 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStabilizing PDE--ML Coupled System
Jun 24, 2025A long-standing obstacle in the use of machine-learnt surrogates with larger PDE systems is the onset of instabilities when solved numerically. Efforts towards ameliorating these have mostly concentrated on improving the accuracy of the surrogates or imbuing them with additional structure, and have garnered limited success. In this article, we study a prototype problem and draw insights that can help with more complex systems. In particular, we focus on a viscous Burgers'-ML system and, after identifying the cause of the instabilities, prescribe strategies to stabilize the coupled system. To improve the accuracy of the stabilized system, we next explore methods based on the Mori--Zwanzig formalism.
Evaluating Robustness of Dialogue Summarization Models in the Presence of Naturally Occurring Variations
Nov 15, 2023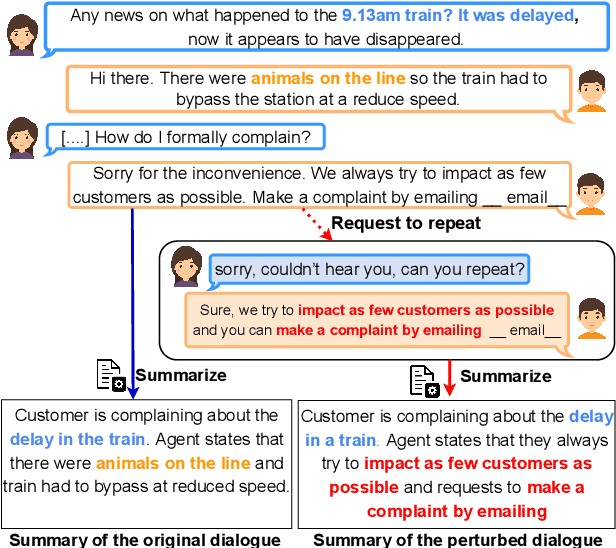
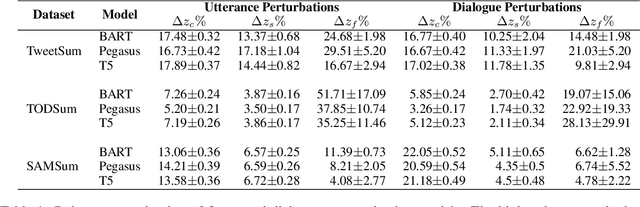
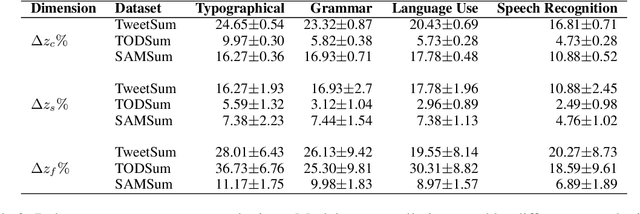
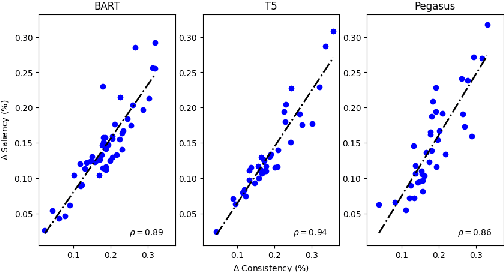
Dialogue summarization task involves summarizing long conversations while preserving the most salient information. Real-life dialogues often involve naturally occurring variations (e.g., repetitions, hesitations) and existing dialogue summarization models suffer from performance drop on such conversations. In this study, we systematically investigate the impact of such variations on state-of-the-art dialogue summarization models using publicly available datasets. To simulate real-life variations, we introduce two types of perturbations: utterance-level perturbations that modify individual utterances with errors and language variations, and dialogue-level perturbations that add non-informative exchanges (e.g., repetitions, greetings). We conduct our analysis along three dimensions of robustness: consistency, saliency, and faithfulness, which capture different aspects of the summarization model's performance. We find that both fine-tuned and instruction-tuned models are affected by input variations, with the latter being more susceptible, particularly to dialogue-level perturbations. We also validate our findings via human evaluation. Finally, we investigate if the robustness of fine-tuned models can be improved by training them with a fraction of perturbed data and observe that this approach is insufficient to address robustness challenges with current models and thus warrants a more thorough investigation to identify better solutions. Overall, our work highlights robustness challenges in dialogue summarization and provides insights for future research.
