 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEpisodic Memory Model for Learning Robotic Manipulation Tasks
Apr 20, 2021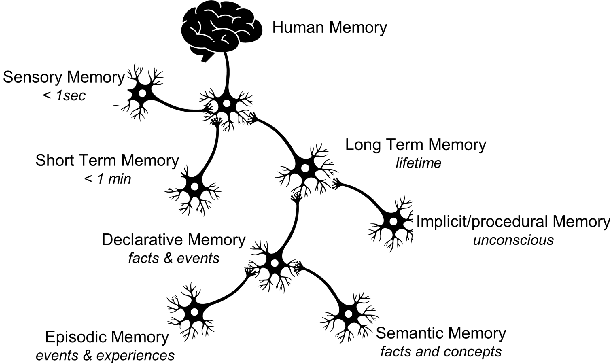
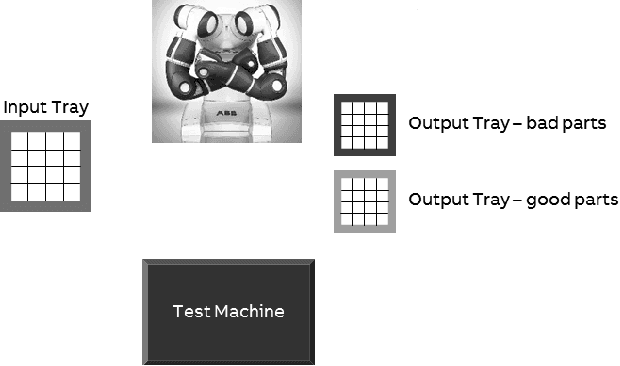
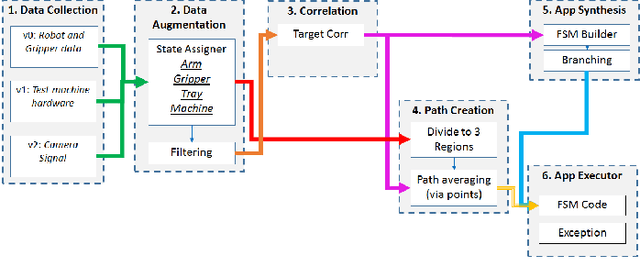
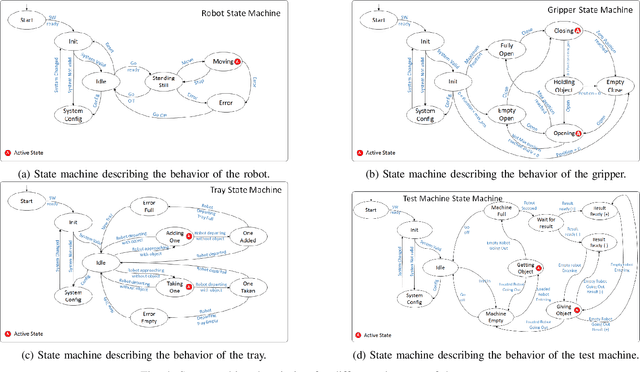
Machine learning, artificial intelligence and especially deep learning based approaches are often used to simplify or eliminate the burden of programming industrial robots. Using these approaches robots inherently learn a skill instead of being programmed using strict and tedious programming instructions. While deep learning is effective in making robots learn skills, it does not offer a practical route for teaching a complete task, such as assembly or machine tending, where a complex logic must be understood and related sub-tasks need to be performed. We present a model similar to an episodic memory that allows robots to comprehend sequences of actions using single demonstration and perform them properly and accurately. The algorithm identifies and recognizes the changes in the states of the system and memorizes how to execute the necessary tasks in order to make those changes. This allows the robot to decompose the tasks into smaller sub-tasks, retain the essential steps, and remember how they have been performed.
