 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLineMaster Pro: A Low-Cost Intelligent Line Following Robot with PID Control and Ultrasonic Obstacle Avoidance for Educational Robotics
Mar 14, 2026Line following robots are fundamental platforms in robotics education, yet commercially available solutions remain prohibitively expensive ($150-300$) while lacking integrated obstacle detection capabilities essential for real-world applications. This paper presents LineMaster Pro, an intelligent low-cost line following robot implemented on an Arduino Nano platform that integrates dual TCRT5000 infrared sensors for precision line tracking, an HC-SR04 ultrasonic sensor for real-time obstacle detection, a digitally tuned PID controller with Ziegler-Nichols optimization, and a hierarchical finite state machine for robust obstacle avoidance. A systematic four-phase sensor calibration methodology ensures reliable operation across varying lighting and surface conditions. Experimental validation through 200 controlled trials and 72-hour continuous operation demonstrates mean tracking accuracy of 1.18 cm at 0.4 m/s (95\% CI [1.06, 1.30]), obstacle detection reliability of 96.7\% within 10-40 cm range with 0.7\% false positive rate, and 94\% successful recovery from path deviations. The PID implementation achieves 43\% improvement over conventional on-off control ($p<0.001$). At a total hardware cost of \$28.50 based on verified Bangladesh market prices, LineMaster Pro achieves a 94\% cost reduction compared to commercial alternatives, establishing a practical benchmark for accessible robotics education in resource-constrained environments.
A Hybrid Approach for Depression Classification: Random Forest-ANN Ensemble on Motor Activity Signals
Oct 13, 2023Regarding the rising number of people suffering from mental health illnesses in today's society, the importance of mental health cannot be overstated. Wearable sensors, which are increasingly widely available, provide a potential way to track and comprehend mental health issues. These gadgets not only monitor everyday activities but also continuously record vital signs like heart rate, perhaps providing information on a person's mental state. Recent