 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIndicDLP: A Foundational Dataset for Multi-Lingual and Multi-Domain Document Layout Parsing
Dec 23, 2025Document layout analysis is essential for downstream tasks such as information retrieval, extraction, OCR, and digitization. However, existing large-scale datasets like PubLayNet and DocBank lack fine-grained region labels and multilingual diversity, making them insufficient for representing complex document layouts. In contrast, human-annotated datasets such as M6Doc and D4LA offer richer labels and greater domain diversity, but are too small to train robust models and lack adequate multilingual coverage. This gap is especially pronounced for Indic documents, which encompass diverse scripts yet remain underrepresented in current datasets, further limiting progress in this space. To address these shortcomings, we introduce IndicDLP, a large-scale foundational document layout dataset spanning 11 representative Indic languages alongside English and 12 common document domains. Additionally, we curate UED-mini, a dataset derived from DocLayNet and M6Doc, to enhance pretraining and provide a solid foundation for Indic layout models. Our experiments demonstrate that fine-tuning existing English models on IndicDLP significantly boosts performance, validating its effectiveness. Moreover, models trained on IndicDLP generalize well beyond Indic layouts, making it a valuable resource for document digitization. This work bridges gaps in scale, diversity, and annotation granularity, driving inclusive and efficient document understanding.
IndicVoices-R: Unlocking a Massive Multilingual Multi-speaker Speech Corpus for Scaling Indian TTS
Sep 09, 2024



Recent advancements in text-to-speech (TTS) synthesis show that large-scale models trained with extensive web data produce highly natural-sounding output. However, such data is scarce for Indian languages due to the lack of high-quality, manually subtitled data on platforms like LibriVox or YouTube. To address this gap, we enhance existing large-scale ASR datasets containing natural conversations collected in low-quality environments to generate high-quality TTS training data. Our pipeline leverages the cross-lingual generalization of denoising and speech enhancement models trained on English and applied to Indian languages. This results in IndicVoices-R (IV-R), the largest multilingual Indian TTS dataset derived from an ASR dataset, with 1,704 hours of high-quality speech from 10,496 speakers across 22 Indian languages. IV-R matches the quality of gold-standard TTS datasets like LJSpeech, LibriTTS, and IndicTTS. We also introduce the IV-R Benchmark, the first to assess zero-shot, few-shot, and many-shot speaker generalization capabilities of TTS models on Indian voices, ensuring diversity in age, gender, and style. We demonstrate that fine-tuning an English pre-trained model on a combined dataset of high-quality IndicTTS and our IV-R dataset results in better zero-shot speaker generalization compared to fine-tuning on the IndicTTS dataset alone. Further, our evaluation reveals limited zero-shot generalization for Indian voices in TTS models trained on prior datasets, which we improve by fine-tuning the model on our data containing diverse set of speakers across language families. We open-source all data and code, releasing the first TTS model for all 22 official Indian languages.
