 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePrompting with Pseudo-Code Instructions
May 22, 2023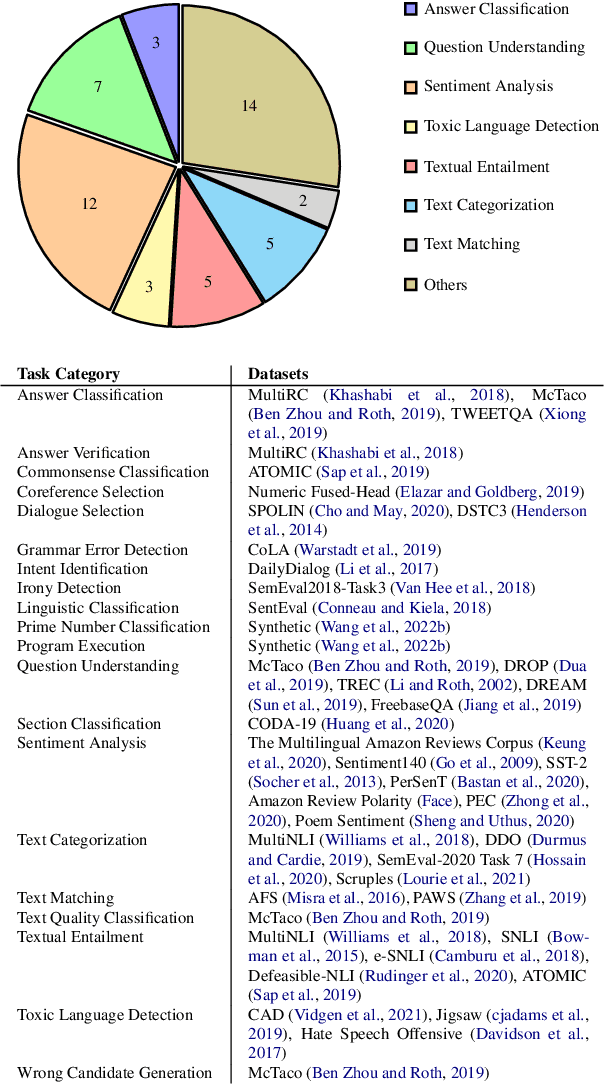
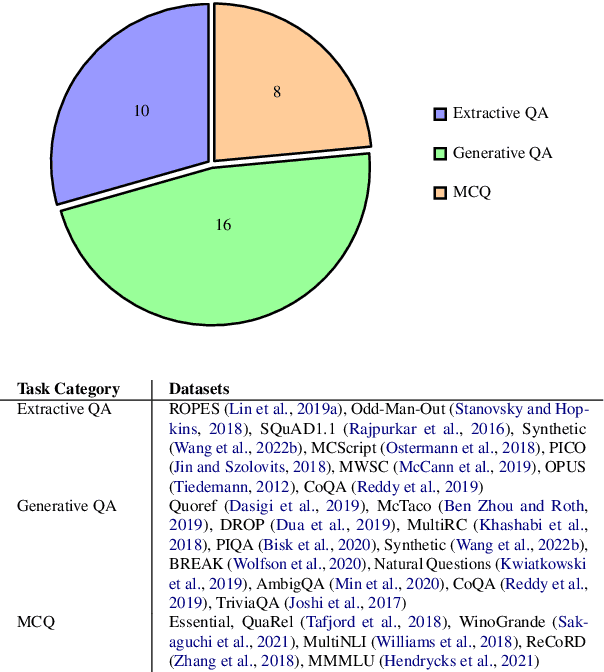
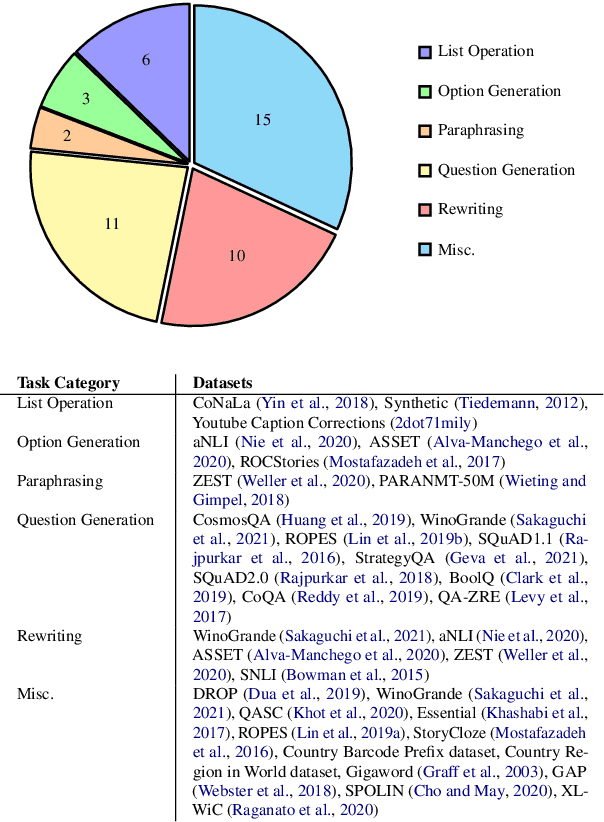
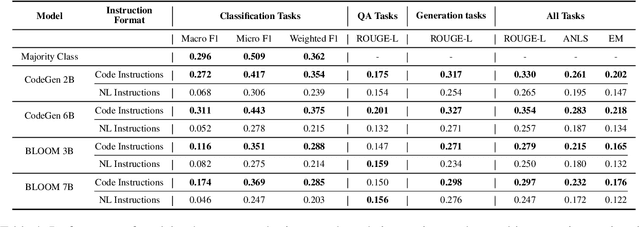
Prompting with natural language instructions has recently emerged as a popular method of harnessing the capabilities of large language models. Given the inherent ambiguity present in natural language, it is intuitive to consider the possible advantages of prompting with less ambiguous prompt styles, such as the use of pseudo-code. In this paper we explore if prompting via pseudo-code instructions helps improve the performance of pre-trained language models. We manually create a dataset of pseudo-code prompts for 132 different tasks spanning classification, QA and generative language tasks, sourced from the Super-NaturalInstructions dataset. Using these prompts along with their counterparts in natural language, we study their performance on two LLM families - BLOOM and CodeGen. Our experiments show that using pseudo-code instructions leads to better results, with an average increase (absolute) of 7-16 points in F1 scores for classification tasks and an improvement (relative) of 12-38% in aggregate ROUGE-L scores across all tasks. We include detailed ablation studies which indicate that code comments, docstrings, and the structural clues encoded in pseudo-code all contribute towards the improvement in performance. To the best of our knowledge our work is the first to demonstrate how pseudo-code prompts can be helpful in improving the performance of pre-trained LMs.
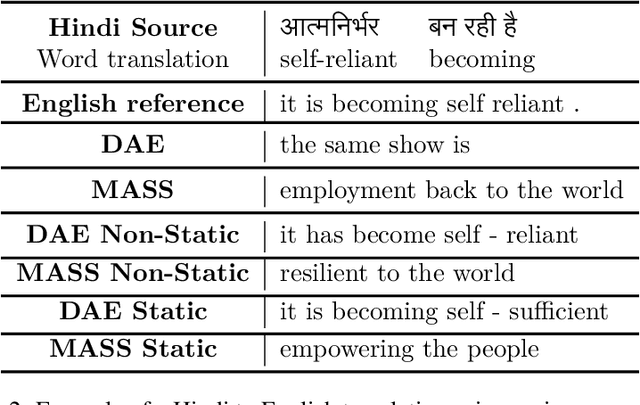
Denoising-based UNMT is more robust to word-order divergence than MASS-based UNMT
