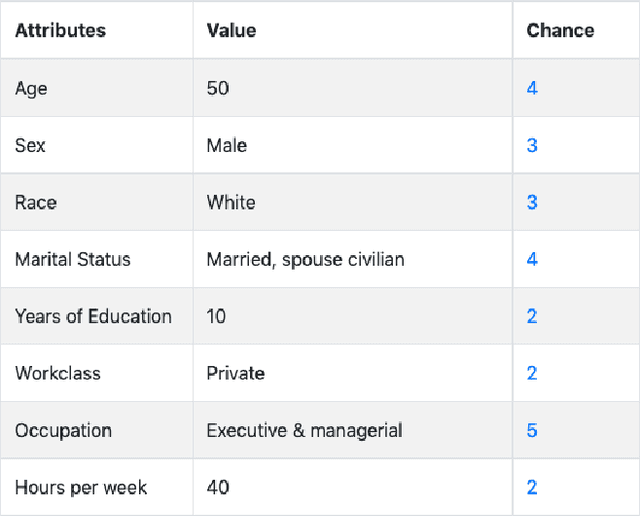
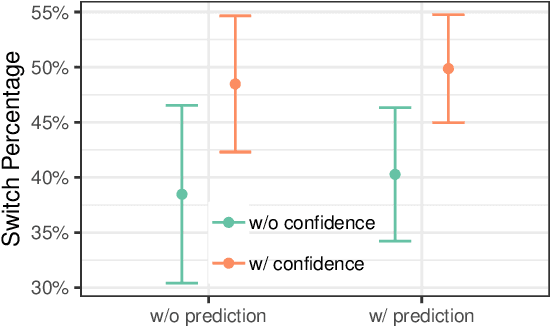
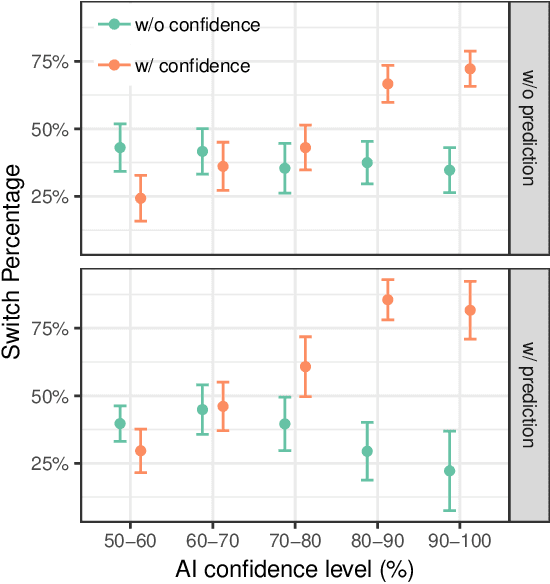
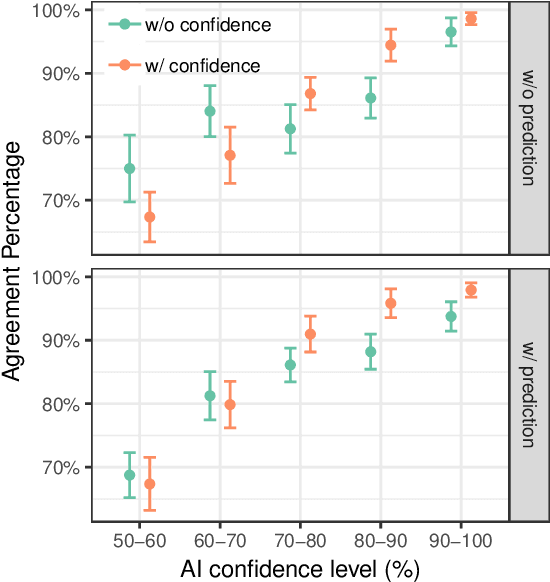
Today, AI is being increasingly used to help human experts make decisions in high-stakes scenarios. In these scenarios, full automation is often undesirable, not only due to the significance of the outcome, but also because human experts can draw on their domain knowledge complementary to the model's to ensure task success. We refer to these scenarios as AI-assisted decision making, where the individual strengths of the human and the AI come together to optimize the joint decision outcome. A key to their success is to appropriately \textit{calibrate} human trust in the AI on a case-by-case basis; knowing when to trust or distrust the AI allows the human expert to appropriately apply their knowledge, improving decision outcomes in cases where the model is likely to perform poorly. This research conducts a case study of AI-assisted decision making in which humans and AI have comparable performance alone, and explores whether features that reveal case-specific model information can calibrate trust and improve the joint performance of the human and AI. Specifically, we study the effect of showing confidence score and local explanation for a particular prediction. Through two human experiments, we show that confidence score can help calibrate people's trust in an AI model, but trust calibration alone is not sufficient to improve AI-assisted decision making, which may also depend on whether the human can bring in enough unique knowledge to complement the AI's errors. We also highlight the problems in using local explanation for AI-assisted decision making scenarios and invite the research community to explore new approaches to explainability for calibrating human trust in AI.
