 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn Controllable Sparse Alternatives to Softmax
Oct 30, 2018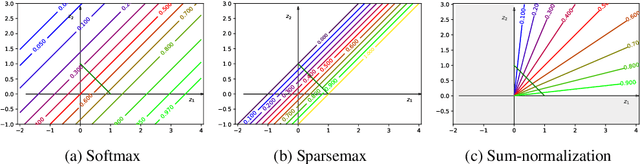
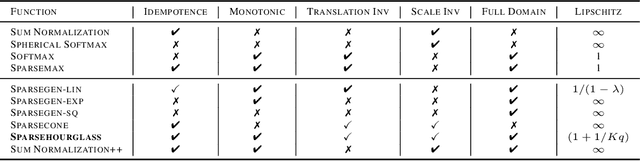
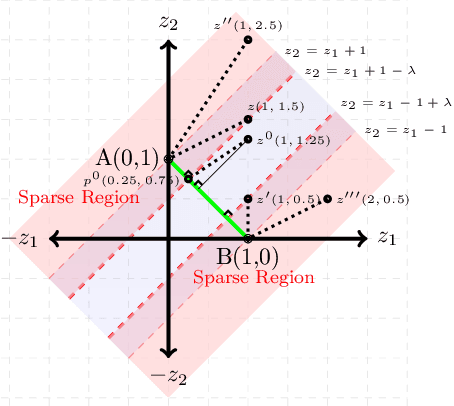
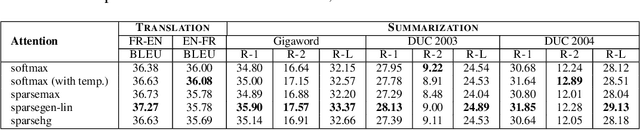
Converting an n-dimensional vector to a probability distribution over n objects is a commonly used component in many machine learning tasks like multiclass classification, multilabel classification, attention mechanisms etc. For this, several probability mapping functions have been proposed and employed in literature such as softmax, sum-normalization, spherical softmax, and sparsemax, but there is very little understanding in terms how they relate with each other. Further, none of the above formulations offer an explicit control over the degree of sparsity. To address this, we develop a unified framework that encompasses all these formulations as special cases. This framework ensures simple closed-form solutions and existence of sub-gradients suitable for learning via backpropagation. Within this framework, we propose two novel sparse formulations, sparsegen-lin and sparsehourglass, that seek to provide a control over the degree of desired sparsity. We further develop novel convex loss functions that help induce the behavior of aforementioned formulations in the multilabel classification setting, showing improved performance. We also demonstrate empirically that the proposed formulations, when used to compute attention weights, achieve better or comparable performance on standard seq2seq tasks like neural machine translation and abstractive summarization.
Unsupervised Neural Text Simplification
Oct 18, 2018
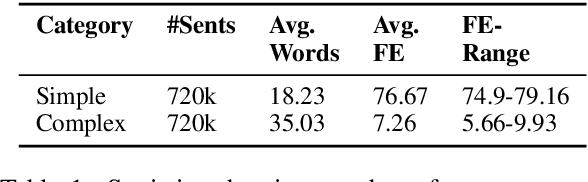
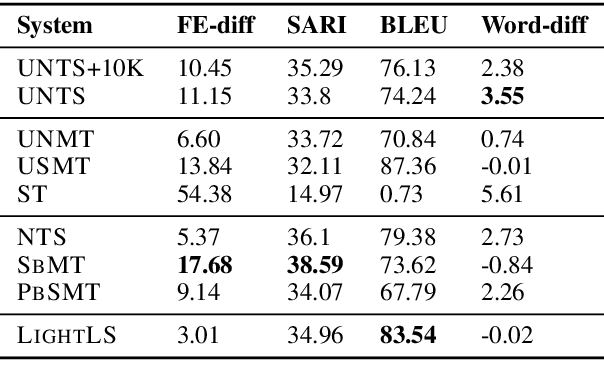
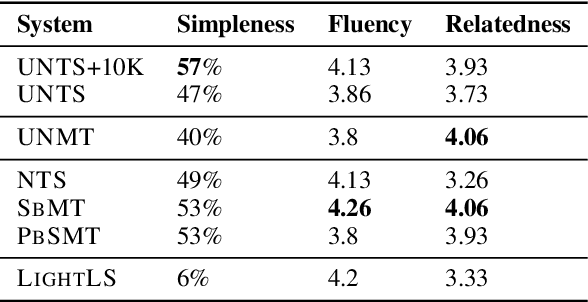
The paper presents a first attempt towards unsupervised neural text simplification that relies only on unlabeled text corpora. The core framework is comprised of a shared encoder and a pair of attentional-decoders that gains knowledge of both text simplification and complexification through discriminator-based-losses, back-translation and denoising. The framework is trained using unlabeled text collected from en-Wikipedia dump. Our analysis (both quantitative and qualitative involving human evaluators) on a public test data shows the efficacy of our model to perform simplification at both lexical and syntactic levels, competitive to existing supervised methods. We open source our implementation for academic use.
