 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStarCoder: may the source be with you!
May 09, 2023



The BigCode community, an open-scientific collaboration working on the responsible development of Large Language Models for Code (Code LLMs), introduces StarCoder and StarCoderBase: 15.5B parameter models with 8K context length, infilling capabilities and fast large-batch inference enabled by multi-query attention. StarCoderBase is trained on 1 trillion tokens sourced from The Stack, a large collection of permissively licensed GitHub repositories with inspection tools and an opt-out process. We fine-tuned StarCoderBase on 35B Python tokens, resulting in the creation of StarCoder. We perform the most comprehensive evaluation of Code LLMs to date and show that StarCoderBase outperforms every open Code LLM that supports multiple programming languages and matches or outperforms the OpenAI code-cushman-001 model. Furthermore, StarCoder outperforms every model that is fine-tuned on Python, can be prompted to achieve 40\% pass@1 on HumanEval, and still retains its performance on other programming languages. We take several important steps towards a safe open-access model release, including an improved PII redaction pipeline and a novel attribution tracing tool, and make the StarCoder models publicly available under a more commercially viable version of the Open Responsible AI Model license.
Semi-Structured Object Sequence Encoders
Jan 10, 2023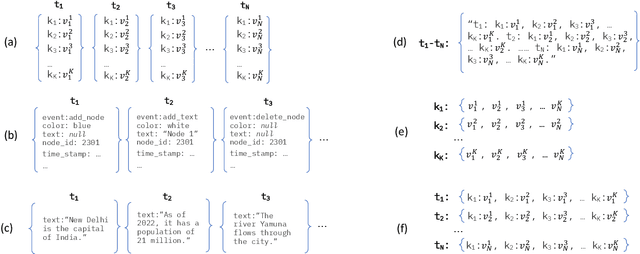

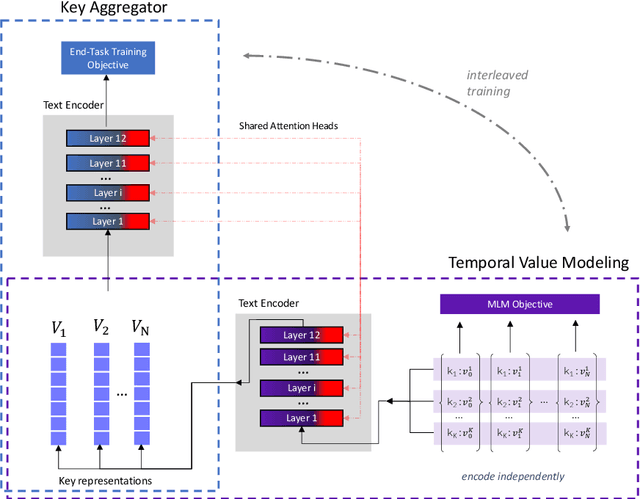
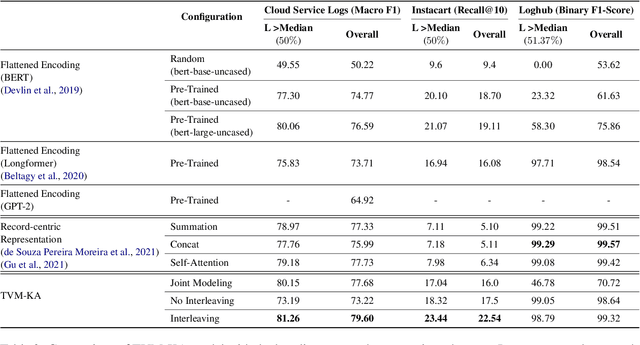
In this paper we explore the task of modeling (semi) structured object sequences; in particular we focus our attention on the problem of developing a structure-aware input representation for such sequences. In such sequences, we assume that each structured object is represented by a set of key-value pairs which encode the attributes of the structured object. Given a universe of keys, a sequence of structured objects can then be viewed as an evolution of the values for each key, over time. We encode and construct a sequential representation using the values for a particular key (Temporal Value Modeling - TVM) and then self-attend over the set of key-conditioned value sequences to a create a representation of the structured object sequence (Key Aggregation - KA). We pre-train and fine-tune the two components independently and present an innovative training schedule that interleaves the training of both modules with shared attention heads. We find that this iterative two part-training results in better performance than a unified network with hierarchical encoding as well as over, other methods that use a {\em record-view} representation of the sequence \cite{de2021transformers4rec} or a simple {\em flattened} representation of the sequence. We conduct experiments using real-world data to demonstrate the advantage of interleaving TVM-KA on multiple tasks and detailed ablation studies motivating our modeling choices. We find that our approach performs better than flattening sequence objects and also allows us to operate on significantly larger sequences than existing methods.