One Explanation Does Not Fit All: A Toolkit and Taxonomy of AI Explainability Techniques
Sep 14, 2019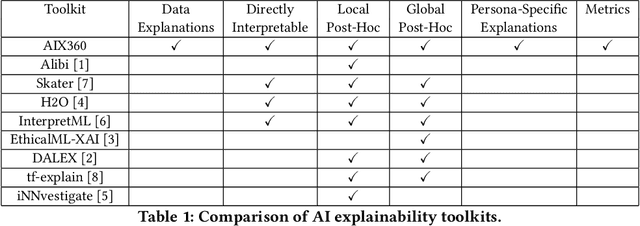
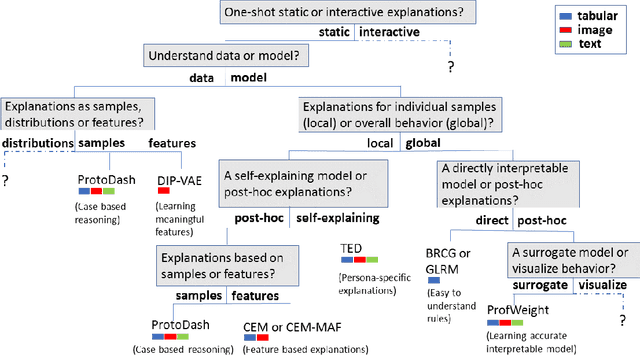
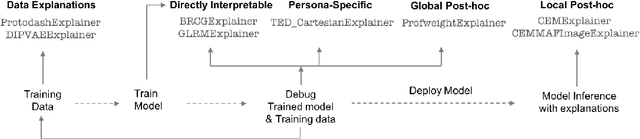
As artificial intelligence and machine learning algorithms make further inroads into society, calls are increasing from multiple stakeholders for these algorithms to explain their outputs. At the same time, these stakeholders, whether they be affected citizens, government regulators, domain experts, or system developers, present different requirements for explanations. Toward addressing these needs, we introduce AI Explainability 360 (http://aix360.mybluemix.net/), an open-source software toolkit featuring eight diverse and state-of-the-art explainability methods and two evaluation metrics. Equally important, we provide a taxonomy to help entities requiring explanations to navigate the space of explanation methods, not only those in the toolkit but also in the broader literature on explainability. For data scientists and other users of the toolkit, we have implemented an extensible software architecture that organizes methods according to their place in the AI modeling pipeline. We also discuss enhancements to bring research innovations closer to consumers of explanations, ranging from simplified, more accessible versions of algorithms, to tutorials and an interactive web demo to introduce AI explainability to different audiences and application domains. Together, our toolkit and taxonomy can help identify gaps where more explainability methods are needed and provide a platform to incorporate them as they are developed.