Diversity driven Attention Model for Query-based Abstractive Summarization
Jul 13, 2018


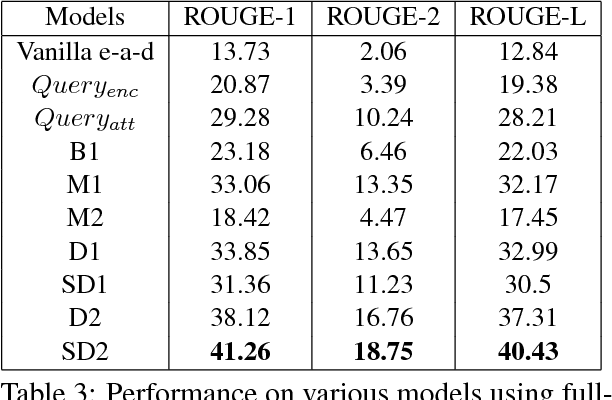
Abstractive summarization aims to generate a shorter version of the document covering all the salient points in a compact and coherent fashion. On the other hand, query-based summarization highlights those points that are relevant in the context of a given query. The encode-attend-decode paradigm has achieved notable success in machine translation, extractive summarization, dialog systems, etc. But it suffers from the drawback of generation of repeated phrases. In this work we propose a model for the query-based summarization task based on the encode-attend-decode paradigm with two key additions (i) a query attention model (in addition to document attention model) which learns to focus on different portions of the query at different time steps (instead of using a static representation for the query) and (ii) a new diversity based attention model which aims to alleviate the problem of repeating phrases in the summary. In order to enable the testing of this model we introduce a new query-based summarization dataset building on debatepedia. Our experiments show that with these two additions the proposed model clearly outperforms vanilla encode-attend-decode models with a gain of 28% (absolute) in ROUGE-L scores.
A Mixed Hierarchical Attention based Encoder-Decoder Approach for Standard Table Summarization
Apr 20, 2018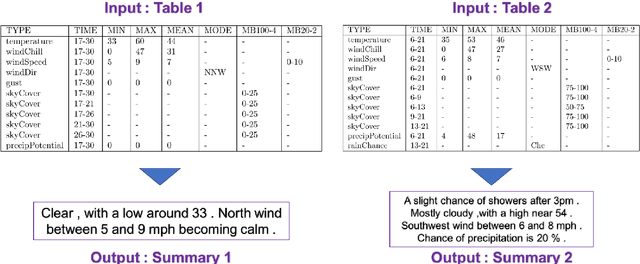
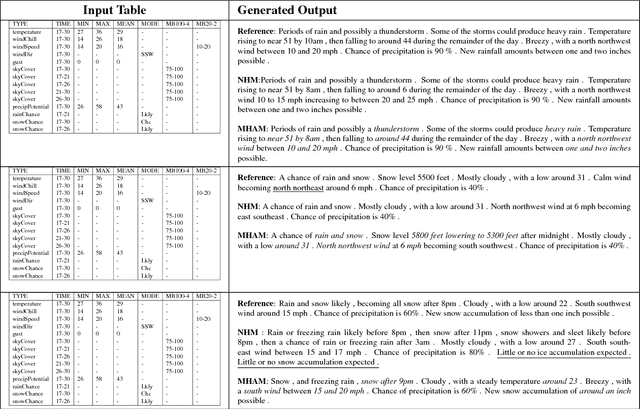
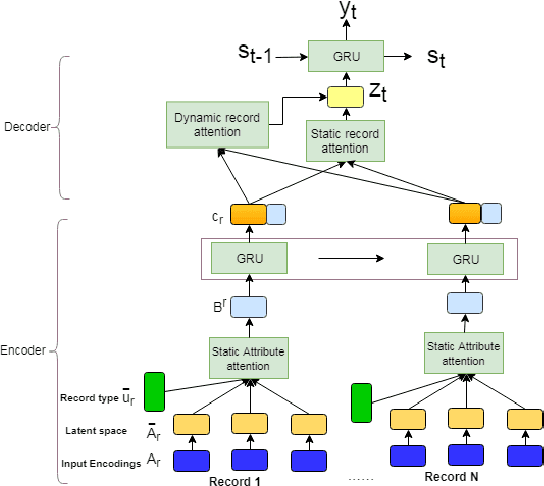
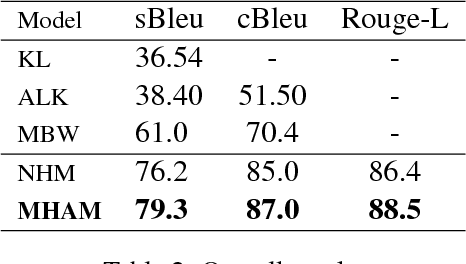
Structured data summarization involves generation of natural language summaries from structured input data. In this work, we consider summarizing structured data occurring in the form of tables as they are prevalent across a wide variety of domains. We formulate the standard table summarization problem, which deals with tables conforming to a single predefined schema. To this end, we propose a mixed hierarchical attention based encoder-decoder model which is able to leverage the structure in addition to the content of the tables. Our experiments on the publicly available WEATHERGOV dataset show around 18 BLEU (~ 30%) improvement over the current state-of-the-art.
