 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIterative Data Programming for Expanding Text Classification Corpora
Feb 04, 2020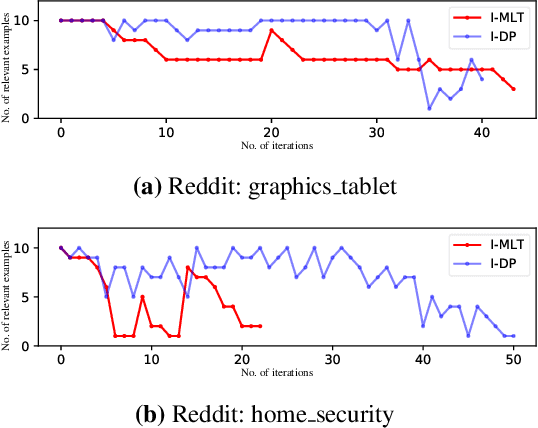
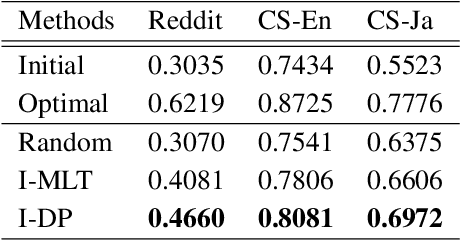
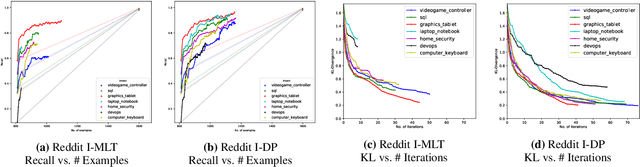
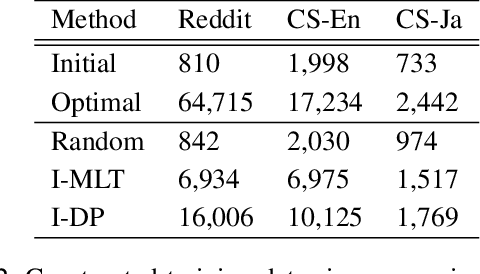
Real-world text classification tasks often require many labeled training examples that are expensive to obtain. Recent advancements in machine teaching, specifically the data programming paradigm, facilitate the creation of training data sets quickly via a general framework for building weak models, also known as labeling functions, and denoising them through ensemble learning techniques. We present a fast, simple data programming method for augmenting text data sets by generating neighborhood-based weak models with minimal supervision. Furthermore, our method employs an iterative procedure to identify sparsely distributed examples from large volumes of unlabeled data. The iterative data programming techniques improve newer weak models as more labeled data is confirmed with human-in-loop. We show empirical results on sentence classification tasks, including those from a task of improving intent recognition in conversational agents.
Bootstrapping Conversational Agents With Weak Supervision
Dec 14, 2018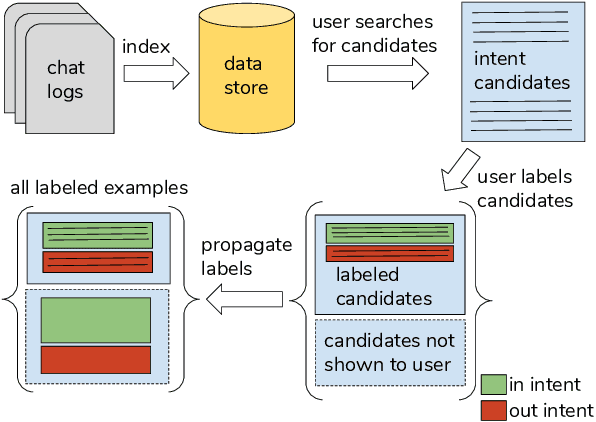