OpenHands: Making Sign Language Recognition Accessible with Pose-based Pretrained Models across Languages
Oct 12, 2021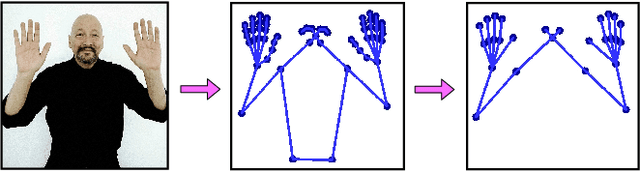
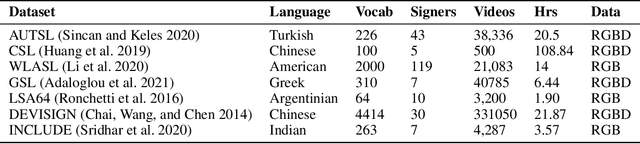
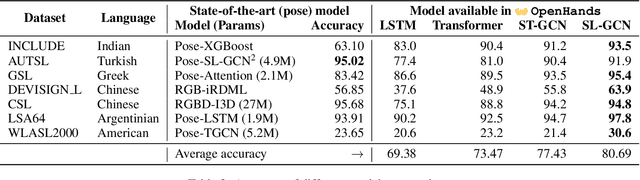
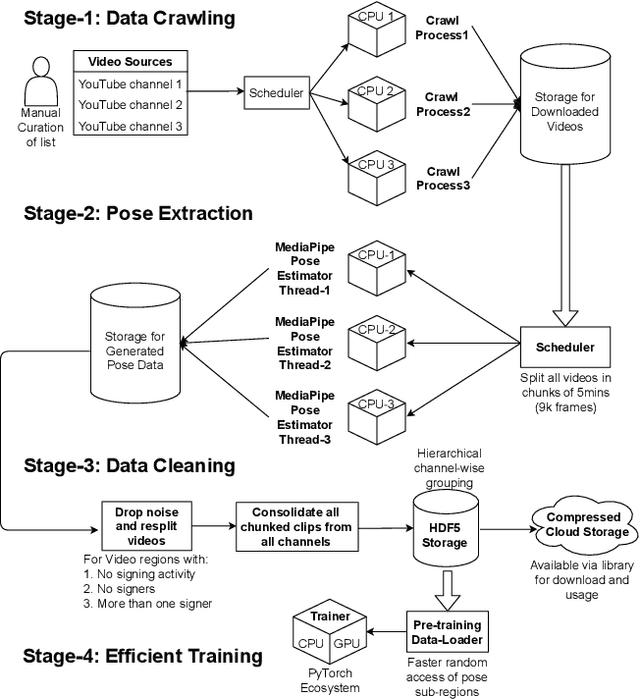
AI technologies for Natural Languages have made tremendous progress recently. However, commensurate progress has not been made on Sign Languages, in particular, in recognizing signs as individual words or as complete sentences. We introduce OpenHands, a library where we take four key ideas from the NLP community for low-resource languages and apply them to sign languages for word-level recognition. First, we propose using pose extracted through pretrained models as the standard modality of data to reduce training time and enable efficient inference, and we release standardized pose datasets for 6 different sign languages - American, Argentinian, Chinese, Greek, Indian, and Turkish. Second, we train and release checkpoints of 4 pose-based isolated sign language recognition models across all 6 languages, providing baselines and ready checkpoints for deployment. Third, to address the lack of labelled data, we propose self-supervised pretraining on unlabelled data. We curate and release the largest pose-based pretraining dataset on Indian Sign Language (Indian-SL). Fourth, we compare different pretraining strategies and for the first time establish that pretraining is effective for sign language recognition by demonstrating (a) improved fine-tuning performance especially in low-resource settings, and (b) high crosslingual transfer from Indian-SL to few other sign languages. We open-source all models and datasets in OpenHands with a hope that it makes research in sign languages more accessible, available here at https://github.com/AI4Bharat/OpenHands .
Diversity driven Attention Model for Query-based Abstractive Summarization
Jul 13, 2018


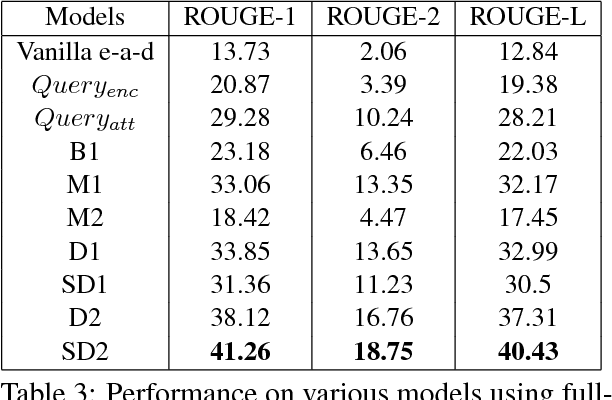
Abstractive summarization aims to generate a shorter version of the document covering all the salient points in a compact and coherent fashion. On the other hand, query-based summarization highlights those points that are relevant in the context of a given query. The encode-attend-decode paradigm has achieved notable success in machine translation, extractive summarization, dialog systems, etc. But it suffers from the drawback of generation of repeated phrases. In this work we propose a model for the query-based summarization task based on the encode-attend-decode paradigm with two key additions (i) a query attention model (in addition to document attention model) which learns to focus on different portions of the query at different time steps (instead of using a static representation for the query) and (ii) a new diversity based attention model which aims to alleviate the problem of repeating phrases in the summary. In order to enable the testing of this model we introduce a new query-based summarization dataset building on debatepedia. Our experiments show that with these two additions the proposed model clearly outperforms vanilla encode-attend-decode models with a gain of 28% (absolute) in ROUGE-L scores.
