 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTraining with Pseudo-Code for Instruction Following
May 23, 2025Despite the rapid progress in the capabilities of Large Language Models (LLMs), they continue to have difficulty following relatively simple, unambiguous instructions, especially when compositions are involved. In this paper, we take inspiration from recent work that suggests that models may follow instructions better when they are expressed in pseudo-code. However, writing pseudo-code programs can be tedious and using few-shot demonstrations to craft code representations for use in inference can be unnatural for non-expert users of LLMs. To overcome these limitations, we propose fine-tuning LLMs with instruction-tuning data that additionally includes instructions re-expressed in pseudo-code along with the final response. We evaluate models trained using our method on $11$ publicly available benchmarks comprising of tasks related to instruction-following, mathematics, and common-sense reasoning. We conduct rigorous experiments with $5$ different models and find that not only do models follow instructions better when trained with pseudo-code, they also retain their capabilities on the other tasks related to mathematical and common sense reasoning. Specifically, we observe a relative gain of $3$--$19$% on instruction-following benchmark, and an average gain of upto 14% across all tasks.
Prompting with Pseudo-Code Instructions
May 22, 2023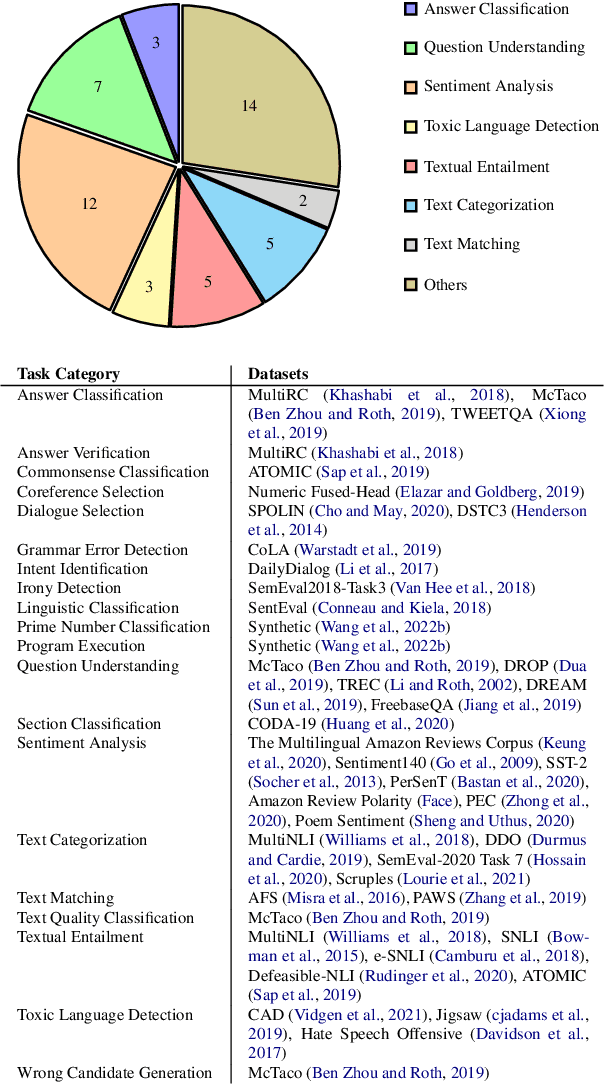
