 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Design Space for Intelligent and Interactive Writing Assistants
Mar 26, 2024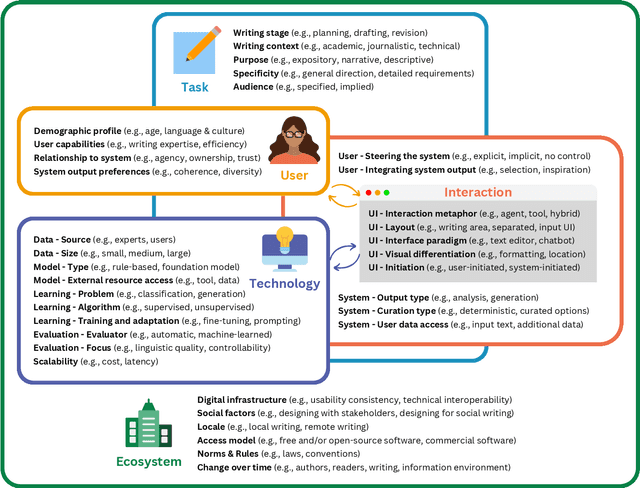
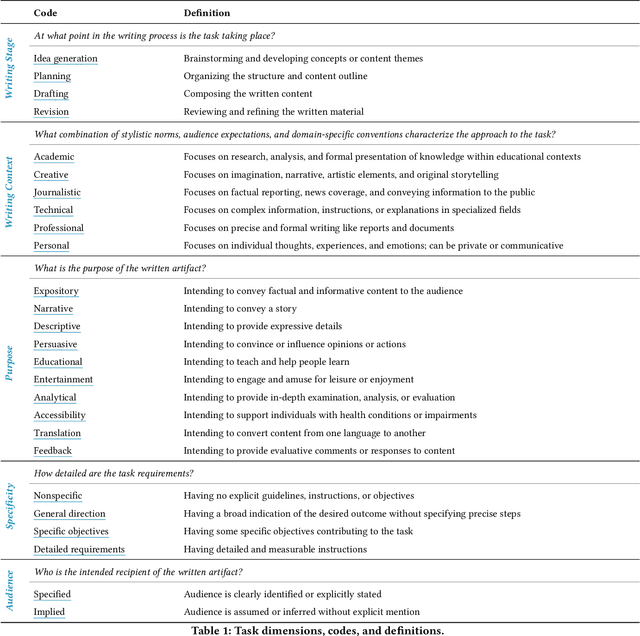
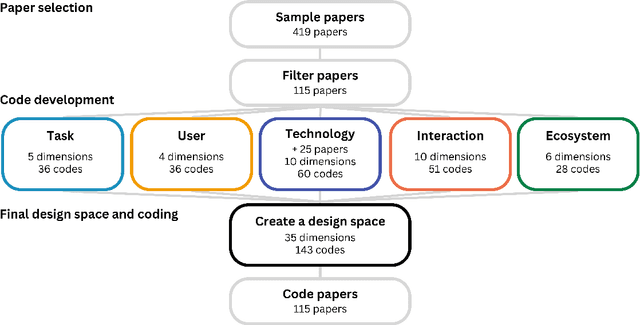
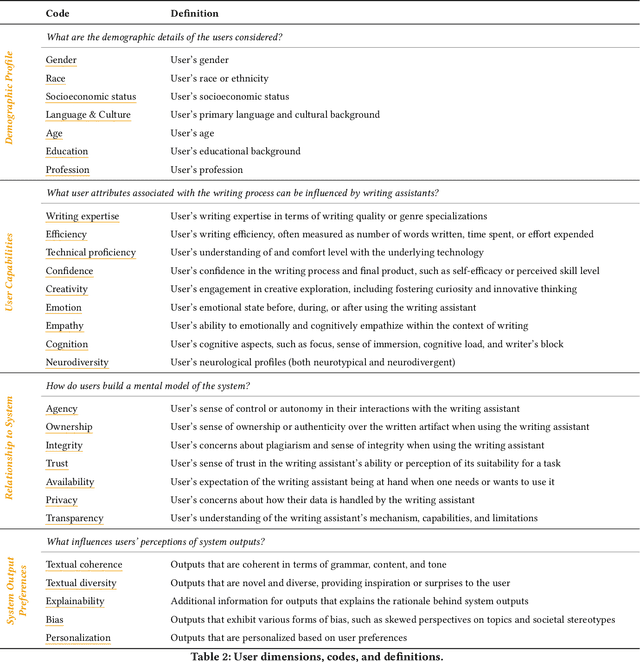
In our era of rapid technological advancement, the research landscape for writing assistants has become increasingly fragmented across various research communities. We seek to address this challenge by proposing a design space as a structured way to examine and explore the multidimensional space of intelligent and interactive writing assistants. Through a large community collaboration, we explore five aspects of writing assistants: task, user, technology, interaction, and ecosystem. Within each aspect, we define dimensions (i.e., fundamental components of an aspect) and codes (i.e., potential options for each dimension) by systematically reviewing 115 papers. Our design space aims to offer researchers and designers a practical tool to navigate, comprehend, and compare the various possibilities of writing assistants, and aid in the envisioning and design of new writing assistants.