How Can Context Help? Exploring Joint Retrieval of Passage and Personalized Context
Aug 26, 2023



The integration of external personalized context information into document-grounded conversational systems has significant potential business value, but has not been well-studied. Motivated by the concept of personalized context-aware document-grounded conversational systems, we introduce the task of context-aware passage retrieval. We also construct a dataset specifically curated for this purpose. We describe multiple baseline systems to address this task, and propose a novel approach, Personalized Context-Aware Search (PCAS), that effectively harnesses contextual information during passage retrieval. Experimental evaluations conducted on multiple popular dense retrieval systems demonstrate that our proposed approach not only outperforms the baselines in retrieving the most relevant passage but also excels at identifying the pertinent context among all the available contexts. We envision that our contributions will serve as a catalyst for inspiring future research endeavors in this promising direction.
Semi-Structured Object Sequence Encoders
Jan 10, 2023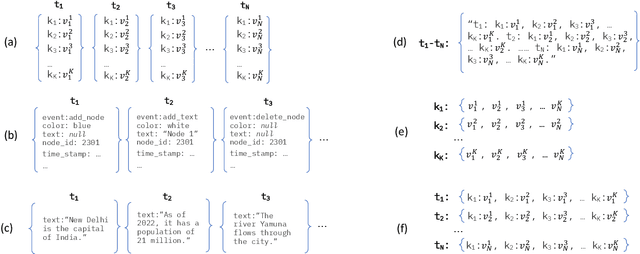

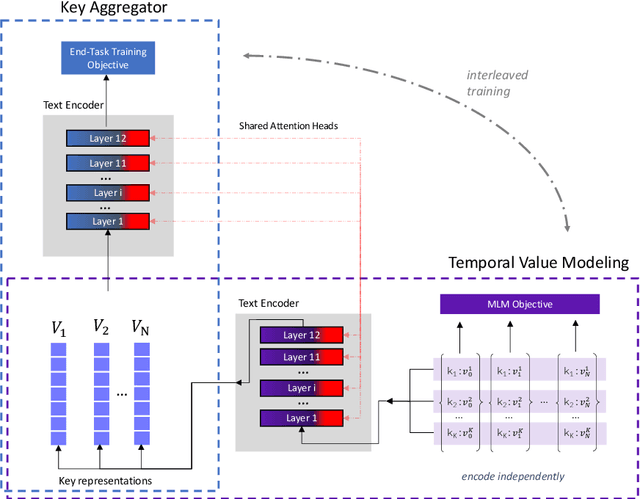
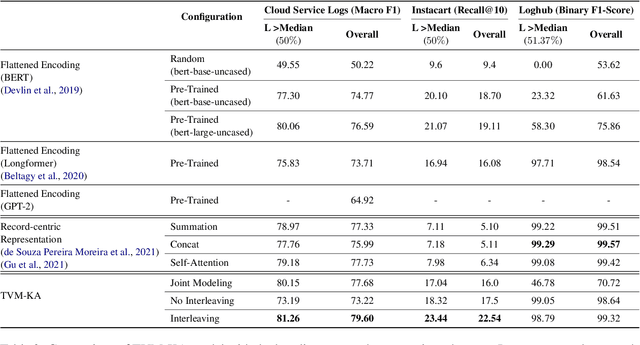
In this paper we explore the task of modeling (semi) structured object sequences; in particular we focus our attention on the problem of developing a structure-aware input representation for such sequences. In such sequences, we assume that each structured object is represented by a set of key-value pairs which encode the attributes of the structured object. Given a universe of keys, a sequence of structured objects can then be viewed as an evolution of the values for each key, over time. We encode and construct a sequential representation using the values for a particular key (Temporal Value Modeling - TVM) and then self-attend over the set of key-conditioned value sequences to a create a representation of the structured object sequence (Key Aggregation - KA). We pre-train and fine-tune the two components independently and present an innovative training schedule that interleaves the training of both modules with shared attention heads. We find that this iterative two part-training results in better performance than a unified network with hierarchical encoding as well as over, other methods that use a {\em record-view} representation of the sequence \cite{de2021transformers4rec} or a simple {\em flattened} representation of the sequence. We conduct experiments using real-world data to demonstrate the advantage of interleaving TVM-KA on multiple tasks and detailed ablation studies motivating our modeling choices. We find that our approach performs better than flattening sequence objects and also allows us to operate on significantly larger sequences than existing methods.
