 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn-the-Fly Adaptation of Source Code Models using Meta-Learning
Paper and Code
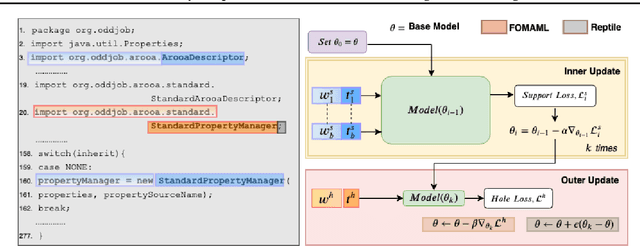
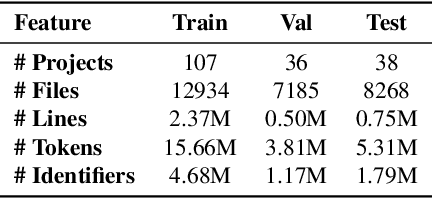

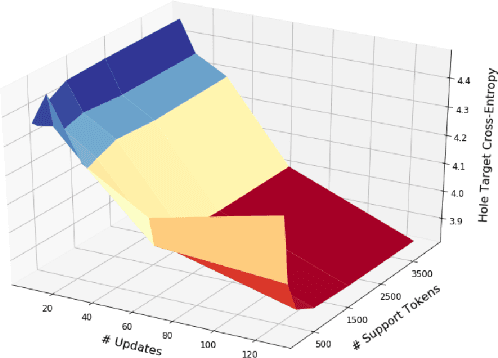
The ability to adapt to unseen, local contexts is an important challenge that successful models of source code must overcome. One of the most popular approaches for the adaptation of such models is dynamic evaluation. With dynamic evaluation, when running a model on an unseen file, the model is updated immediately after having observed each token in that file. In this work, we propose instead to frame the problem of context adaptation as a meta-learning problem. We aim to train a base source code model that is best able to learn from information in a file to deliver improved predictions of missing tokens. Unlike dynamic evaluation, this formulation allows us to select more targeted information (support tokens) for adaptation, that is both before and after a target hole in a file. We consider an evaluation setting that we call line-level maintenance, designed to reflect the downstream task of code auto-completion in an IDE. Leveraging recent developments in meta-learning such as first-order MAML and Reptile, we demonstrate improved performance in experiments on a large scale Java GitHub corpus, compared to other adaptation baselines including dynamic evaluation. Moreover, our analysis shows that, compared to a non-adaptive baseline, our approach improves performance on identifiers and literals by 44\% and 15\%, respectively. Our implementation can be found at: https://github.com/shrivastavadisha/meta_learn_source_code