 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnlearning in- vs. out-of-distribution data in LLMs under gradient-based method
Nov 07, 2024



Machine unlearning aims to solve the problem of removing the influence of selected training examples from a learned model. Despite the increasing attention to this problem, it remains an open research question how to evaluate unlearning in large language models (LLMs), and what are the critical properties of the data to be unlearned that affect the quality and efficiency of unlearning. This work formalizes a metric to evaluate unlearning quality in generative models, and uses it to assess the trade-offs between unlearning quality and performance. We demonstrate that unlearning out-of-distribution examples requires more unlearning steps but overall presents a better trade-off overall. For in-distribution examples, however, we observe a rapid decay in performance as unlearning progresses. We further evaluate how example's memorization and difficulty affect unlearning under a classical gradient ascent-based approach.
AI-Assisted Assessment of Coding Practices in Modern Code Review
May 22, 2024



Modern code review is a process in which an incremental code contribution made by a code author is reviewed by one or more peers before it is committed to the version control system. An important element of modern code review is verifying that code contributions adhere to best practices. While some of these best practices can be automatically verified, verifying others is commonly left to human reviewers. This paper reports on the development, deployment, and evaluation of AutoCommenter, a system backed by a large language model that automatically learns and enforces coding best practices. We implemented AutoCommenter for four programming languages (C++, Java, Python, and Go) and evaluated its performance and adoption in a large industrial setting. Our evaluation shows that an end-to-end system for learning and enforcing coding best practices is feasible and has a positive impact on the developer workflow. Additionally, this paper reports on the challenges associated with deploying such a system to tens of thousands of developers and the corresponding lessons learned.
Experts Don't Cheat: Learning What You Don't Know By Predicting Pairs
Feb 13, 2024



Identifying how much a model ${\widehat{p}}_{\theta}(Y|X)$ knows about the stochastic real-world process $p(Y|X)$ it was trained on is important to ensure it avoids producing incorrect or "hallucinated" answers or taking unsafe actions. But this is difficult for generative models because probabilistic predictions do not distinguish between per-response noise (aleatoric uncertainty) and lack of knowledge about the process (epistemic uncertainty), and existing epistemic uncertainty quantification techniques tend to be overconfident when the model underfits. We propose a general strategy for teaching a model to both approximate $p(Y|X)$ and also estimate the remaining gaps between ${\widehat{p}}_{\theta}(Y|X)$ and $p(Y|X)$: train it to predict pairs of independent responses drawn from the true conditional distribution, allow it to "cheat" by observing one response while predicting the other, then measure how much it cheats. Remarkably, we prove that being good at cheating (i.e. cheating whenever it improves your prediction) is equivalent to being second-order calibrated, a principled extension of ordinary calibration that allows us to construct provably-correct frequentist confidence intervals for $p(Y|X)$ and detect incorrect responses with high probability. We demonstrate empirically that our approach accurately estimates how much models don't know across ambiguous image classification, (synthetic) language modeling, and partially-observable navigation tasks, outperforming existing techniques.
R-U-SURE? Uncertainty-Aware Code Suggestions By Maximizing Utility Across Random User Intents
Mar 01, 2023



Large language models show impressive results at predicting structured text such as code, but also commonly introduce errors and hallucinations in their output. When used to assist software developers, these models may make mistakes that users must go back and fix, or worse, introduce subtle bugs that users may miss entirely. We propose Randomized Utility-driven Synthesis of Uncertain REgions (R-U-SURE), an approach for building uncertainty-aware suggestions based on a decision-theoretic model of goal-conditioned utility, using random samples from a generative model as a proxy for the unobserved possible intents of the end user. Our technique combines minimum-Bayes-risk decoding, dual decomposition, and decision diagrams in order to efficiently produce structured uncertainty summaries, given only sample access to an arbitrary generative model of code and an optional AST parser. We demonstrate R-U-SURE on three developer-assistance tasks, and show that it can be applied different user interaction patterns without retraining the model and leads to more accurate uncertainty estimates than token-probability baselines.
A Library for Representing Python Programs as Graphs for Machine Learning
Aug 15, 2022



Graph representations of programs are commonly a central element of machine learning for code research. We introduce an open source Python library python_graphs that applies static analysis to construct graph representations of Python programs suitable for training machine learning models. Our library admits the construction of control-flow graphs, data-flow graphs, and composite ``program graphs'' that combine control-flow, data-flow, syntactic, and lexical information about a program. We present the capabilities and limitations of the library, perform a case study applying the library to millions of competitive programming submissions, and showcase the library's utility for machine learning research.
Learning to Improve Code Efficiency
Aug 09, 2022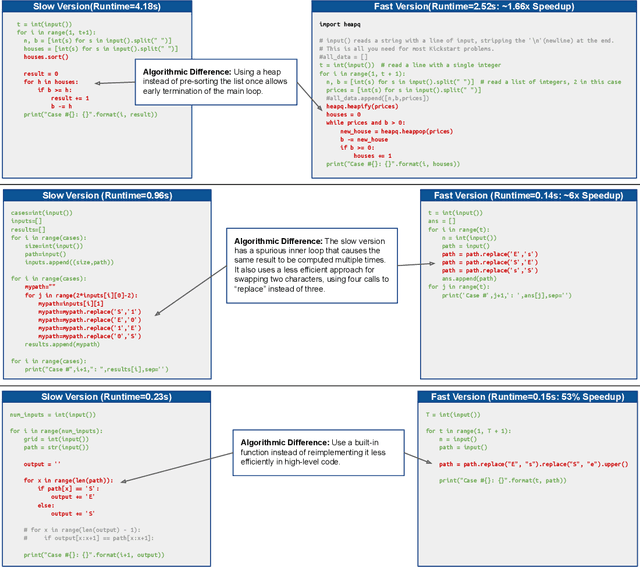
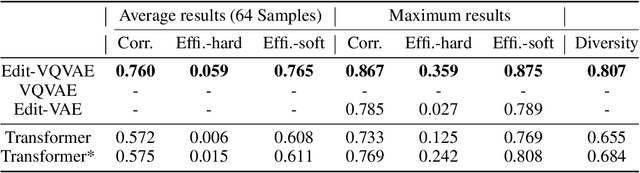
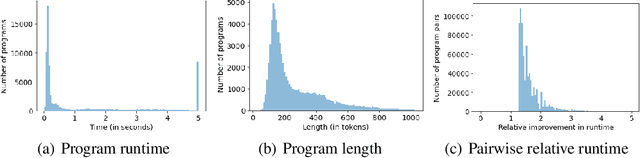