Bootstrapping Conversational Agents With Weak Supervision
Dec 14, 2018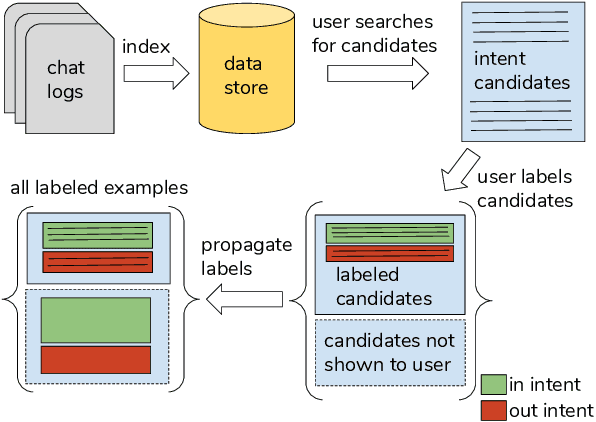

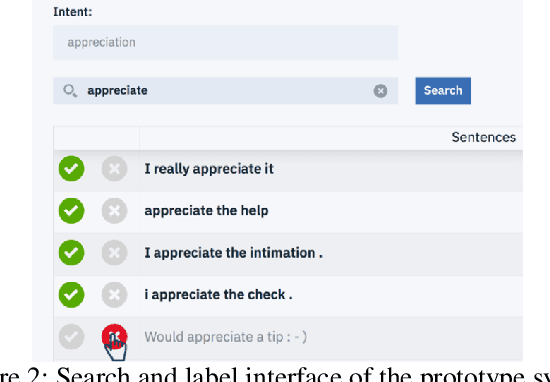
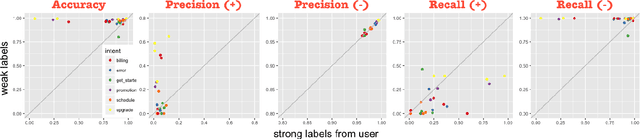
Many conversational agents in the market today follow a standard bot development framework which requires training intent classifiers to recognize user input. The need to create a proper set of training examples is often the bottleneck in the development process. In many occasions agent developers have access to historical chat logs that can provide a good quantity as well as coverage of training examples. However, the cost of labeling them with tens to hundreds of intents often prohibits taking full advantage of these chat logs. In this paper, we present a framework called \textit{search, label, and propagate} (SLP) for bootstrapping intents from existing chat logs using weak supervision. The framework reduces hours to days of labeling effort down to minutes of work by using a search engine to find examples, then relies on a data programming approach to automatically expand the labels. We report on a user study that shows positive user feedback for this new approach to build conversational agents, and demonstrates the effectiveness of using data programming for auto-labeling. While the system is developed for training conversational agents, the framework has broader application in significantly reducing labeling effort for training text classifiers.
AI Fairness 360: An Extensible Toolkit for Detecting, Understanding, and Mitigating Unwanted Algorithmic Bias
Oct 03, 2018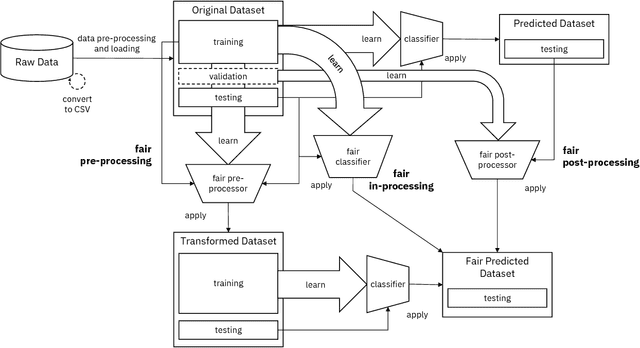
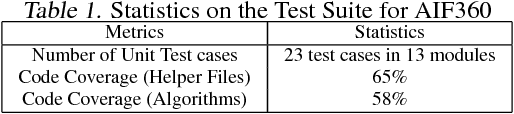
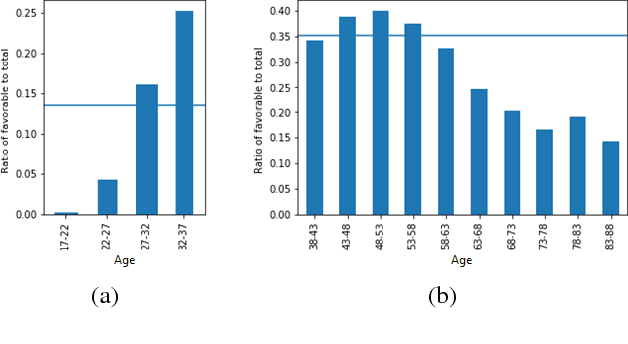
Fairness is an increasingly important concern as machine learning models are used to support decision making in high-stakes applications such as mortgage lending, hiring, and prison sentencing. This paper introduces a new open source Python toolkit for algorithmic fairness, AI Fairness 360 (AIF360), released under an Apache v2.0 license {https://github.com/ibm/aif360). The main objectives of this toolkit are to help facilitate the transition of fairness research algorithms to use in an industrial