Gemini 1.5: Unlocking multimodal understanding across millions of tokens of context
Mar 08, 2024In this report, we present the latest model of the Gemini family, Gemini 1.5 Pro, a highly compute-efficient multimodal mixture-of-experts model capable of recalling and reasoning over fine-grained information from millions of tokens of context, including multiple long documents and hours of video and audio. Gemini 1.5 Pro achieves near-perfect recall on long-context retrieval tasks across modalities, improves the state-of-the-art in long-document QA, long-video QA and long-context ASR, and matches or surpasses Gemini 1.0 Ultra's state-of-the-art performance across a broad set of benchmarks. Studying the limits of Gemini 1.5 Pro's long-context ability, we find continued improvement in next-token prediction and near-perfect retrieval (>99%) up to at least 10M tokens, a generational leap over existing models such as Claude 2.1 (200k) and GPT-4 Turbo (128k). Finally, we highlight surprising new capabilities of large language models at the frontier; when given a grammar manual for Kalamang, a language with fewer than 200 speakers worldwide, the model learns to translate English to Kalamang at a similar level to a person who learned from the same content.
Gemini: A Family of Highly Capable Multimodal Models
Dec 19, 2023This report introduces a new family of multimodal models, Gemini, that exhibit remarkable capabilities across image, audio, video, and text understanding. The Gemini family consists of Ultra, Pro, and Nano sizes, suitable for applications ranging from complex reasoning tasks to on-device memory-constrained use-cases. Evaluation on a broad range of benchmarks shows that our most-capable Gemini Ultra model advances the state of the art in 30 of 32 of these benchmarks - notably being the first model to achieve human-expert performance on the well-studied exam benchmark MMLU, and improving the state of the art in every one of the 20 multimodal benchmarks we examined. We believe that the new capabilities of Gemini models in cross-modal reasoning and language understanding will enable a wide variety of use cases and we discuss our approach toward deploying them responsibly to users.
RepoFusion: Training Code Models to Understand Your Repository
Jun 19, 2023



Despite the huge success of Large Language Models (LLMs) in coding assistants like GitHub Copilot, these models struggle to understand the context present in the repository (e.g., imports, parent classes, files with similar names, etc.), thereby producing inaccurate code completions. This effect is more pronounced when using these assistants for repositories that the model has not seen during training, such as proprietary software or work-in-progress code projects. Recent work has shown the promise of using context from the repository during inference. In this work, we extend this idea and propose RepoFusion, a framework to train models to incorporate relevant repository context. Experiments on single-line code completion show that our models trained with repository context significantly outperform much larger code models as CodeGen-16B-multi ($\sim73\times$ larger) and closely match the performance of the $\sim 70\times$ larger StarCoderBase model that was trained with the Fill-in-the-Middle objective. We find these results to be a novel and compelling demonstration of the gains that training with repository context can bring. We carry out extensive ablation studies to investigate the impact of design choices such as context type, number of contexts, context length, and initialization within our framework. Lastly, we release Stack-Repo, a dataset of 200 Java repositories with permissive licenses and near-deduplicated files that are augmented with three types of repository contexts. Additionally, we are making available the code and trained checkpoints for our work. Our released resources can be found at \url{https://huggingface.co/RepoFusion}.