Dynamic Knowledge Graphs as Semantic Memory Model for Industrial Robots
Jan 06, 2021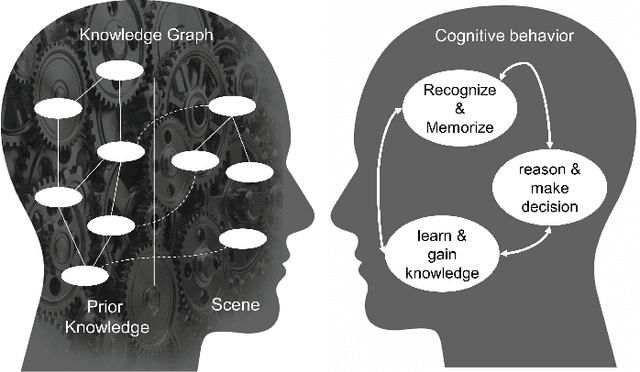
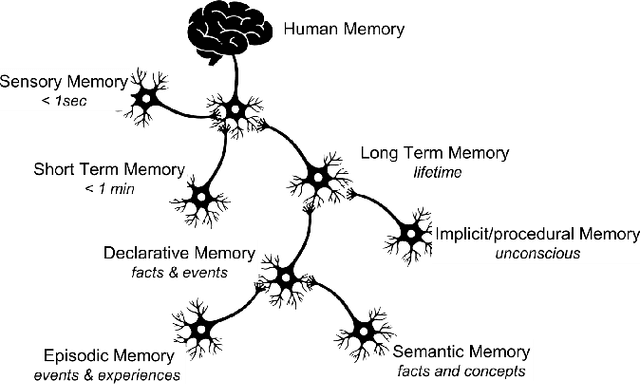
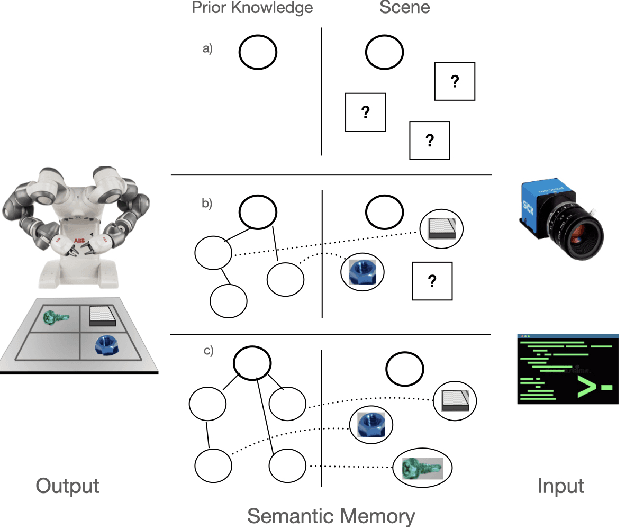
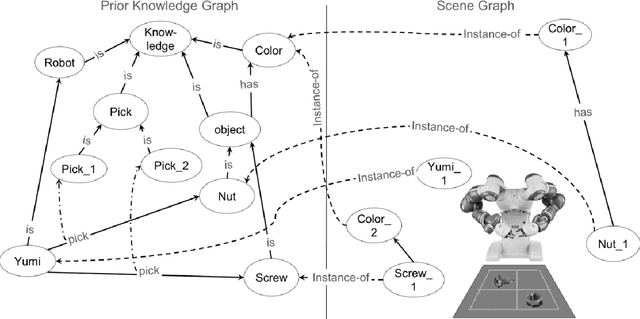
In this paper, we present a model for semantic memory that allows machines to collect information and experiences to become more proficient with time. After a semantic analysis of the data, information is stored in a knowledge graph which is used to comprehend instructions, expressed in natural language, and execute the required tasks in a deterministic manner. This imparts industrial robots cognitive behavior and an intuitive user interface, which is most appreciated in an era, when collaborative robots are to work alongside humans. The paper outlines the architecture of the system together with a practical implementation of the proposal.