research has used these sensors in conjunction with machine learning methods to identify patterns relating to different mental health conditions, highlighting the immense potential of this data beyond simple activity monitoring. In this research, we present a novel algorithm called the Hybrid Random forest - Neural network that has been tailored to evaluate sensor data from depressed patients. Our method has a noteworthy accuracy of 80\% when evaluated on a special dataset that included both unipolar and bipolar depressive patients as well as healthy controls. The findings highlight the algorithm's potential for reliably determining a person's depression condition using sensor data, making a substantial contribution to the area of mental health diagnostics.
Benchmarking Intent Detection for Task-Oriented Dialog Systems
Dec 07, 2020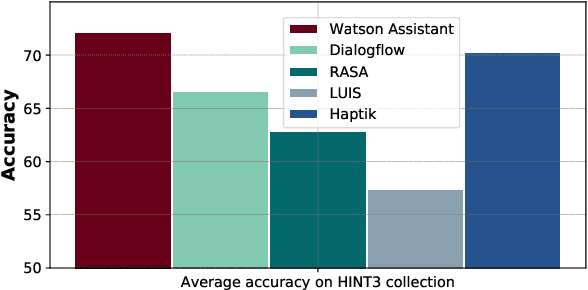
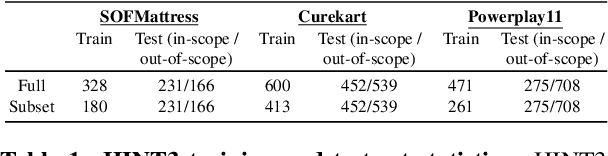
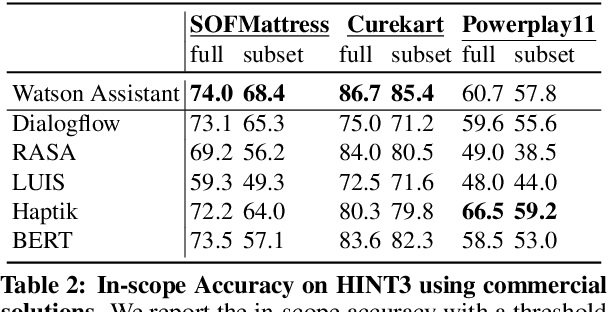
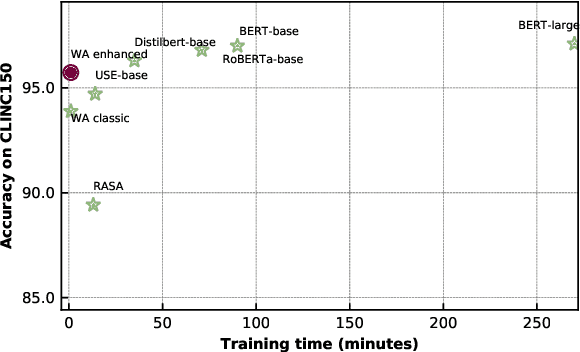
Intent detection is a key component of modern goal-oriented dialog systems that accomplish a user task by predicting the intent of users' text input. There are three primary challenges in designing robust and accurate intent detection models. First, typical intent detection models require a large amount of labeled data to achieve high accuracy. Unfortunately, in practical scenarios it is more common to find small, unbalanced, and noisy datasets. Secondly, even with large training data, the intent detection models can see a different distribution of test data when being deployed in the real world, leading to poor accuracy. Finally, a practical intent detection model must be computationally efficient in both training and single query inference so that it can be used continuously and re-trained frequently. We benchmark intent detection methods on a variety of datasets. Our results show that Watson Assistant's intent detection model outperforms other commercial solutions and is comparable to large pretrained language models while requiring only a fraction of computational resources and training data. Watson Assistant demonstrates a higher degree of robustness when the training and test distributions differ.