Fast and Light-Weight Answer Text Retrieval in Dialogue Systems
May 31, 2022
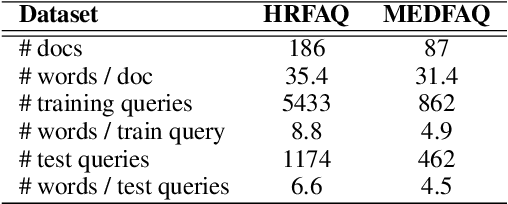
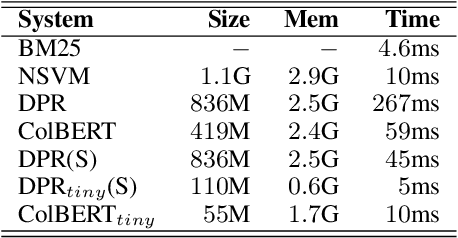
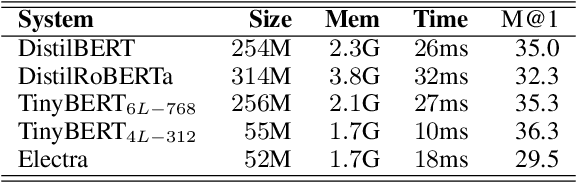
Dialogue systems can benefit from being able to search through a corpus of text to find information relevant to user requests, especially when encountering a request for which no manually curated response is available. The state-of-the-art technology for neural dense retrieval or re-ranking involves deep learning models with hundreds of millions of parameters. However, it is difficult and expensive to get such models to operate at an industrial scale, especially for cloud services that often need to support a big number of individually customized dialogue systems, each with its own text corpus. We report our work on enabling advanced neural dense retrieval systems to operate effectively at scale on relatively inexpensive hardware. We compare with leading alternative industrial solutions and show that we can provide a solution that is effective, fast, and cost-efficient.
Learning as Conversation: Dialogue Systems Reinforced for Information Acquisition
May 29, 2022
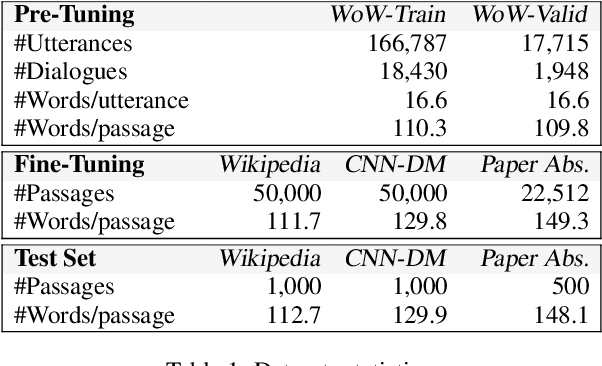
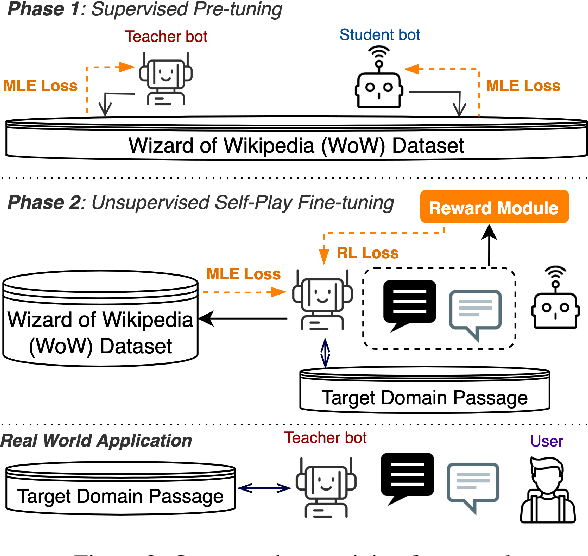

We propose novel AI-empowered chat bots for learning as conversation where a user does not read a passage but gains information and knowledge through conversation with a teacher bot. Our information-acquisition-oriented dialogue system employs a novel adaptation of reinforced self-play so that the system can be transferred to various domains without in-domain dialogue data, and can carry out conversations both informative and attentive to users. Our extensive subjective and objective evaluations on three large public data corpora demonstrate the effectiveness of our system to deliver knowledge-intensive and attentive conversations and help end users substantially gain knowledge without reading passages. Our code and datasets are publicly available for follow-up research.