Story Generation from Sequence of Independent Short Descriptions
Aug 21, 2017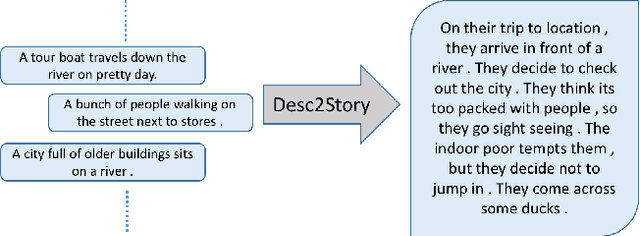
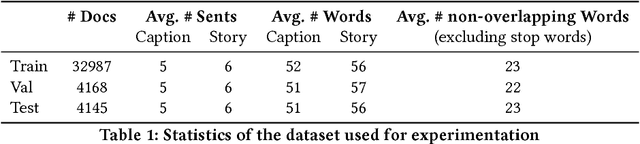
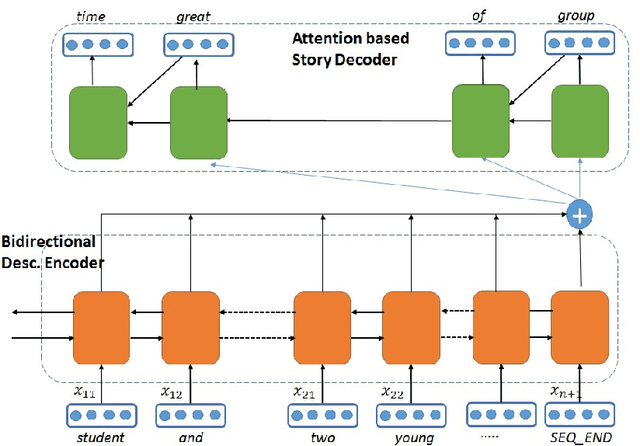
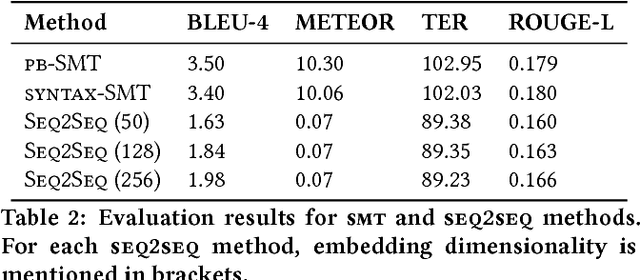
Existing Natural Language Generation (NLG) systems are weak AI systems and exhibit limited capabilities when language generation tasks demand higher levels of creativity, originality and brevity. Effective solutions or, at least evaluations of modern NLG paradigms for such creative tasks have been elusive, unfortunately. This paper introduces and addresses the task of coherent story generation from independent descriptions, describing a scene or an event. Towards this, we explore along two popular text-generation paradigms -- (1) Statistical Machine Translation (SMT), posing story generation as a translation problem and (2) Deep Learning, posing story generation as a sequence to sequence learning problem. In SMT, we chose two popular methods such as phrase based SMT (PB-SMT) and syntax based SMT (SYNTAX-SMT) to `translate' the incoherent input text into stories. We then implement a deep recurrent neural network (RNN) architecture that encodes sequence of variable length input descriptions to corresponding latent representations and decodes them to produce well formed comprehensive story like summaries. The efficacy of the suggested approaches is demonstrated on a publicly available dataset with the help of popular machine translation and summarization evaluation metrics.
A Parameterized Approach to Personalized Variable Length Summarization of Soccer Matches
Jun 28, 2017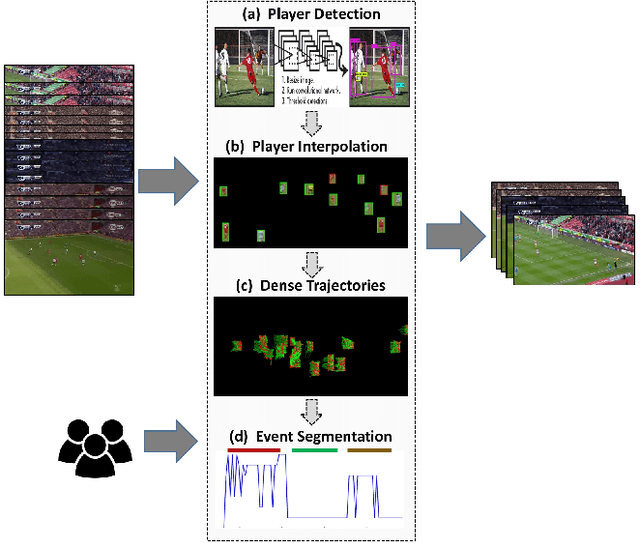
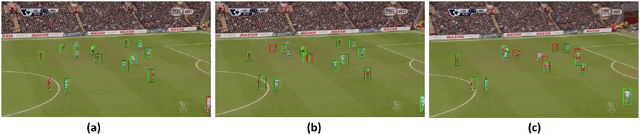


We present a parameterized approach to produce personalized variable length summaries of soccer matches. Our approach is based on temporally segmenting the soccer video into 'plays', associating a user-specifiable 'utility' for each type of play and using 'bin-packing' to select a subset of the plays that add up to the desired length while maximizing the overall utility (volume in bin-packing terms). Our approach systematically allows a user to override the default weights assigned to each type of play with individual preferences and thus see a highly personalized variable length summarization of soccer matches. We demonstrate our approach based on the output of an end-to-end pipeline that we are building to produce such summaries. Though aspects of the overall end-to-end pipeline are human assisted at present, the results clearly show that the proposed approach is capable of producing semantically meaningful and compelling summaries. Besides the obvious use of producing summaries of superior league matches for news broadcasts, we anticipate our work to promote greater awareness of the local matches and junior leagues by producing consumable summaries of them.