Multilingual BERT Post-Pretraining Alignment
Oct 23, 2020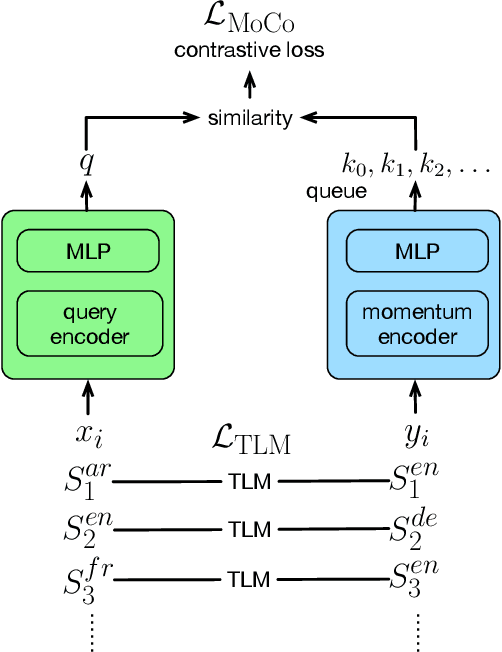
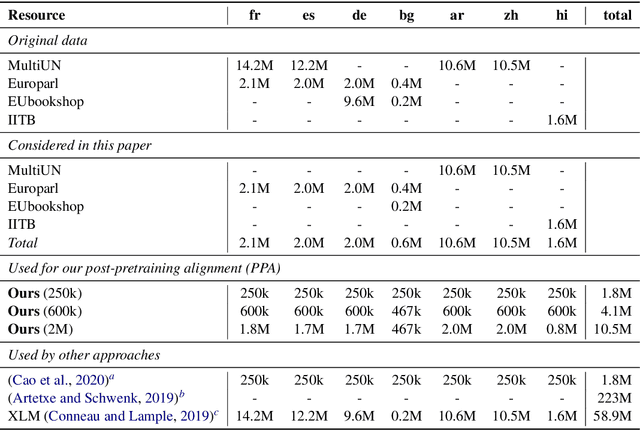
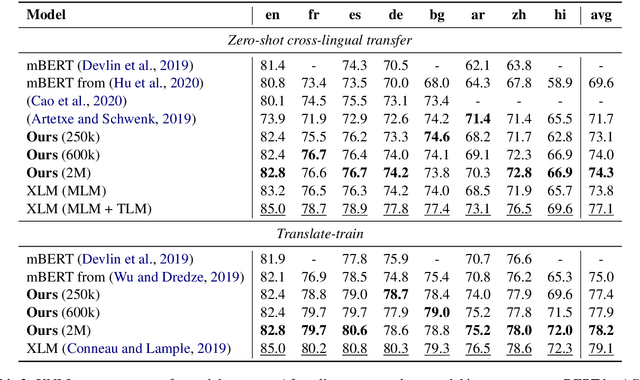
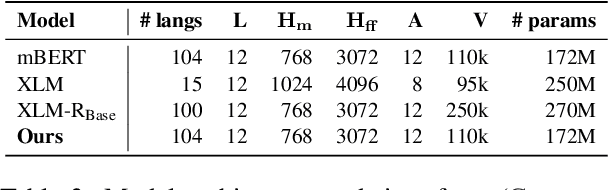
We propose a simple method to align multilingual contextual embeddings as a post-pretraining step for improved zero-shot cross-lingual transferability of the pretrained models. Using parallel data, our method aligns embeddings on the word level through the recently proposed Translation Language Modeling objective as well as on the sentence level via contrastive learning and random input shuffling. We also perform code-switching with English when finetuning on downstream tasks. On XNLI, our best model (initialized from mBERT) improves over mBERT by 4.7% in the zero-shot setting and achieves comparable result to XLM for translate-train while using less than 18% of the same parallel data and 31% less model parameters. On MLQA, our model outperforms XLM-R_Base that has 57% more parameters than ours.
Iterative Data Programming for Expanding Text Classification Corpora
Feb 04, 2020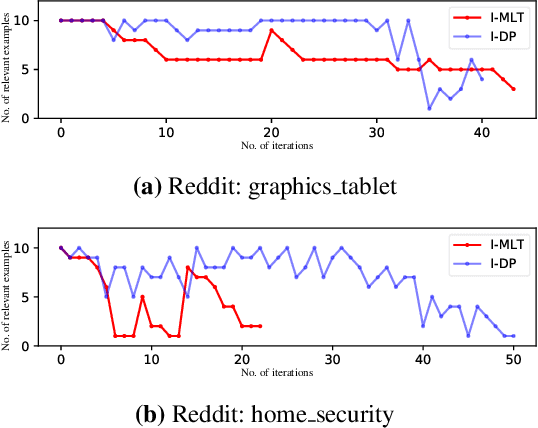
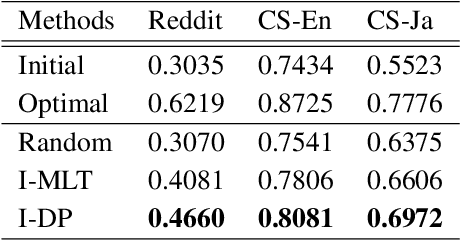
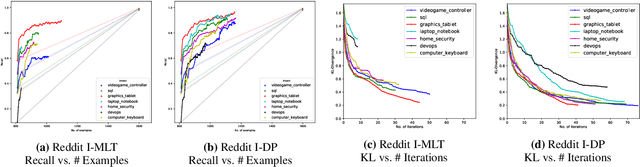
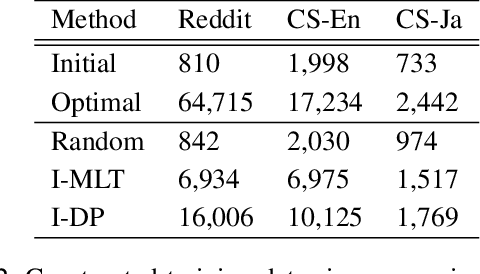
Real-world text classification tasks often require many labeled training examples that are expensive to obtain. Recent advancements in machine teaching, specifically the data programming paradigm, facilitate the creation of training data sets quickly via a general framework for building weak models, also known as labeling functions, and denoising them through ensemble learning techniques. We present a fast, simple data programming method for augmenting text data sets by generating neighborhood-based weak models with minimal supervision. Furthermore, our method employs an iterative procedure to identify sparsely distributed examples from large volumes of unlabeled data. The iterative data programming techniques improve newer weak models as more labeled data is confirmed with human-in-loop. We show empirical results on sentence classification tasks, including those from a task of improving intent recognition in conversational agents.