MultiDoc2Dial: Modeling Dialogues Grounded in Multiple Documents
Sep 26, 2021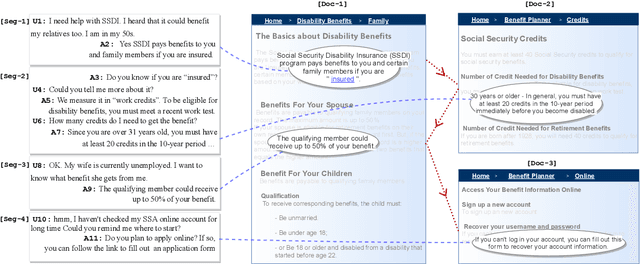
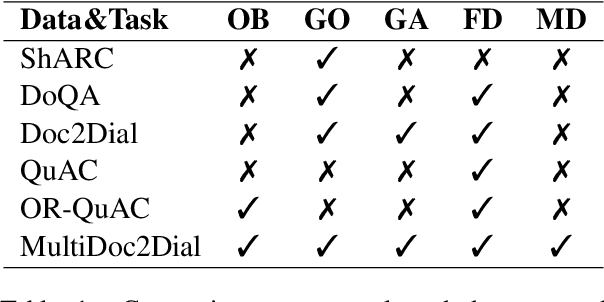
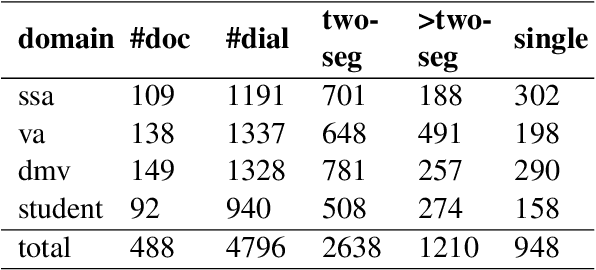
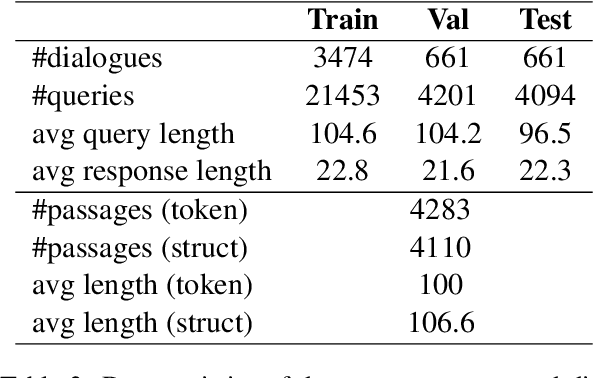
We propose MultiDoc2Dial, a new task and dataset on modeling goal-oriented dialogues grounded in multiple documents. Most previous works treat document-grounded dialogue modeling as a machine reading comprehension task based on a single given document or passage. In this work, we aim to address more realistic scenarios where a goal-oriented information-seeking conversation involves multiple topics, and hence is grounded on different documents. To facilitate such a task, we introduce a new dataset that contains dialogues grounded in multiple documents from four different domains. We also explore modeling the dialogue-based and document-based context in the dataset. We present strong baseline approaches and various experimental results, aiming to support further research efforts on such a task.