Generating Descriptions from Structured Data Using a Bifocal Attention Mechanism and Gated Orthogonalization
Apr 20, 2018
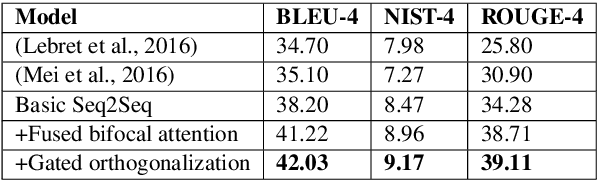
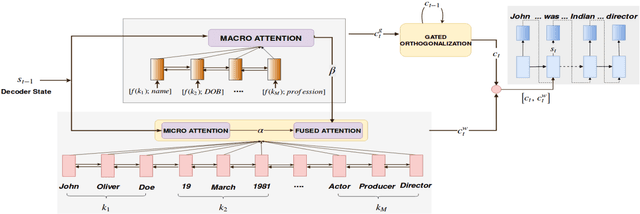

In this work, we focus on the task of generating natural language descriptions from a structured table of facts containing fields (such as nationality, occupation, etc) and values (such as Indian, actor, director, etc). One simple choice is to treat the table as a sequence of fields and values and then use a standard seq2seq model for this task. However, such a model is too generic and does not exploit task-specific characteristics. For example, while generating descriptions from a table, a human would attend to information at two levels: (i) the fields (macro level) and (ii) the values within the field (micro level). Further, a human would continue attending to a field for a few timesteps till all the information from that field has been rendered and then never return back to this field (because there is nothing left to say about it). To capture this behavior we use (i) a fused bifocal attention mechanism which exploits and combines this micro and macro level information and (ii) a gated orthogonalization mechanism which tries to ensure that a field is remembered for a few time steps and then forgotten. We experiment with a recently released dataset which contains fact tables about people and their corresponding one line biographical descriptions in English. In addition, we also introduce two similar datasets for French and German. Our experiments show that the proposed model gives 21% relative improvement over a recently proposed state of the art method and 10% relative improvement over basic seq2seq models. The code and the datasets developed as a part of this work are publicly available.