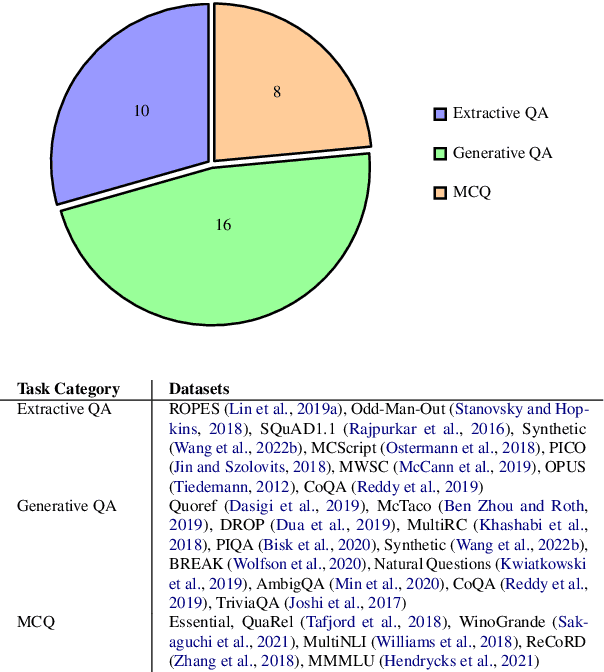
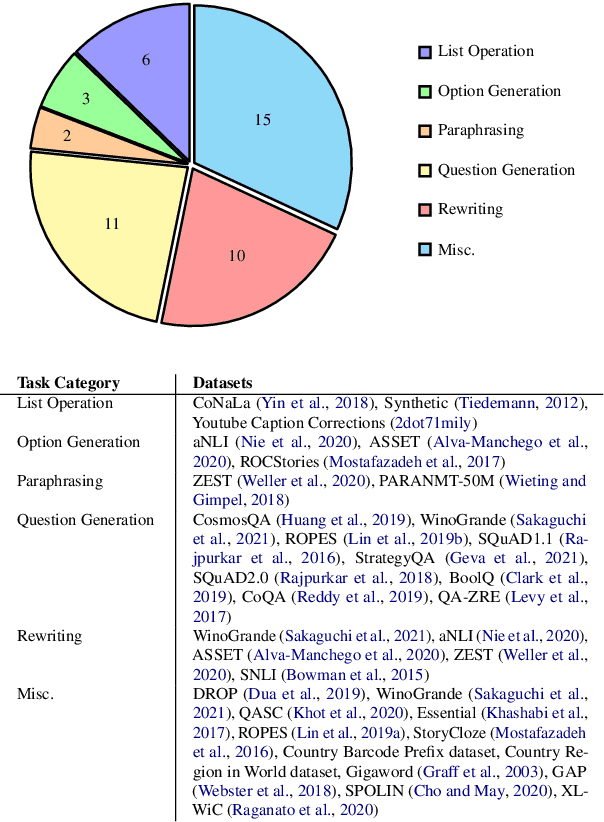
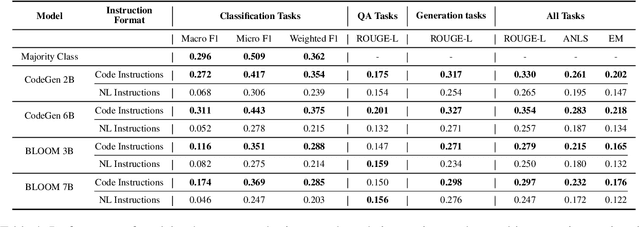
Prompting with natural language instructions has recently emerged as a popular method of harnessing the capabilities of large language models. Given the inherent ambiguity present in natural language, it is intuitive to consider the possible advantages of prompting with less ambiguous prompt styles, such as the use of pseudo-code. In this paper we explore if prompting via pseudo-code instructions helps improve the performance of pre-trained language models. We manually create a dataset of pseudo-code prompts for 132 different tasks spanning classification, QA and generative language tasks, sourced from the Super-NaturalInstructions dataset. Using these prompts along with their counterparts in natural language, we study their performance on two LLM families - BLOOM and CodeGen. Our experiments show that using pseudo-code instructions leads to better results, with an average increase (absolute) of 7-16 points in F1 scores for classification tasks and an improvement (relative) of 12-38% in aggregate ROUGE-L scores across all tasks. We include detailed ablation studies which indicate that code comments, docstrings, and the structural clues encoded in pseudo-code all contribute towards the improvement in performance. To the best of our knowledge our work is the first to demonstrate how pseudo-code prompts can be helpful in improving the performance of pre-trained LMs.