Mar 02, 2023



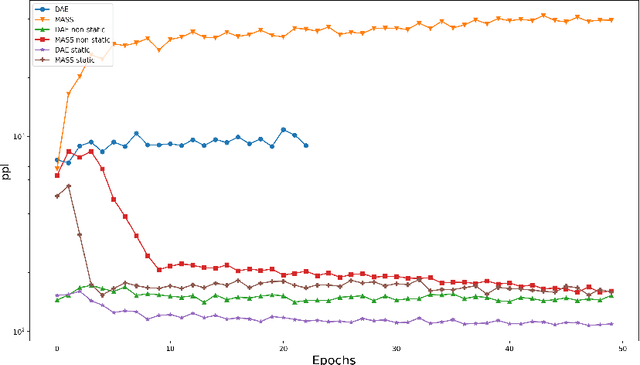
We aim to investigate whether UNMT approaches with self-supervised pre-training are robust to word-order divergence between language pairs. We achieve this by comparing two models pre-trained with the same self-supervised pre-training objective. The first model is trained on language pairs with different word-orders, and the second model is trained on the same language pairs with source language re-ordered to match the word-order of the target language. Ideally, UNMT approaches which are robust to word-order divergence should exhibit no visible performance difference between the two configurations. In this paper, we investigate two such self-supervised pre-training based UNMT approaches, namely Masked Sequence-to-Sequence Pre-Training, (MASS) (which does not have shuffling noise) and Denoising AutoEncoder (DAE), (which has shuffling noise). We experiment with five English$\rightarrow$Indic language pairs, i.e., en-hi, en-bn, en-gu, en-kn, and en-ta) where word-order of the source language is SVO (Subject-Verb-Object), and the word-order of the target languages is SOV (Subject-Object-Verb). We observed that for these language pairs, DAE-based UNMT approach consistently outperforms MASS in terms of translation accuracies. Moreover, bridging the word-order gap using reordering improves the translation accuracy of MASS-based UNMT models, while it cannot improve the translation accuracy of DAE-based UNMT models. This observation indicates that DAE-based UNMT is more robust to word-order divergence than MASS-based UNMT. Word-shuffling noise in DAE approach could be the possible reason for the approach being robust to word-order divergence.