Fast and Light-Weight Answer Text Retrieval in Dialogue Systems
May 31, 2022
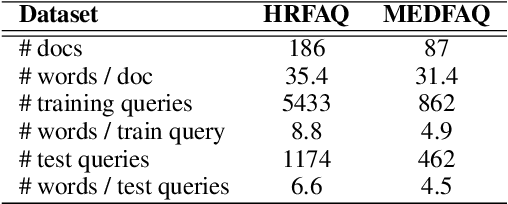
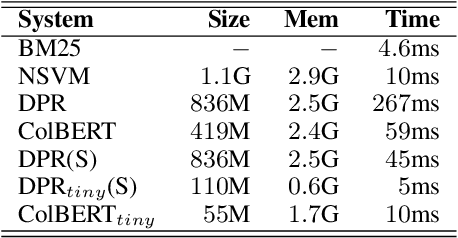
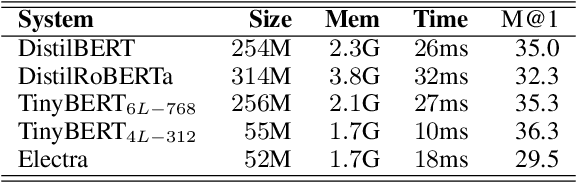
Dialogue systems can benefit from being able to search through a corpus of text to find information relevant to user requests, especially when encountering a request for which no manually curated response is available. The state-of-the-art technology for neural dense retrieval or re-ranking involves deep learning models with hundreds of millions of parameters. However, it is difficult and expensive to get such models to operate at an industrial scale, especially for cloud services that often need to support a big number of individually customized dialogue systems, each with its own text corpus. We report our work on enabling advanced neural dense retrieval systems to operate effectively at scale on relatively inexpensive hardware. We compare with leading alternative industrial solutions and show that we can provide a solution that is effective, fast, and cost-efficient.
MultiDoc2Dial: Modeling Dialogues Grounded in Multiple Documents
Sep 26, 2021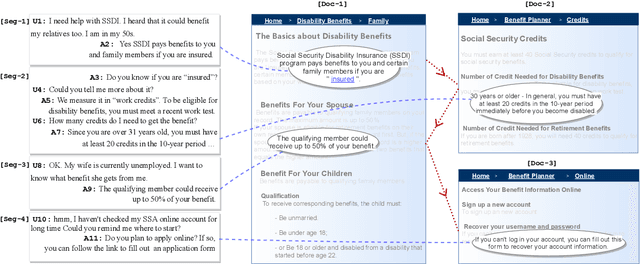
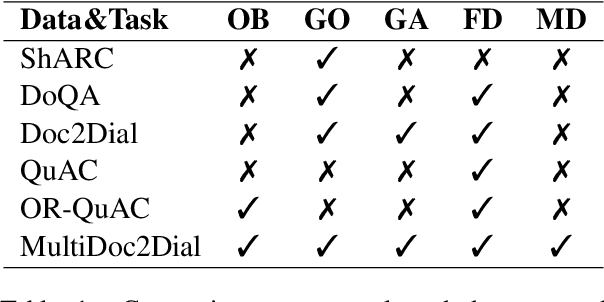
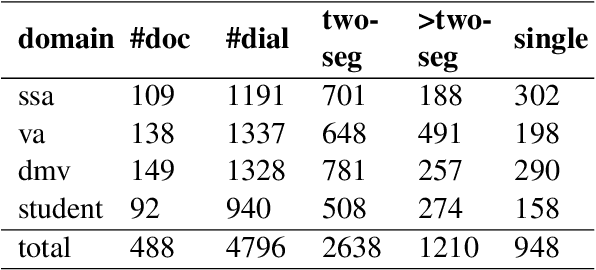
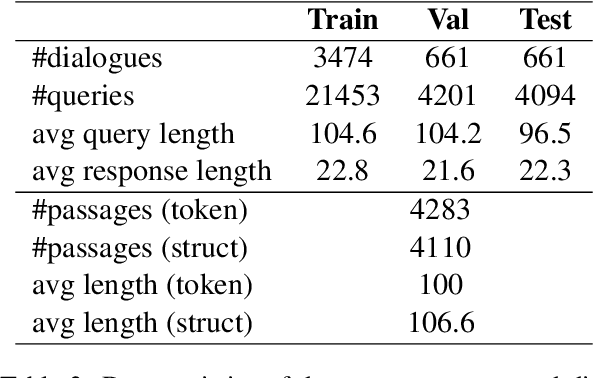
We propose MultiDoc2Dial, a new task and dataset on modeling goal-oriented dialogues grounded in multiple documents. Most previous works treat document-grounded dialogue modeling as a machine reading comprehension task based on a single given document or passage. In this work, we aim to address more realistic scenarios where a goal-oriented information-seeking conversation involves multiple topics, and hence is grounded on different documents. To facilitate such a task, we introduce a new dataset that contains dialogues grounded in multiple documents from four different domains. We also explore modeling the dialogue-based and document-based context in the dataset. We present strong baseline approaches and various experimental results, aiming to support further research efforts on such a task.
