Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnsupervised Neural Text Simplification
Paper and Code

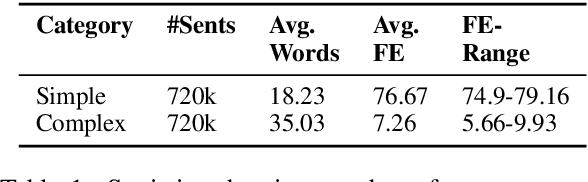
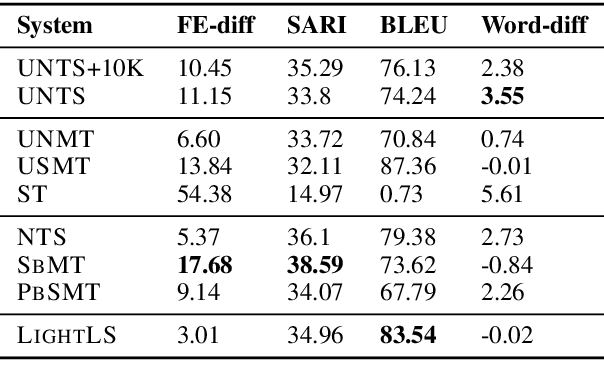
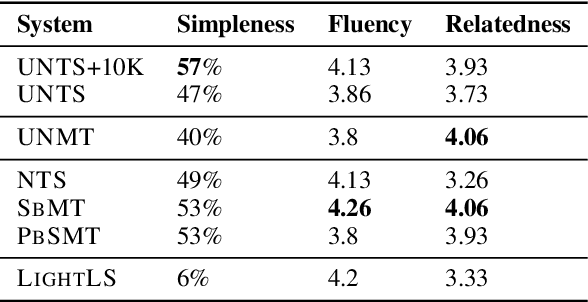
The paper presents a first attempt towards unsupervised neural text simplification that relies only on unlabeled text corpora. The core framework is comprised of a shared encoder and a pair of attentional-decoders that gains knowledge of both text simplification and complexification through discriminator-based-losses, back-translation and denoising. The framework is trained using unlabeled text collected from en-Wikipedia dump. Our analysis (both quantitative and qualitative involving human evaluators) on a public test data shows the efficacy of our model to perform simplification at both lexical and syntactic levels, competitive to existing supervised methods. We open source our implementation for academic use.
* 8 pages, 3 figures
View paper on