Semi-Structured Object Sequence Encoders
Jan 10, 2023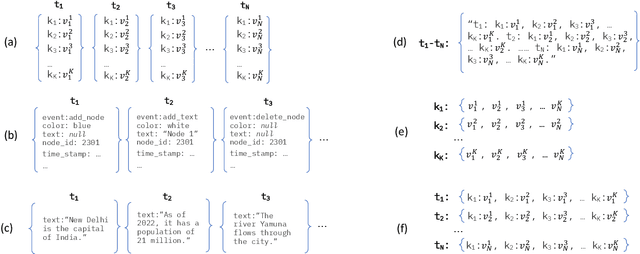

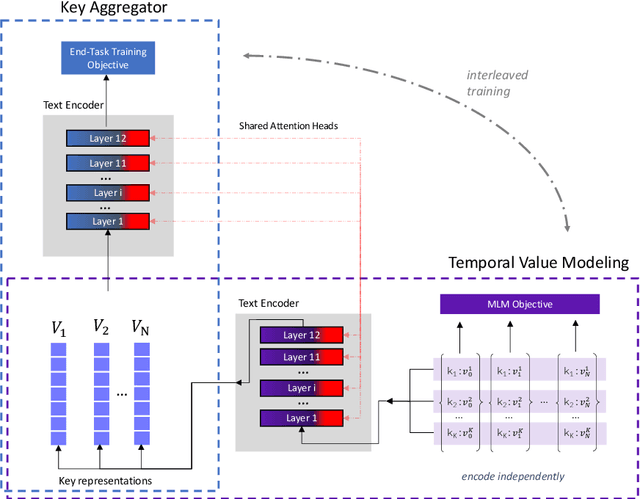
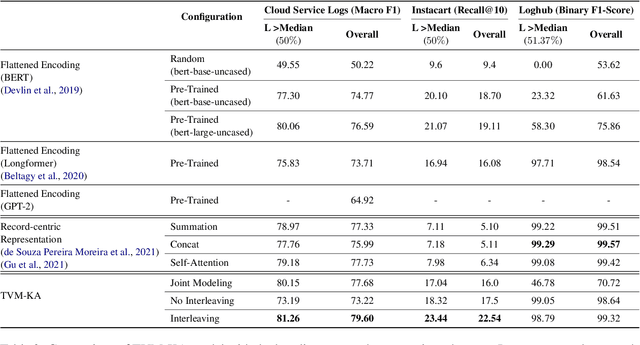
In this paper we explore the task of modeling (semi) structured object sequences; in particular we focus our attention on the problem of developing a structure-aware input representation for such sequences. In such sequences, we assume that each structured object is represented by a set of key-value pairs which encode the attributes of the structured object. Given a universe of keys, a sequence of structured objects can then be viewed as an evolution of the values for each key, over time. We encode and construct a sequential representation using the values for a particular key (Temporal Value Modeling - TVM) and then self-attend over the set of key-conditioned value sequences to a create a representation of the structured object sequence (Key Aggregation - KA). We pre-train and fine-tune the two components independently and present an innovative training schedule that interleaves the training of both modules with shared attention heads. We find that this iterative two part-training results in better performance than a unified network with hierarchical encoding as well as over, other methods that use a {\em record-view} representation of the sequence \cite{de2021transformers4rec} or a simple {\em flattened} representation of the sequence. We conduct experiments using real-world data to demonstrate the advantage of interleaving TVM-KA on multiple tasks and detailed ablation studies motivating our modeling choices. We find that our approach performs better than flattening sequence objects and also allows us to operate on significantly larger sequences than existing methods.