Rewarding Smatch: Transition-Based AMR Parsing with Reinforcement Learning
May 31, 2019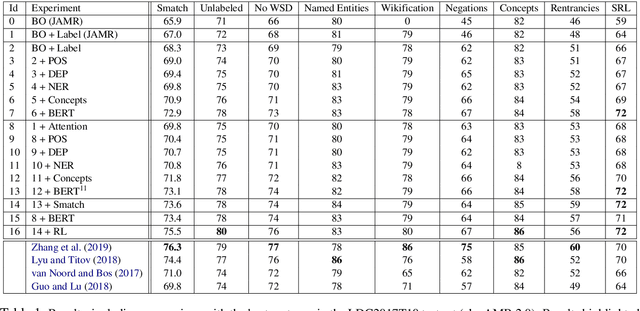
Our work involves enriching the Stack-LSTM transition-based AMR parser (Ballesteros and Al-Onaizan, 2017) by augmenting training with Policy Learning and rewarding the Smatch score of sampled graphs. In addition, we also combined several AMR-to-text alignments with an attention mechanism and we supplemented the parser with pre-processed concept identification, named entities and contextualized embeddings. We achieve a highly competitive performance that is comparable to the best published results. We show an in-depth study ablating each of the new components of the parser
Bootstrapping Conversational Agents With Weak Supervision
Dec 14, 2018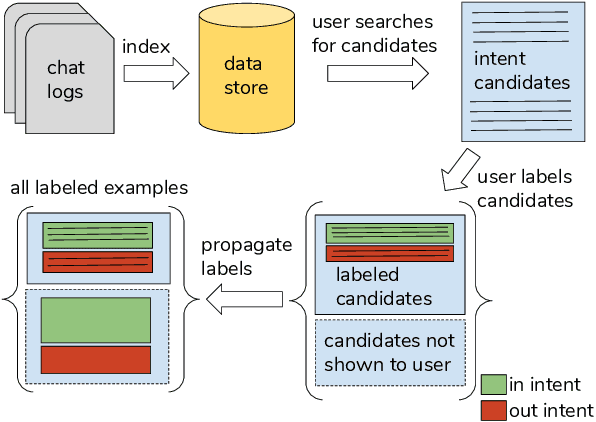

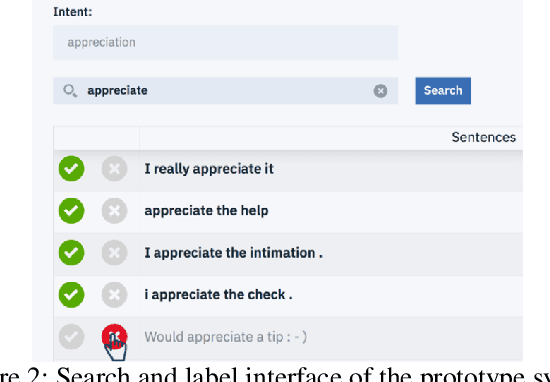
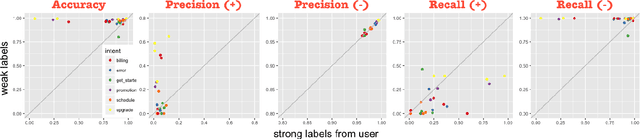
Many conversational agents in the market today follow a standard bot development framework which requires training intent classifiers to recognize user input. The need to create a proper set of training examples is often the bottleneck in the development process. In many occasions agent developers have access to historical chat logs that can provide a good quantity as well as coverage of training examples. However, the cost of labeling them with tens to hundreds of intents often prohibits taking full advantage of these chat logs. In this paper, we present a framework called \textit{search, label, and propagate} (SLP) for bootstrapping intents from existing chat logs using weak supervision. The framework reduces hours to days of labeling effort down to minutes of work by using a search engine to find examples, then relies on a data programming approach to automatically expand the labels. We report on a user study that shows positive user feedback for this new approach to build conversational agents, and demonstrates the effectiveness of using data programming for auto-labeling. While the system is developed for training conversational agents, the framework has broader application in significantly reducing labeling effort for training text classifiers.