Towards Building Large Scale Multimodal Domain-Aware Conversation Systems
Jan 31, 2018


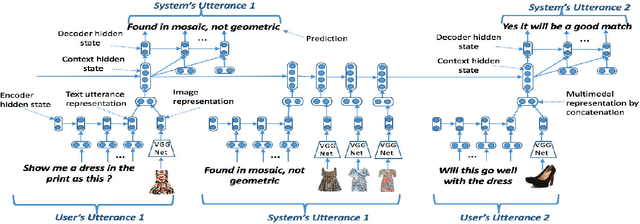
While multimodal conversation agents are gaining importance in several domains such as retail, travel etc., deep learning research in this area has been limited primarily due to the lack of availability of large-scale, open chatlogs. To overcome this bottleneck, in this paper we introduce the task of multimodal, domain-aware conversations, and propose the MMD benchmark dataset. This dataset was gathered by working in close coordination with large number of domain experts in the retail domain. These experts suggested various conversations flows and dialog states which are typically seen in multimodal conversations in the fashion domain. Keeping these flows and states in mind, we created a dataset consisting of over 150K conversation sessions between shoppers and sales agents, with the help of in-house annotators using a semi-automated manually intense iterative process. With this dataset, we propose 5 new sub-tasks for multimodal conversations along with their evaluation methodology. We also propose two multimodal neural models in the encode-attend-decode paradigm and demonstrate their performance on two of the sub-tasks, namely text response generation and best image response selection. These experiments serve to establish baseline performance and open new research directions for each of these sub-tasks. Further, for each of the sub-tasks, we present a `per-state evaluation' of 9 most significant dialog states, which would enable more focused research into understanding the challenges and complexities involved in each of these states.
Sharing Network Parameters for Crosslingual Named Entity Recognition
Jul 01, 2016


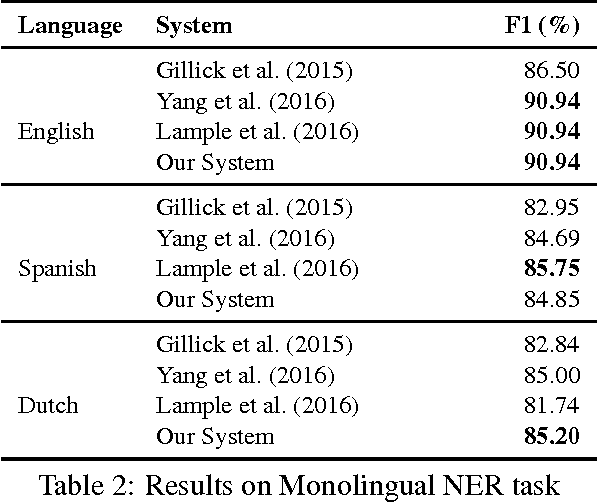
Most state of the art approaches for Named Entity Recognition rely on hand crafted features and annotated corpora. Recently Neural network based models have been proposed which do not require handcrafted features but still require annotated corpora. However, such annotated corpora may not be available for many languages. In this paper, we propose a neural network based model which allows sharing the decoder as well as word and character level parameters between two languages thereby allowing a resource fortunate language to aid a resource deprived language. Specifically, we focus on the case when limited annotated corpora is available in one language ($L_1$) and abundant annotated corpora is available in another language ($L_2$). Sharing the network architecture and parameters between $L_1$ and $L_2$ leads to improved performance in $L_1$. Further, our approach does not require any hand crafted features but instead directly learns meaningful feature representations from the training data itself. We experiment with 4 language pairs and show that indeed in a resource constrained setup (lesser annotated corpora), a model jointly trained with data from another language performs better than a model trained only on the limited corpora in one language.