Approach Intelligent Writing Assistants Usability with Seven Stages of Action
Apr 06, 2023Despite the potential of Large Language Models (LLMs) as writing assistants, they are plagued by issues like coherence and fluency of the model output, trustworthiness, ownership of the generated content, and predictability of model performance, thereby limiting their usability. In this position paper, we propose to adopt Norman's seven stages of action as a framework to approach the interaction design of intelligent writing assistants. We illustrate the framework's applicability to writing tasks by providing an example of software tutorial authoring. The paper also discusses the framework as a tool to synthesize research on the interaction design of LLM-based tools and presents examples of tools that support the stages of action. Finally, we briefly outline the potential of a framework for human-LLM interaction research.
Repository-Level Prompt Generation for Large Language Models of Code
Jun 26, 2022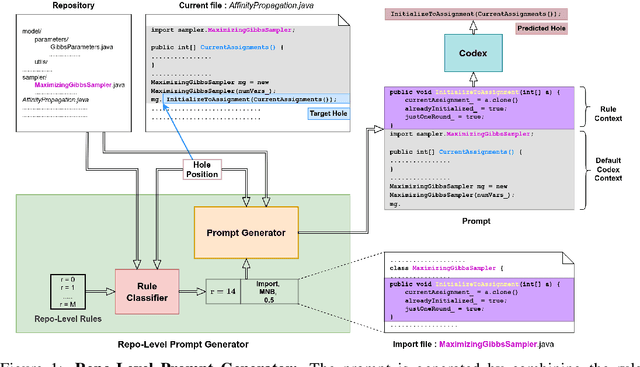
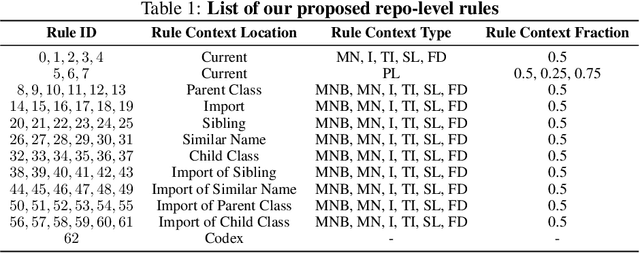

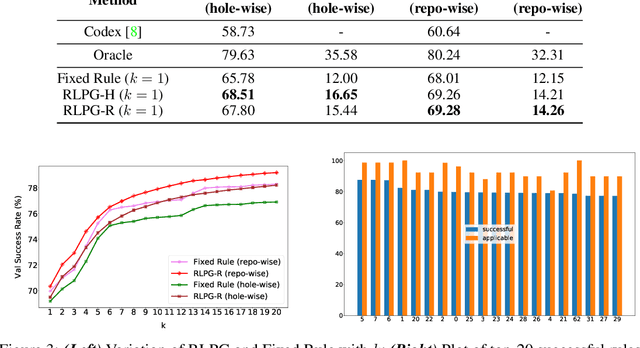
With the success of large language models (LLMs) of code and their use as code assistants (e.g. Codex used in GitHub Copilot), techniques for introducing domain-specific knowledge in the prompt design process become important. In this work, we propose a framework called Repo-Level Prompt Generator that learns to generate example-specific prompts using a set of rules. These rules take context from the entire repository, thereby incorporating both the structure of the repository and the context from other relevant files (e.g. imports, parent class files). Our technique doesn't require any access to the weights of the LLM, making it applicable in cases where we only have black-box access to the LLM. We conduct experiments on the task of single-line code-autocompletion using code repositories taken from Google Code archives. We demonstrate that an oracle constructed from our proposed rules gives up to 36% relative improvement over Codex, showing the quality of the rules. Further, we show that when we train a model to select the best rule, we can achieve significant performance gains over Codex. The code for our work can be found at: https://github.com/shrivastavadisha/repo_level_prompt_generation.