Story Generation from Sequence of Independent Short Descriptions
Aug 21, 2017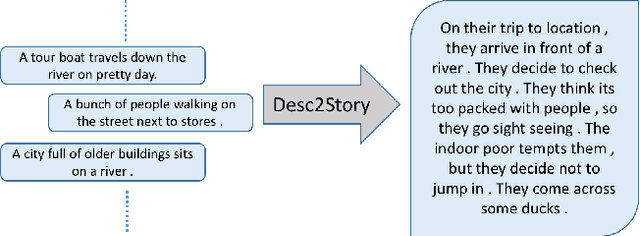
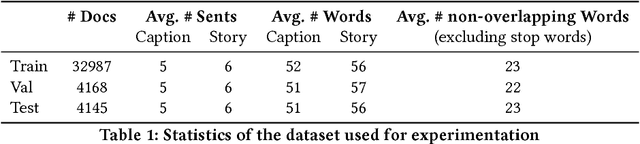
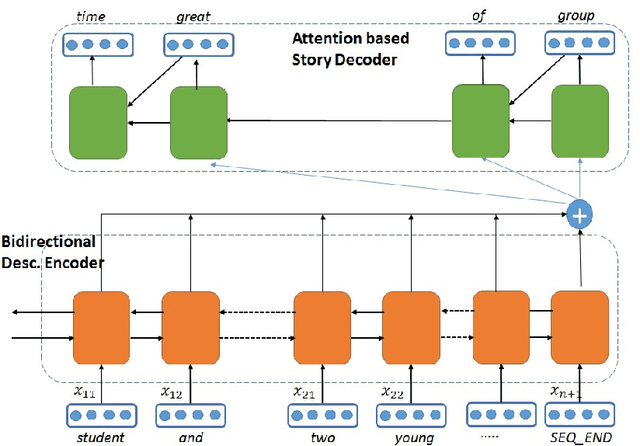
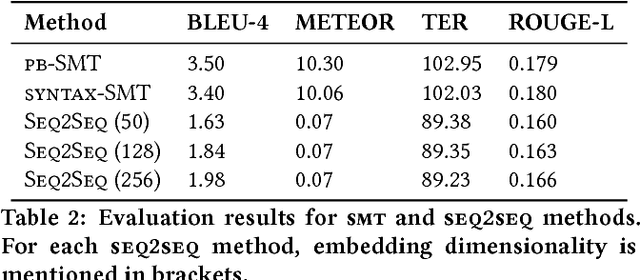
Existing Natural Language Generation (NLG) systems are weak AI systems and exhibit limited capabilities when language generation tasks demand higher levels of creativity, originality and brevity. Effective solutions or, at least evaluations of modern NLG paradigms for such creative tasks have been elusive, unfortunately. This paper introduces and addresses the task of coherent story generation from independent descriptions, describing a scene or an event. Towards this, we explore along two popular text-generation paradigms -- (1) Statistical Machine Translation (SMT), posing story generation as a translation problem and (2) Deep Learning, posing story generation as a sequence to sequence learning problem. In SMT, we chose two popular methods such as phrase based SMT (PB-SMT) and syntax based SMT (SYNTAX-SMT) to `translate' the incoherent input text into stories. We then implement a deep recurrent neural network (RNN) architecture that encodes sequence of variable length input descriptions to corresponding latent representations and decodes them to produce well formed comprehensive story like summaries. The efficacy of the suggested approaches is demonstrated on a publicly available dataset with the help of popular machine translation and summarization evaluation metrics.