Explaining Neural Network Predictions on Sentence Pairs via Learning Word-Group Masks
Apr 13, 2021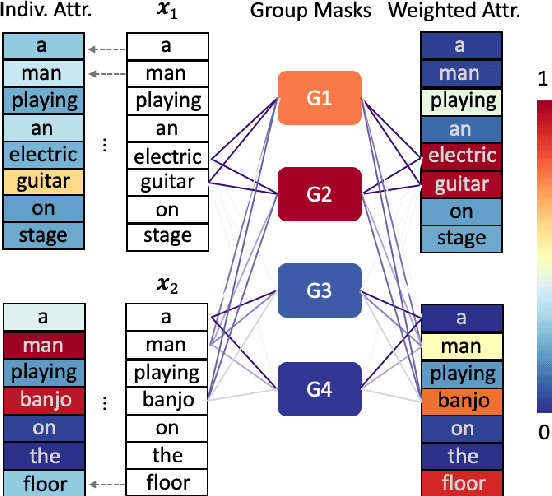
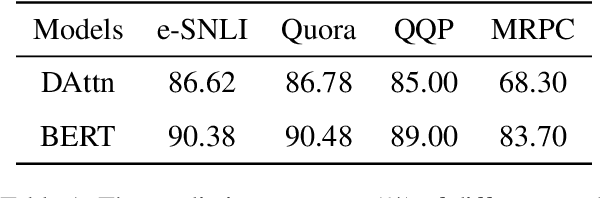
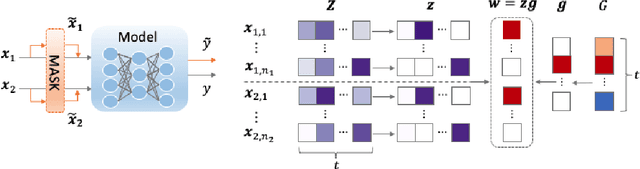
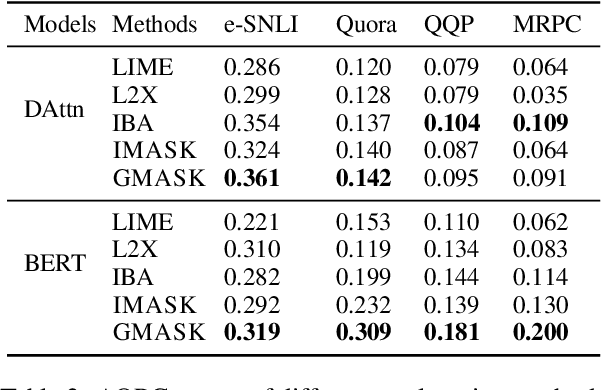
Explaining neural network models is important for increasing their trustworthiness in real-world applications. Most existing methods generate post-hoc explanations for neural network models by identifying individual feature attributions or detecting interactions between adjacent features. However, for models with text pairs as inputs (e.g., paraphrase identification), existing methods are not sufficient to capture feature interactions between two texts and their simple extension of computing all word-pair interactions between two texts is computationally inefficient. In this work, we propose the Group Mask (GMASK) method to implicitly detect word correlations by grouping correlated words from the input text pair together and measure their contribution to the corresponding NLP tasks as a whole. The proposed method is evaluated with two different model architectures (decomposable attention model and BERT) across four datasets, including natural language inference and paraphrase identification tasks. Experiments show the effectiveness of GMASK in providing faithful explanations to these models.