Learning to Combine Per-Example Solutions for Neural Program Synthesis
Jun 14, 2021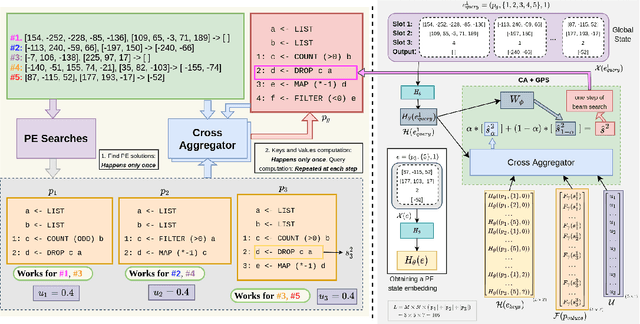

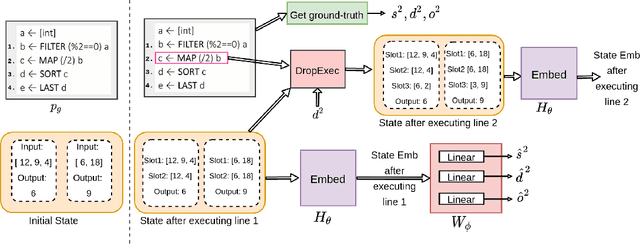
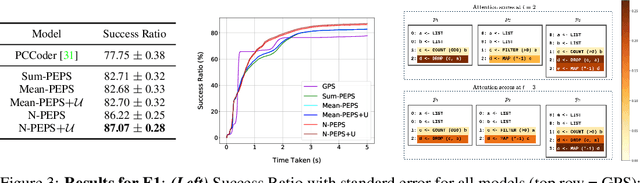
The goal of program synthesis from examples is to find a computer program that is consistent with a given set of input-output examples. Most learning-based approaches try to find a program that satisfies all examples at once. Our work, by contrast, considers an approach that breaks the problem into two stages: (a) find programs that satisfy only one example, and (b) leverage these per-example solutions to yield a program that satisfies all examples. We introduce the Cross Aggregator neural network module based on a multi-head attention mechanism that learns to combine the cues present in these per-example solutions to synthesize a global solution. Evaluation across programs of different lengths and under two different experimental settings reveal that when given the same time budget, our technique significantly improves the success rate over PCCoder arXiv:1809.04682v2 [cs.LG] and other ablation baselines. The code, data and trained models for our work can be found at https://github.com/shrivastavadisha/N-PEPS.
Minimax and Neyman-Pearson Meta-Learning for Outlier Languages
Jun 02, 2021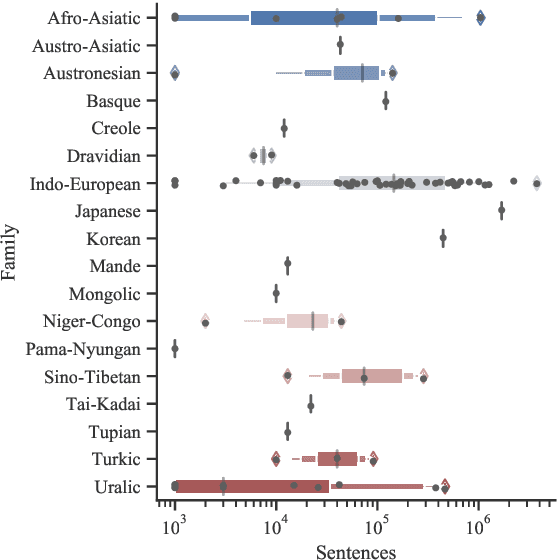
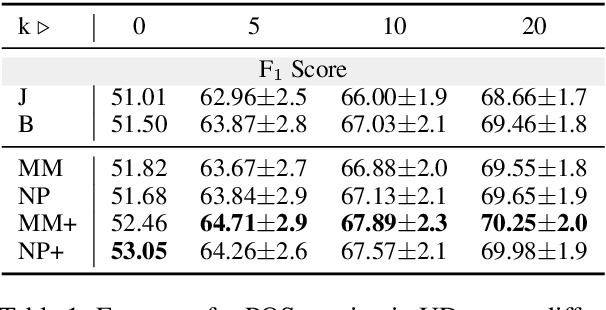
Model-agnostic meta-learning (MAML) has been recently put forth as a strategy to learn resource-poor languages in a sample-efficient fashion. Nevertheless, the properties of these languages are often not well represented by those available during training. Hence, we argue that the i.i.d. assumption ingrained in MAML makes it ill-suited for cross-lingual NLP. In fact, under a decision-theoretic framework, MAML can be interpreted as minimising the expected risk across training languages (with a uniform prior), which is known as Bayes criterion. To increase its robustness to outlier languages, we create two variants of MAML based on alternative criteria: Minimax MAML reduces the maximum risk across languages, while Neyman-Pearson MAML constrains the risk in each language to a maximum threshold. Both criteria constitute fully differentiable two-player games. In light of this, we propose a new adaptive optimiser solving for a local approximation to their Nash equilibrium. We evaluate both model variants on two popular NLP tasks, part-of-speech tagging and question answering. We report gains for their average and minimum performance across low-resource languages in zero- and few-shot settings, compared to joint multi-source transfer and vanilla MAML.