A Machine Learning Approach for Evaluating Creative Artifacts
Jul 18, 2017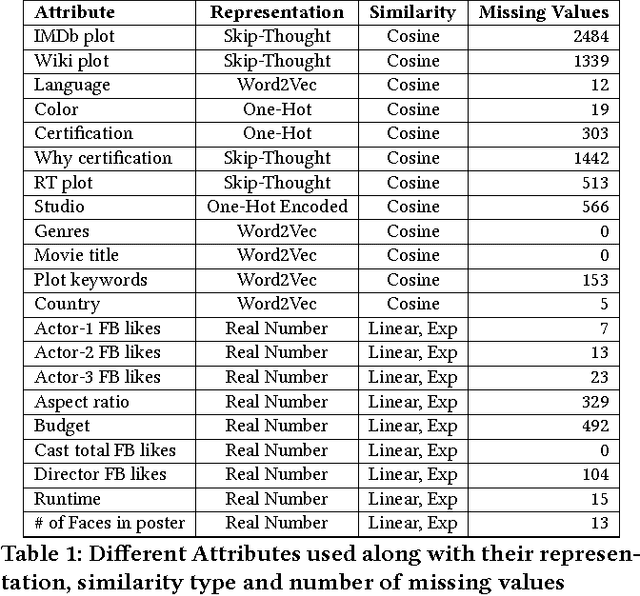
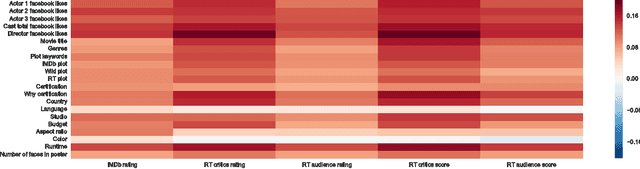
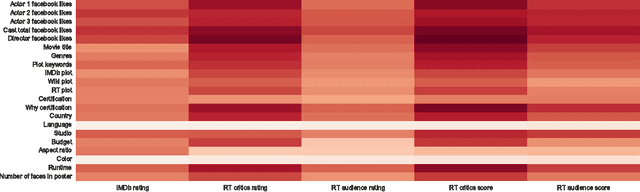
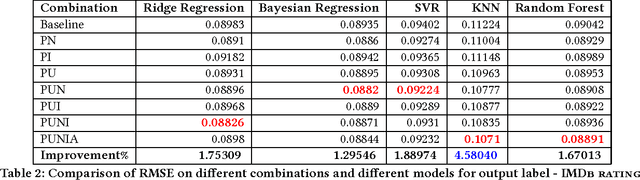
Much work has been done in understanding human creativity and defining measures to evaluate creativity. This is necessary mainly for the reason of having an objective and automatic way of quantifying creative artifacts. In this work, we propose a regression-based learning framework which takes into account quantitatively the essential criteria for creativity like novelty, influence, value and unexpectedness. As it is often the case with most creative domains, there is no clear ground truth available for creativity. Our proposed learning framework is applicable to all creative domains; yet we evaluate it on a dataset of movies created from IMDb and Rotten Tomatoes due to availability of audience and critic scores, which can be used as proxy ground truth labels for creativity. We report promising results and observations from our experiments in the following ways : 1) Correlation of creative criteria with critic scores, 2) Improvement in movie rating prediction with inclusion of various creative criteria, and 3) Identification of creative movies.
Joint Learning of Correlated Sequence Labelling Tasks Using Bidirectional Recurrent Neural Networks
Jul 18, 2017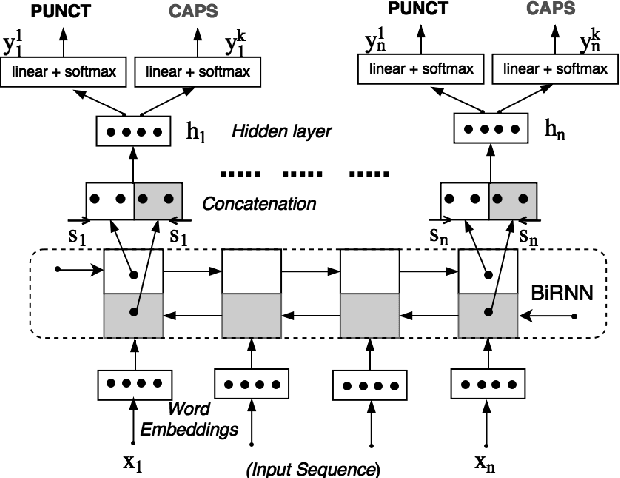
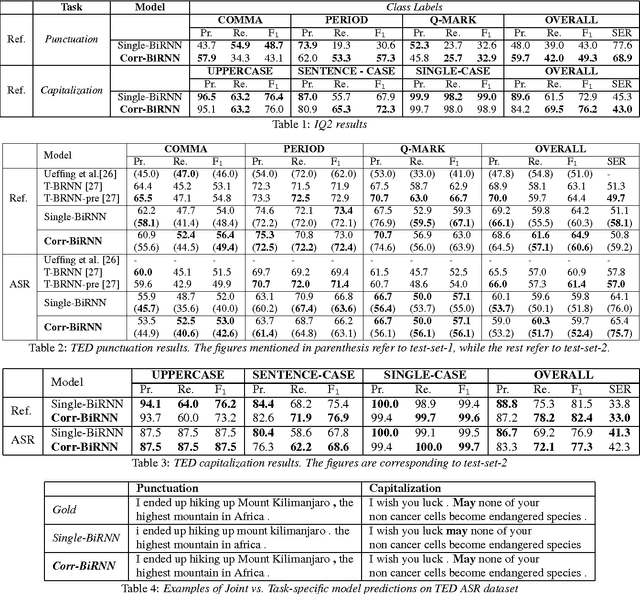