Naamapadam: A Large-Scale Named Entity Annotated Data for Indic Languages
Dec 20, 2022



We present, Naamapadam, the largest publicly available Named Entity Recognition (NER) dataset for the 11 major Indian languages from two language families. In each language, it contains more than 400k sentences annotated with a total of at least 100k entities from three standard entity categories (Person, Location and Organization) for 9 out of the 11 languages. The training dataset has been automatically created from the Samanantar parallel corpus by projecting automatically tagged entities from an English sentence to the corresponding Indian language sentence. We also create manually annotated testsets for 8 languages containing approximately 1000 sentences per language. We demonstrate the utility of the obtained dataset on existing testsets and the Naamapadam-test data for 8 Indic languages. We also release IndicNER, a multilingual mBERT model fine-tuned on the Naamapadam training set. IndicNER achieves the best F1 on the Naamapadam-test set compared to an mBERT model fine-tuned on existing datasets. IndicNER achieves an F1 score of more than 80 for 7 out of 11 Indic languages. The dataset and models are available under open-source licenses at https://ai4bharat.iitm.ac.in/naamapadam.
Role of Language Relatedness in Multilingual Fine-tuning of Language Models: A Case Study in Indo-Aryan Languages
Sep 22, 2021
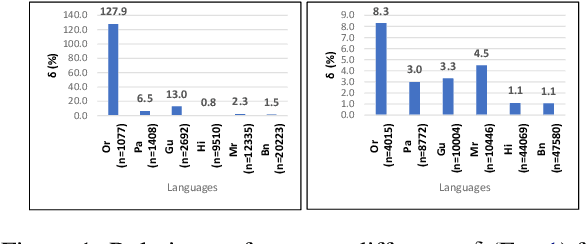

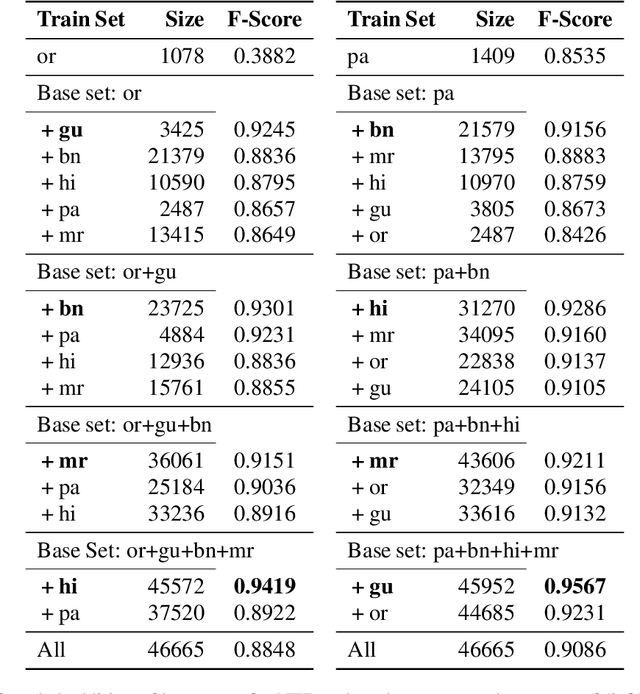
We explore the impact of leveraging the relatedness of languages that belong to the same family in NLP models using multilingual fine-tuning. We hypothesize and validate that multilingual fine-tuning of pre-trained language models can yield better performance on downstream NLP applications, compared to models fine-tuned on individual languages. A first of its kind detailed study is presented to track performance change as languages are added to a base language in a graded and greedy (in the sense of best boost of performance) manner; which reveals that careful selection of subset of related languages can significantly improve performance than utilizing all related languages. The Indo-Aryan (IA) language family is chosen for the study, the exact languages being