doc2dial: A Goal-Oriented Document-Grounded Dialogue Dataset
Nov 18, 2020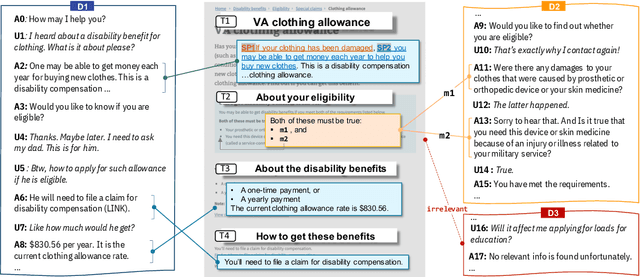
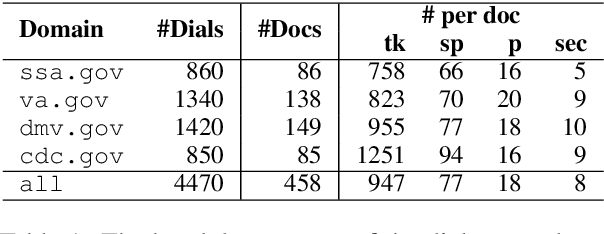
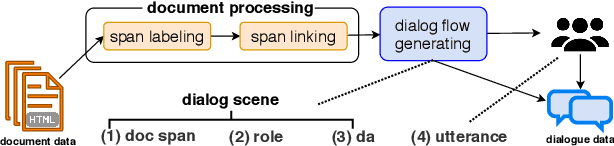
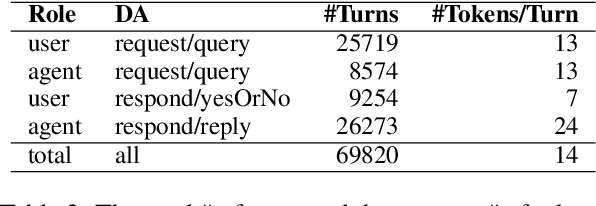
We introduce doc2dial, a new dataset of goal-oriented dialogues that are grounded in the associated documents. Inspired by how the authors compose documents for guiding end users, we first construct dialogue flows based on the content elements that corresponds to higher-level relations across text sections as well as lower-level relations between discourse units within a section. Then we present these dialogue flows to crowd contributors to create conversational utterances. The dataset includes about 4800 annotated conversations with an average of 14 turns that are grounded in over 480 documents from four domains. Compared to the prior document-grounded dialogue datasets, this dataset covers a variety of dialogue scenes in information-seeking conversations. For evaluating the versatility of the dataset, we introduce multiple dialogue modeling tasks and present baseline approaches.
Infusing Knowledge into the Textual Entailment Task Using Graph Convolutional Networks
Nov 22, 2019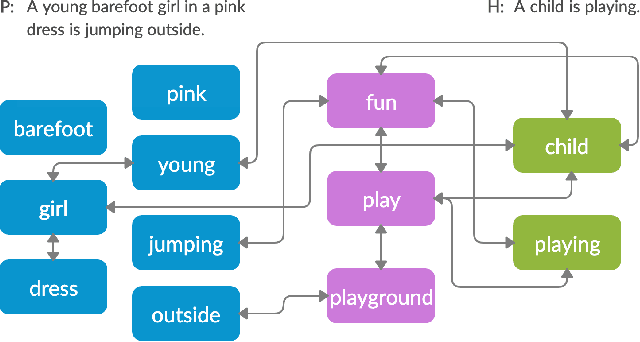

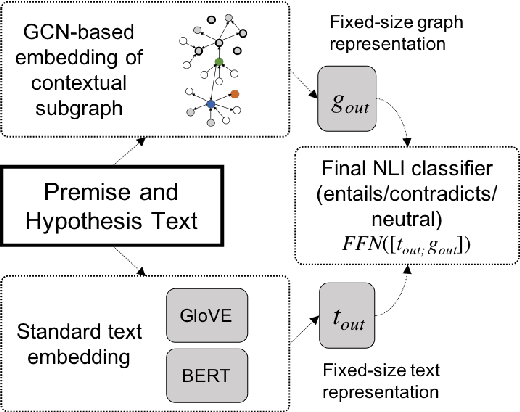
Textual entailment is a fundamental task in natural language processing. Most approaches for solving the problem use only the textual content present in training data. A few approaches have shown that information from external knowledge sources like knowledge graphs (KGs) can add value, in addition to the textual content, by providing background knowledge that may be critical for a task. However, the proposed models do not fully exploit the information in the usually large and noisy KGs, and it is not clear how it can be effectively encoded to be useful for entailment. We present an approach that complements text-based entailment models with information from KGs by (1) using Personalized PageR- ank to generate contextual subgraphs with reduced noise and (2) encoding these subgraphs using graph convolutional networks to capture KG structure. Our technique extends the capability of text models exploiting structural and semantic information found in KGs. We evaluate our approach on multiple textual entailment datasets and show that the use of external knowledge helps improve prediction accuracy. This is particularly evident in the challenging BreakingNLI dataset, where we see an absolute improvement of 5-20% over multiple text-based entailment models.