The stream of words produced by Automatic Speech Recognition (ASR) systems is typically devoid of punctuations and formatting. Most natural language processing applications expect segmented and well-formatted texts as input, which is not available in ASR output. This paper proposes a novel technique of jointly modeling multiple correlated tasks such as punctuation and capitalization using bidirectional recurrent neural networks, which leads to improved performance for each of these tasks. This method could be extended for joint modeling of any other correlated sequence labeling tasks.
An Empirical Evaluation of various Deep Learning Architectures for Bi-Sequence Classification Tasks
Oct 02, 2016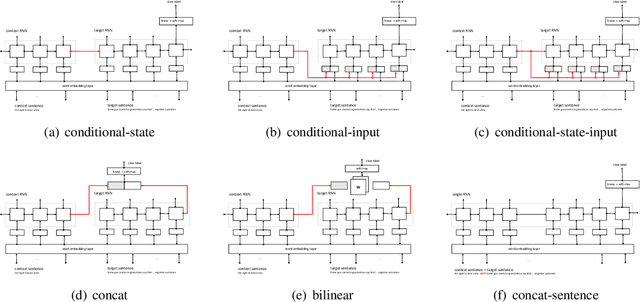
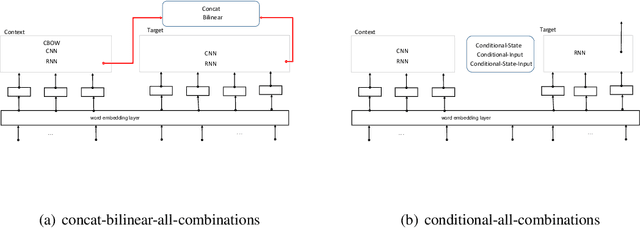

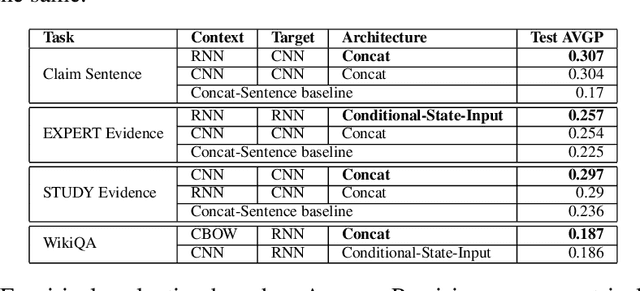
Several tasks in argumentation mining and debating, question-answering, and natural language inference involve classifying a sequence in the context of another sequence (referred as bi-sequence classification). For several single sequence classification tasks, the current state-of-the-art approaches are based on recurrent and convolutional neural networks. On the other hand, for bi-sequence classification problems, there is not much understanding as to the best deep learning architecture. In this paper, we attempt to get an understanding of this category of problems by extensive empirical evaluation of 19 different deep learning architectures (specifically on different ways of handling context) for various problems originating in natural language processing like debating, textual entailment and question-answering. Following the empirical evaluation, we offer our insights and conclusions regarding the architectures we have considered. We also establish the first deep learning baselines for three argumentation mining tasks.