Bengali, Gujarati, Hindi, Marathi, Oriya, Punjabi and Urdu. The script barrier is crossed by simple rule-based transliteration of the text of all languages to Devanagari. Experiments are performed on mBERT, IndicBERT, MuRIL and two RoBERTa-based LMs, the last two being pre-trained by us. Low resource languages, such as Oriya and Punjabi, are found to be the largest beneficiaries of multilingual fine-tuning. Textual Entailment, Entity Classification, Section Title Prediction, tasks of IndicGLUE and POS tagging form our test bed. Compared to monolingual fine tuning we get relative performance improvement of up to 150% in the downstream tasks. The surprise take-away is that for any language there is a particular combination of other languages which yields the best performance, and any additional language is in fact detrimental.
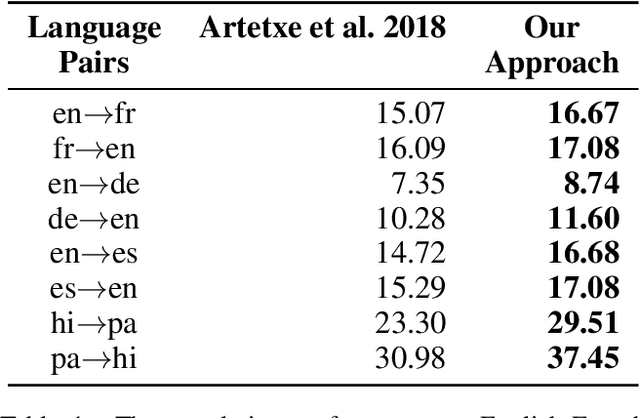
Crosslingual Embeddings are Essential in UNMT for Distant Languages: An English to IndoAryan Case Study
Jun 09, 2021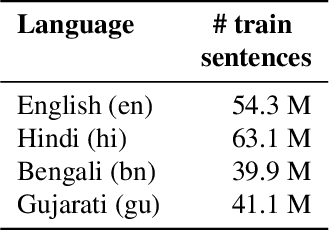
Recent advances in Unsupervised Neural Machine Translation (UNMT) have minimized the gap between supervised and unsupervised machine translation performance for closely related language pairs. However, the situation is very different for distant language pairs. Lack of lexical overlap and low syntactic similarities such as between English and Indo-Aryan languages leads to poor translation quality in existing UNMT systems. In this paper, we show that initializing the embedding layer of UNMT models with cross-lingual embeddings shows significant improvements in BLEU score over existing approaches with embeddings randomly initialized. Further, static embeddings (freezing the embedding layer weights) lead to better gains compared to updating the embedding layer weights during training (non-static). We experimented using Masked Sequence to Sequence (MASS) and Denoising Autoencoder (DAE) UNMT approaches for three distant language pairs. The proposed cross-lingual embedding initialization yields BLEU score improvement of as much as ten times over the baseline for English-Hindi, English-Bengali, and English-Gujarati. Our analysis shows the importance of cross-lingual embedding, comparisons between approaches, and the scope of improvements in these systems.