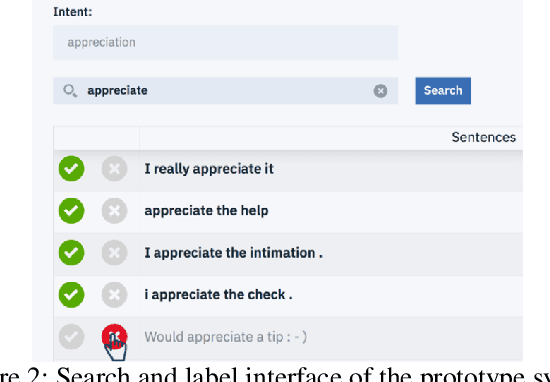
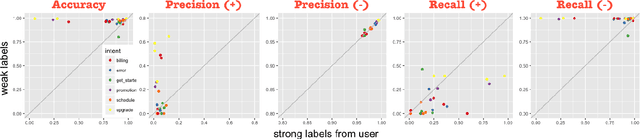
Many conversational agents in the market today follow a standard bot development framework which requires training intent classifiers to recognize user input. The need to create a proper set of training examples is often the bottleneck in the development process. In many occasions agent developers have access to historical chat logs that can provide a good quantity as well as coverage of training examples. However, the cost of labeling them with tens to hundreds of intents often prohibits taking full advantage of these chat logs. In this paper, we present a framework called \textit{search, label, and propagate} (SLP) for bootstrapping intents from existing chat logs using weak supervision. The framework reduces hours to days of labeling effort down to minutes of work by using a search engine to find examples, then relies on a data programming approach to automatically expand the labels. We report on a user study that shows positive user feedback for this new approach to build conversational agents, and demonstrates the effectiveness of using data programming for auto-labeling. While the system is developed for training conversational agents, the framework has broader application in significantly reducing labeling effort for training text classifiers.
Geometrical Complexity of Classification Problems
Feb 11, 2004

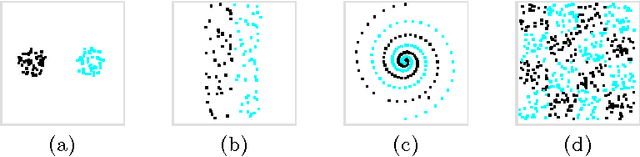

Despite encouraging recent progresses in ensemble approaches, classification methods seem to have reached a plateau in development. Further advances depend on a better understanding of geometrical and topological characteristics of point sets in high-dimensional spaces, the preservation of such characteristics under feature transformations and sampling processes, and their interaction with geometrical models used in classifiers. We discuss an attempt to measure such properties from data sets and relate them to classifier accuracies.
A Numerical Example on the Principles of Stochastic Discrimination
Feb 11, 2004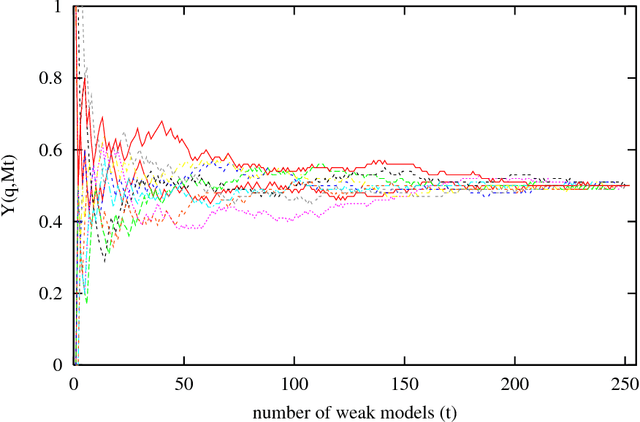
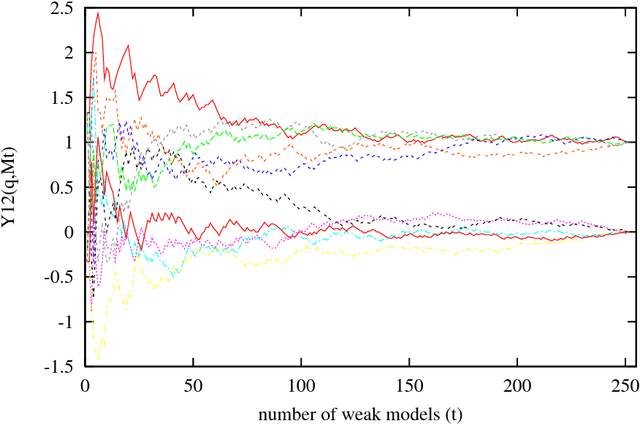

Studies on ensemble methods for classification suffer from the difficulty of modeling the complementary strengths of the components. Kleinberg's theory of stochastic discrimination (SD) addresses this rigorously via mathematical notions of enrichment, uniformity, and projectability of an ensemble. We explain these concepts via a very simple numerical example that captures the basic principles of the SD theory and method. We focus on a fundamental symmetry in point set covering that is the key observation leading to the foundation of the theory. We believe a better understanding of the SD method will lead to developments of better tools for analyzing other ensemble methods.