PrimeQA: The Prime Repository for State-of-the-Art Multilingual Question Answering Research and Development
Jan 25, 2023



The field of Question Answering (QA) has made remarkable progress in recent years, thanks to the advent of large pre-trained language models, newer realistic benchmark datasets with leaderboards, and novel algorithms for key components such as retrievers and readers. In this paper, we introduce PRIMEQA: a one-stop and open-source QA repository with an aim to democratize QA re-search and facilitate easy replication of state-of-the-art (SOTA) QA methods. PRIMEQA supports core QA functionalities like retrieval and reading comprehension as well as auxiliary capabilities such as question generation.It has been designed as an end-to-end toolkit for various use cases: building front-end applications, replicating SOTA methods on pub-lic benchmarks, and expanding pre-existing methods. PRIMEQA is available at : https://github.com/primeqa.
Semi-Structured Object Sequence Encoders
Jan 10, 2023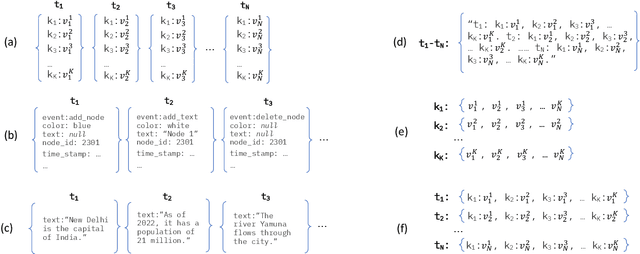

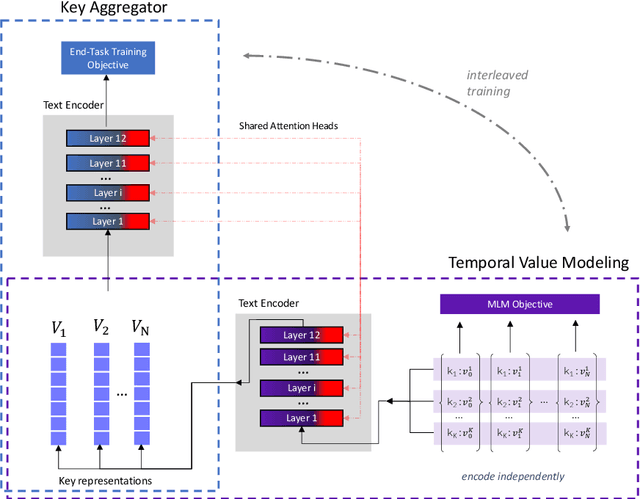
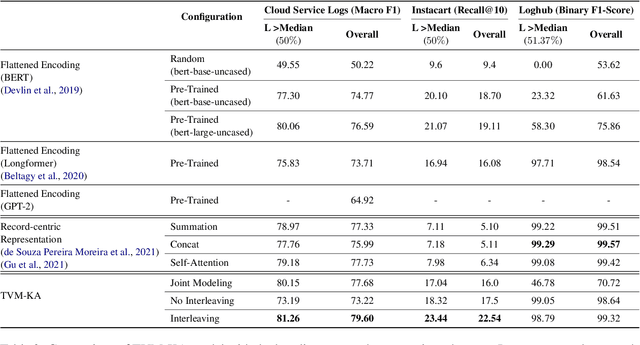
In this paper we explore the task of modeling (semi) structured object sequences; in particular we focus our attention on the problem of developing a structure-aware input representation for such sequences. In such sequences, we assume that each structured object is represented by a set of key-value pairs which encode the attributes of the structured object. Given a universe of keys, a sequence of structured objects can then be viewed as an evolution of the values for each key, over time. We encode and construct a sequential representation using the values for a particular key (Temporal Value Modeling - TVM) and then self-attend over the set of key-conditioned value sequences to a create a representation of the structured object sequence (Key Aggregation - KA). We pre-train and fine-tune the two components independently and present an innovative training schedule that interleaves the training of both modules with shared attention heads. We find that this iterative two part-training results in better performance than a unified network with hierarchical encoding as well as over, other methods that use a {\em record-view} representation of the sequence \cite{de2021transformers4rec} or a simple {\em flattened} representation of the sequence. We conduct experiments using real-world data to demonstrate the advantage of interleaving TVM-KA on multiple tasks and detailed ablation studies motivating our modeling choices. We find that our approach performs better than flattening sequence objects and also allows us to operate on significantly larger sequences than existing methods.