doc2dial: A Goal-Oriented Document-Grounded Dialogue Dataset
Nov 18, 2020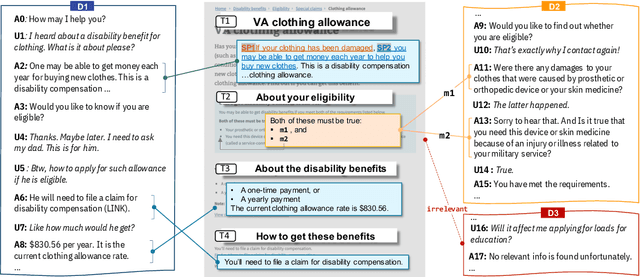
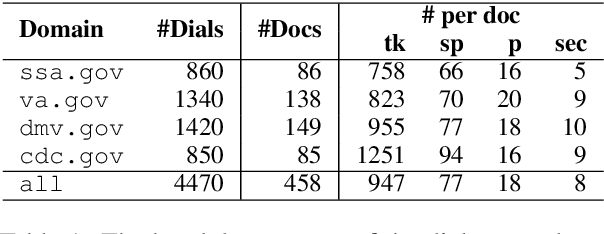
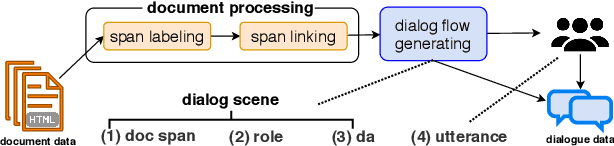
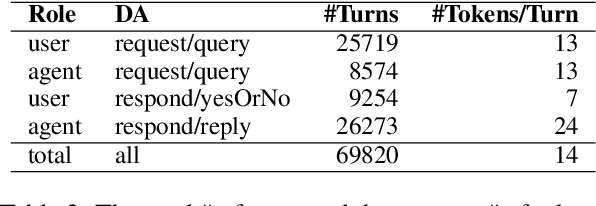
We introduce doc2dial, a new dataset of goal-oriented dialogues that are grounded in the associated documents. Inspired by how the authors compose documents for guiding end users, we first construct dialogue flows based on the content elements that corresponds to higher-level relations across text sections as well as lower-level relations between discourse units within a section. Then we present these dialogue flows to crowd contributors to create conversational utterances. The dataset includes about 4800 annotated conversations with an average of 14 turns that are grounded in over 480 documents from four domains. Compared to the prior document-grounded dialogue datasets, this dataset covers a variety of dialogue scenes in information-seeking conversations. For evaluating the versatility of the dataset, we introduce multiple dialogue modeling tasks and present baseline approaches.
Multi-task Learning with Multi-head Attention for Multi-choice Reading Comprehension
Feb 26, 2020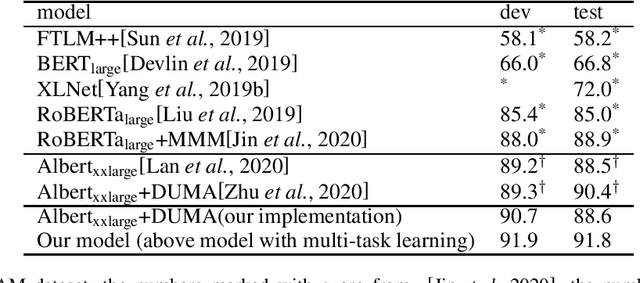
Multiple-choice Machine Reading Comprehension (MRC) is an important and challenging Natural Language Understanding (NLU) task, in which a machine must choose the answer to a question from a set of choices, with the question placed in context of text passages or dialog. In the last a couple of years the NLU field has been revolutionized with the advent of models based on the Transformer architecture, which are pretrained on massive amounts of unsupervised data and then fine-tuned for various supervised learning NLU tasks. Transformer models have come to dominate a wide variety of leader-boards in the NLU field; in the area of MRC, the current state-of-the-art model on the DREAM dataset (see[Sunet al., 2019]) fine tunes Albert, a large pretrained Transformer-based model, and addition-ally combines it with an extra layer of multi-head attention between context and question-answer[Zhuet al., 2020].The purpose of this note is to document a new state-of-the-art result in the DREAM task, which is accomplished by, additionally, performing multi-task learning on two MRC multi-choice reading comprehension tasks (RACE and DREAM).