setting and to provide a common framework for fairness researchers to share and evaluate algorithms. The package includes a comprehensive set of fairness metrics for datasets and models, explanations for these metrics, and algorithms to mitigate bias in datasets and models. It also includes an interactive Web experience (https://aif360.mybluemix.net) that provides a gentle introduction to the concepts and capabilities for line-of-business users, as well as extensive documentation, usage guidance, and industry-specific tutorials to enable data scientists and practitioners to incorporate the most appropriate tool for their problem into their work products. The architecture of the package has been engineered to conform to a standard paradigm used in data science, thereby further improving usability for practitioners. Such architectural design and abstractions enable researchers and developers to extend the toolkit with their new algorithms and improvements, and to use it for performance benchmarking. A built-in testing infrastructure maintains code quality.
Visualizations for an Explainable Planning Agent
Feb 08, 2018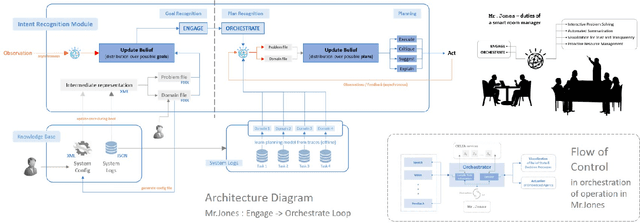
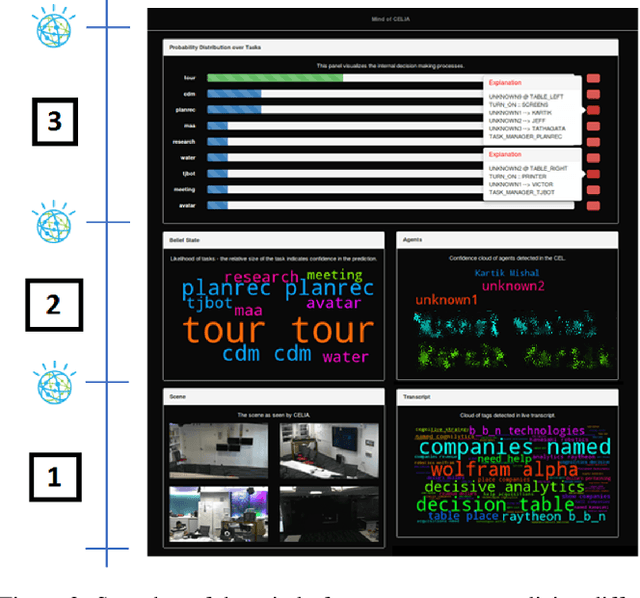


In this paper, we report on the visualization capabilities of an Explainable AI Planning (XAIP) agent that can support human in the loop decision making. Imposing transparency and explainability requirements on such agents is especially important in order to establish trust and common ground with the end-to-end automated planning system. Visualizing the agent's internal decision-making processes is a crucial step towards achieving this. This may include externalizing the "brain" of the agent -- starting from its sensory inputs, to progressively higher order decisions made by it in order to drive its planning components. We also show how the planner can bootstrap on the latest techniques in explainable planning to cast plan visualization as a plan explanation problem, and thus provide concise model-based visualization of its plans. We demonstrate these functionalities in the context of the automated planning components of a smart assistant in an instrumented meeting space.