On-the-Fly Adaptation of Source Code Models using Meta-Learning
Mar 26, 2020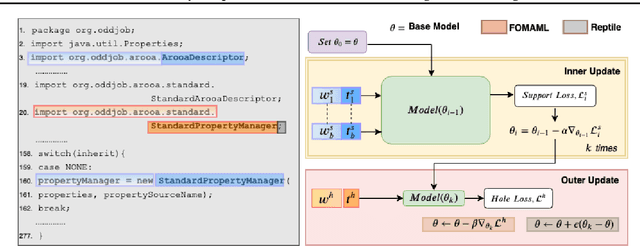
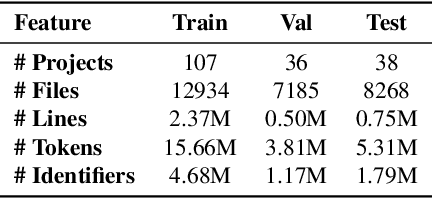

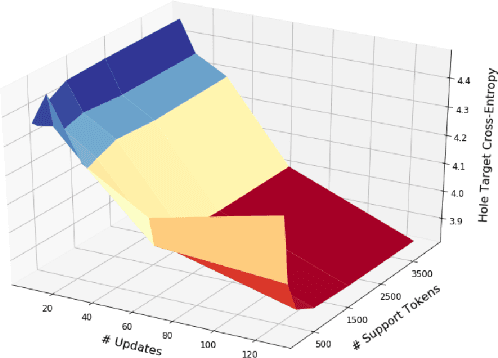
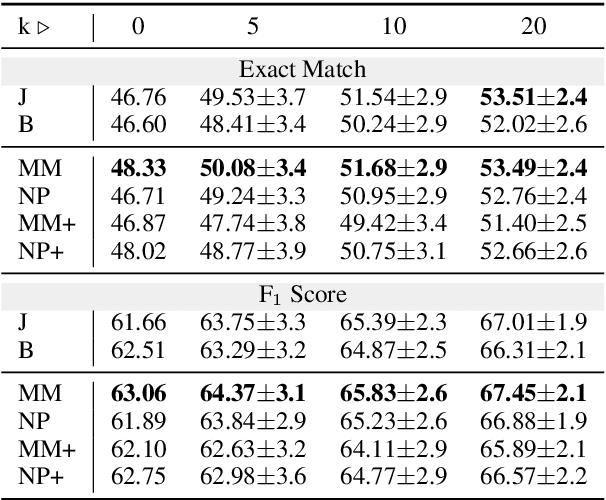
The ability to adapt to unseen, local contexts is an important challenge that successful models of source code must overcome. One of the most popular approaches for the adaptation of such models is dynamic evaluation. With dynamic evaluation, when running a model on an unseen file, the model is updated immediately after having observed each token in that file. In this work, we propose instead to frame the problem of context adaptation as a meta-learning problem. We aim to train a base source code model that is best able to learn from information in a file to deliver improved predictions of missing tokens. Unlike dynamic evaluation, this formulation allows us to select more targeted information (support tokens) for adaptation, that is both before and after a target hole in a file. We consider an evaluation setting that we call line-level maintenance, designed to reflect the downstream task of code auto-completion in an IDE. Leveraging recent developments in meta-learning such as first-order MAML and Reptile, we demonstrate improved performance in experiments on a large