Ordering Matters: Word Ordering Aware Unsupervised NMT
Oct 30, 2019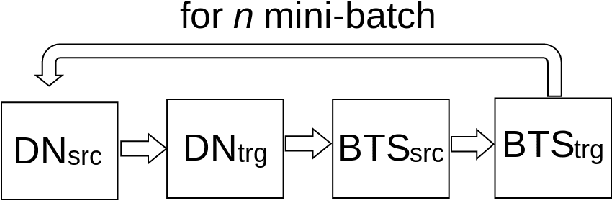
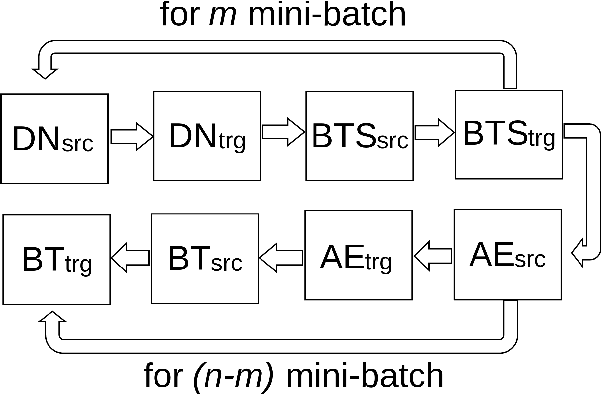
Denoising-based Unsupervised Neural Machine Translation (U-NMT) models typically employ denoising strategy at the encoder module to prevent the model from memorizing the input source sentence. Specifically, given an input sentence of length n, the model applies n/2 random swaps between consecutive words and trains the denoising-based U-NMT model. Though effective, applying denoising strategy on every sentence in the training data leads to uncertainty in the model thereby, limiting the benefits from the denoising-based U-NMT model. In this paper, we propose a simple fine-tuning strategy where we fine-tune the trained denoising-based U-NMT system without the denoising strategy. The input sentences are presented as is i.e., without any shuffling noise added. We observe significant improvements in translation performance on many language pairs from our fine-tuning strategy. Our analysis reveals that our proposed models lead to increase in higher n-gram BLEU score compared to the denoising U-NMT models.
Addressing word-order Divergence in Multilingual Neural Machine Translation for extremely Low Resource Languages
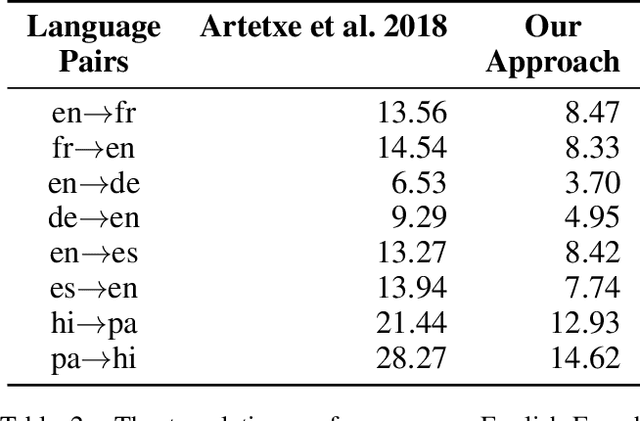
Nov 01, 2018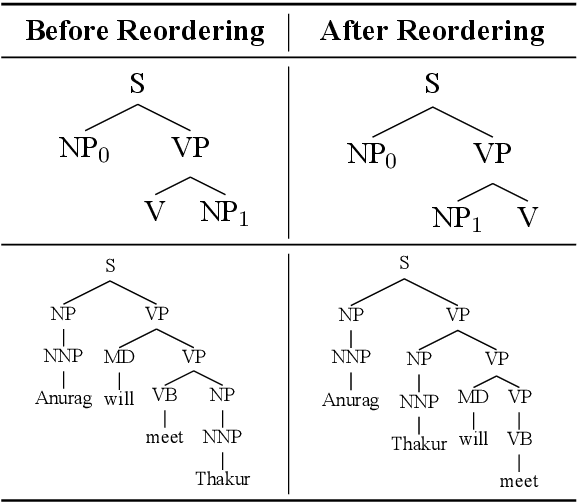
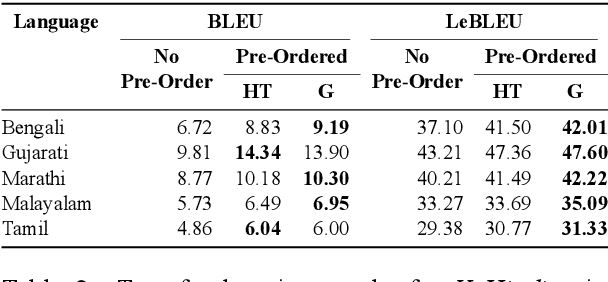
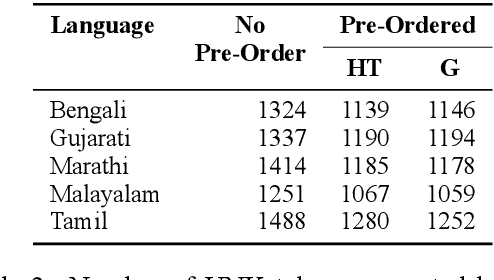
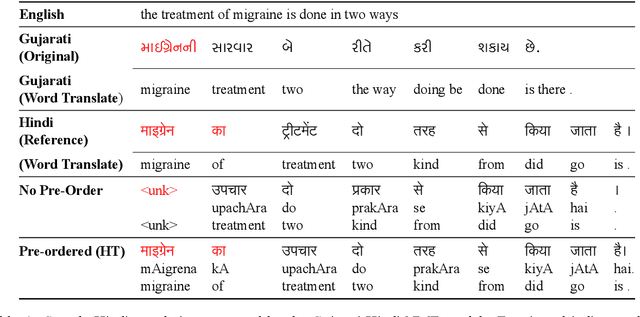
Transfer learning approaches for Neural Machine Translation (NMT) train a NMT model on the assisting-target language pair (parent model) which is later fine-tuned for the source-target language pair of interest (child model), with the target language being the same. In many cases, the assisting language has a different word order from the source language. We