Sequence to Sequence Learning for Optical Character Recognition
Dec 27, 2015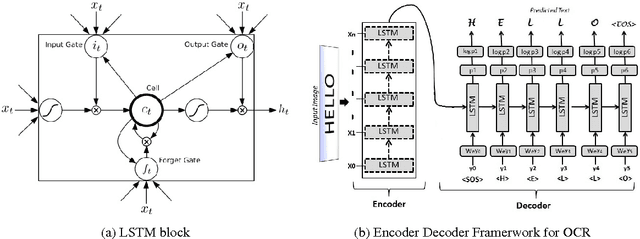
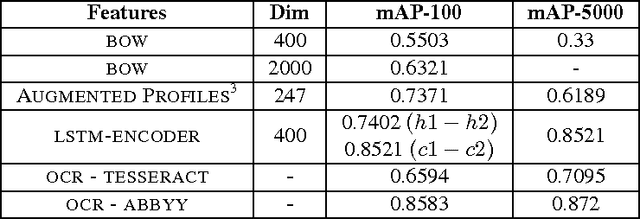
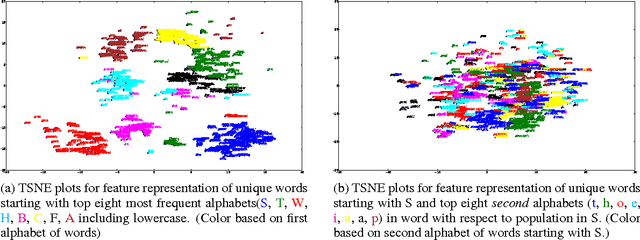
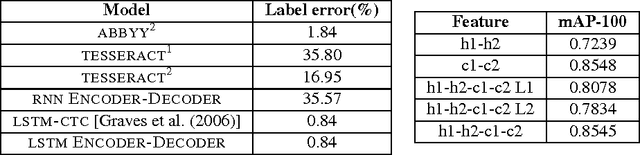
We propose an end-to-end recurrent encoder-decoder based sequence learning approach for printed text Optical Character Recognition (OCR). In contrast to present day existing state-of-art OCR solution which uses connectionist temporal classification (CTC) output layer, our approach makes minimalistic assumptions on the structure and length of the sequence. We use a two step encoder-decoder approach -- (a) A recurrent encoder reads a variable length printed text word image and encodes it to a fixed dimensional embedding. (b) This fixed dimensional embedding is subsequently comprehended by decoder structure which converts it into a variable length text output. Our architecture gives competitive performance relative to connectionist temporal classification (CTC) output layer while being executed in more natural settings. The learnt deep word image embedding from encoder can be used for printed text based retrieval systems. The expressive fixed dimensional embedding for any variable length input expedites the task of retrieval and makes it more efficient which is not possible with other recurrent neural network architectures. We empirically investigate the expressiveness and the learnability of long short term memory (LSTMs) in the sequence to sequence learning regime by training our network for prediction tasks in segmentation free printed text OCR. The utility of the proposed architecture for printed text is demonstrated by quantitative and qualitative evaluation of two tasks -- word prediction and retrieval.
TennisVid2Text: Fine-grained Descriptions for Domain Specific Videos
Nov 26, 2015


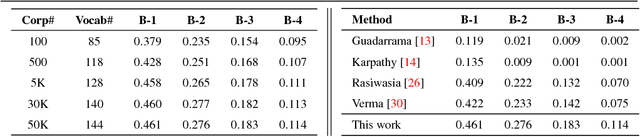
Automatically describing videos has ever been fascinating. In this work, we attempt to describe videos from a specific domain - broadcast videos of lawn tennis matches. Given a video shot from a tennis match, we intend to generate a textual commentary similar to what a human expert would write on a sports website. Unlike many recent works that focus on generating short captions, we are interested in generating semantically richer descriptions. This demands a detailed low-level analysis of the video content, specially the actions and interactions among subjects. We address this by limiting our domain to the game of lawn tennis. Rich descriptions are generated by leveraging a large corpus of human created descriptions harvested from Internet. We evaluate our method on a newly created tennis video data set. Extensive analysis demonstrate that our approach addresses both semantic correctness as well as readability aspects involved in the task.