scale Java GitHub corpus, compared to other adaptation baselines including dynamic evaluation. Moreover, our analysis shows that, compared to a non-adaptive baseline, our approach improves performance on identifiers and literals by 44\% and 15\%, respectively. Our implementation can be found at: https://github.com/shrivastavadisha/meta_learn_source_code
Transfer Learning by Modeling a Distribution over Policies
Jun 09, 2019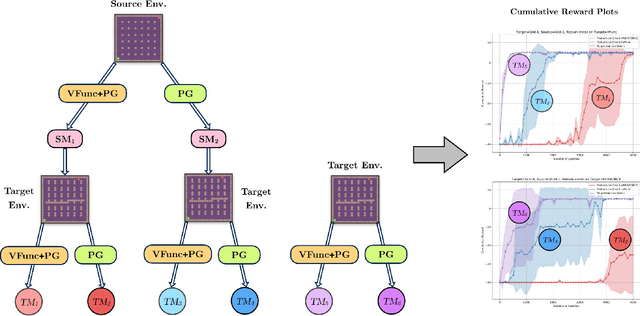
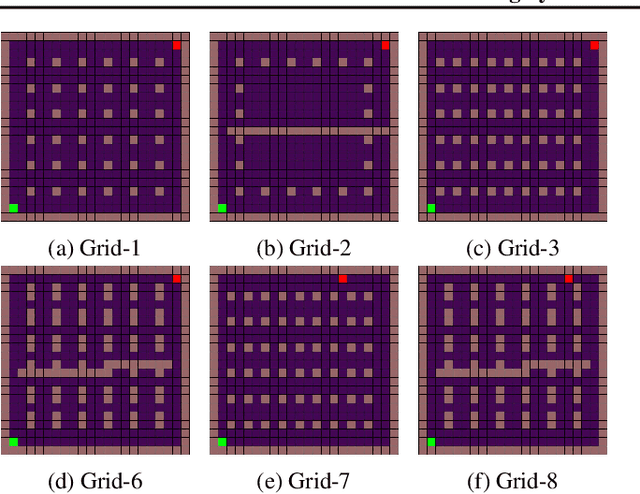
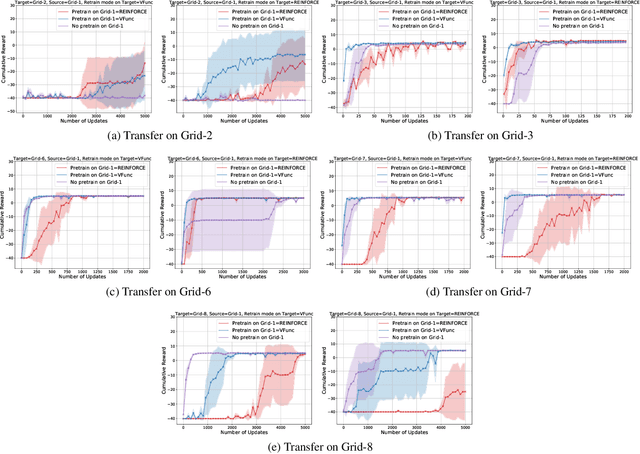

Exploration and adaptation to new tasks in a transfer learning setup is a central challenge in reinforcement learning. In this work, we build on the idea of modeling a distribution over policies in a Bayesian deep reinforcement learning setup to propose a transfer strategy. Recent works have shown to induce diversity in the learned policies by maximizing the entropy of a distribution of policies (Bachman et al., 2018; Garnelo et al., 2018) and thus, we postulate that our proposed approach leads to faster exploration resulting in improved transfer learning. We support our hypothesis by demonstrating favorable experimental results on a variety of settings on fully-observable GridWorld and partially observable MiniGrid (Chevalier-Boisvert et al., 2018) environments.