Knowledge-incorporating ESIM models for Response Selection in Retrieval-based Dialog Systems
Jul 11, 2019
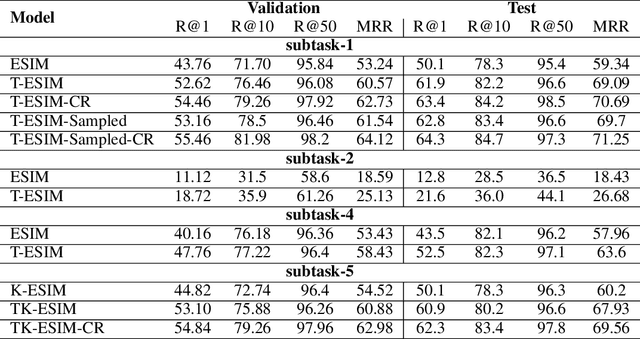

Goal-oriented dialog systems, which can be trained end-to-end without manually encoding domain-specific features, show tremendous promise in the customer support use-case e.g. flight booking, hotel reservation, technical support, student advising etc. These dialog systems must learn to interact with external domain knowledge to achieve the desired goal e.g. recommending courses to a student, booking a table at a restaurant etc. This paper presents extended Enhanced Sequential Inference Model (ESIM) models: a) K-ESIM (Knowledge-ESIM), which incorporates the external domain knowledge and b) T-ESIM (Targeted-ESIM), which leverages information from similar conversations to improve the prediction accuracy. Our proposed models and the baseline ESIM model are evaluated on the Ubuntu and Advising datasets in the Sentence Selection track of the latest Dialog System Technology Challenge (DSTC7), where the goal is to find the correct next utterance, given a partial conversation, from a set of candidates. Our preliminary results suggest that incorporating external knowledge sources and leveraging information from similar dialogs leads to performance improvements for predicting the next utterance.
Analyzing Assumptions in Conversation Disentanglement Research Through the Lens of a New Dataset and Model
Oct 25, 2018
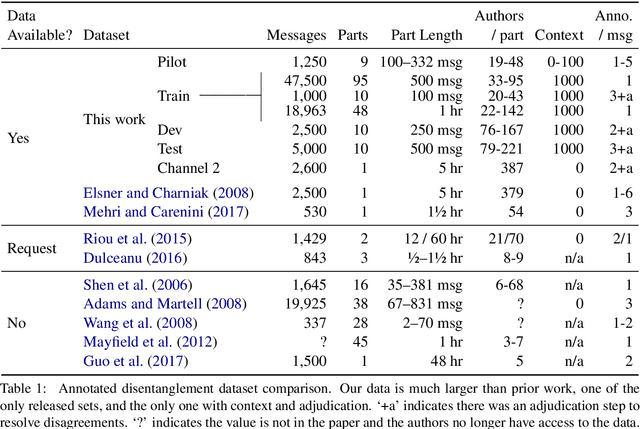

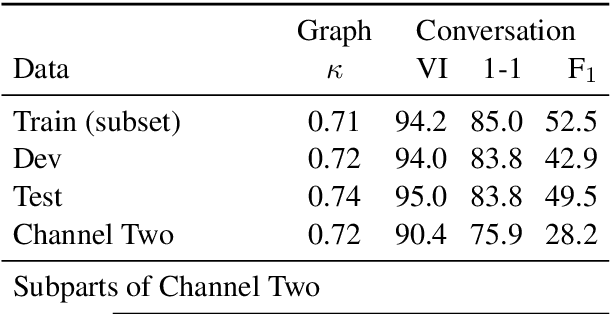
Disentangling conversations mixed together in a single stream of messages is a difficult task with no large annotated datasets. We created a new dataset that is 25 times the size of any previous publicly available resource, has samples of conversation from 152 points in time across a decade, and is annotated with both threads and a within-thread reply-structure graph. We also developed a new neural network model, which extracts conversation threads substantially more accurately than prior work. Using our annotated data and our model we tested assumptions in prior work, revealing major issues in heuristically constructed resources, and identifying how small datasets have biased our understanding of multi-party multi-conversation chat.