show that divergent word order adversely limits the benefits from transfer learning when little to no parallel corpus between the source and target language is available. To bridge this divergence, We propose to pre-order the assisting language sentence to match the word order of the source language and train the parent model. Our experiments on many language pairs show that bridging the word order gap leads to significant improvement in the translation quality.
Sharing Network Parameters for Crosslingual Named Entity Recognition
Jul 01, 2016


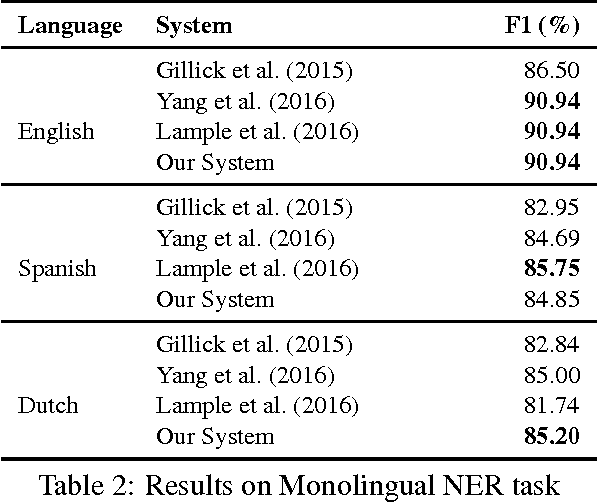
Most state of the art approaches for Named Entity Recognition rely on hand crafted features and annotated corpora. Recently Neural network based models have been proposed which do not require handcrafted features but still require annotated corpora. However, such annotated corpora may not be available for many languages. In this paper, we propose a neural network based model which allows sharing the decoder as well as word and character level parameters between two languages thereby allowing a resource fortunate language to aid a resource deprived language. Specifically, we focus on the case when limited annotated corpora is available in one language ($L_1$) and abundant annotated corpora is available in another language ($L_2$). Sharing the network architecture and parameters between $L_1$ and $L_2$ leads to improved performance in $L_1$. Further, our approach does not require any hand crafted features but instead directly learns meaningful feature representations from the training data itself. We experiment with 4 language pairs and show that indeed in a resource constrained setup (lesser annotated corpora), a model jointly trained with data from another language performs better than a model trained only on the limited corpora in one language.