Improvements in the performance of computing systems, driven by Moore's Law, have transformed society. As such hardware-driven gains slow down, it becomes even more important for software developers to focus on performance and efficiency during development. While several studies have demonstrated the potential from such improved code efficiency (e.g., 2x better generational improvements compared to hardware), unlocking these gains in practice has been challenging. Reasoning about algorithmic complexity and the interaction of coding patterns on hardware can be challenging for the average programmer, especially when combined with pragmatic constraints around development velocity and multi-person development. This paper seeks to address this problem. We analyze a large competitive programming dataset from the Google Code Jam competition and find that efficient code is indeed rare, with a 2x runtime difference between the median and the 90th percentile of solutions. We propose using machine learning to automatically provide prescriptive feedback in the form of hints, to guide programmers towards writing high-performance code. To automatically learn these hints from the dataset, we propose a novel discrete variational auto-encoder, where each discrete latent variable represents a different learned category of code-edit that increases performance. We show that this method represents the multi-modal space of code efficiency edits better than a sequence-to-sequence baseline and generates a distribution of more efficient solutions.
Repository-Level Prompt Generation for Large Language Models of Code
Jun 26, 2022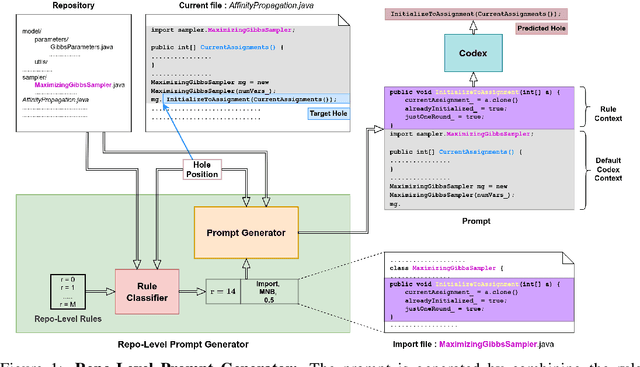
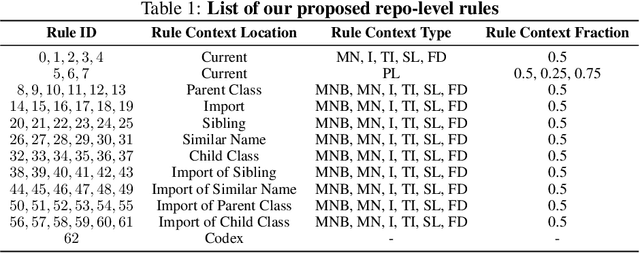

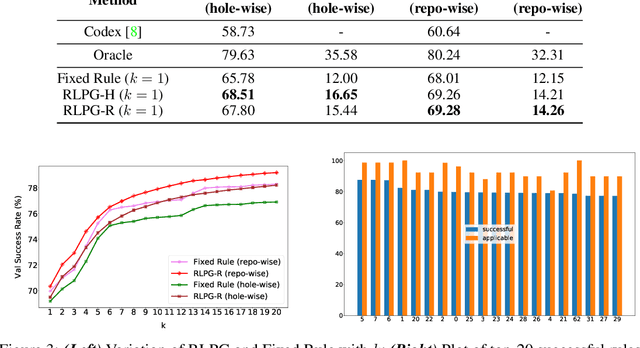
With the success of large language models (LLMs) of code and their use as code assistants (e.g. Codex used in GitHub Copilot), techniques for introducing domain-specific knowledge in the prompt design process become important. In this work, we propose a framework called Repo-Level Prompt Generator that learns to generate example-specific prompts using a set of rules. These rules take context from the entire repository, thereby incorporating both the structure of the repository and the context from other relevant files (e.g. imports, parent class files). Our technique doesn't require any access to the weights of the LLM, making it applicable in cases where we only have black-box access to the LLM. We conduct experiments on the task of single-line code-autocompletion using code repositories taken from Google Code archives. We demonstrate that an oracle constructed from our proposed rules gives up to 36% relative improvement over Codex, showing the quality of the rules. Further, we show that when we train a model to select the best rule, we can achieve significant performance gains over Codex. The code for our work can be found at: https://github.com/shrivastavadisha/repo_level_prompt_generation.
Static Prediction of Runtime Errors by Learning to Execute Programs with External Resource Descriptions
Mar 07, 2022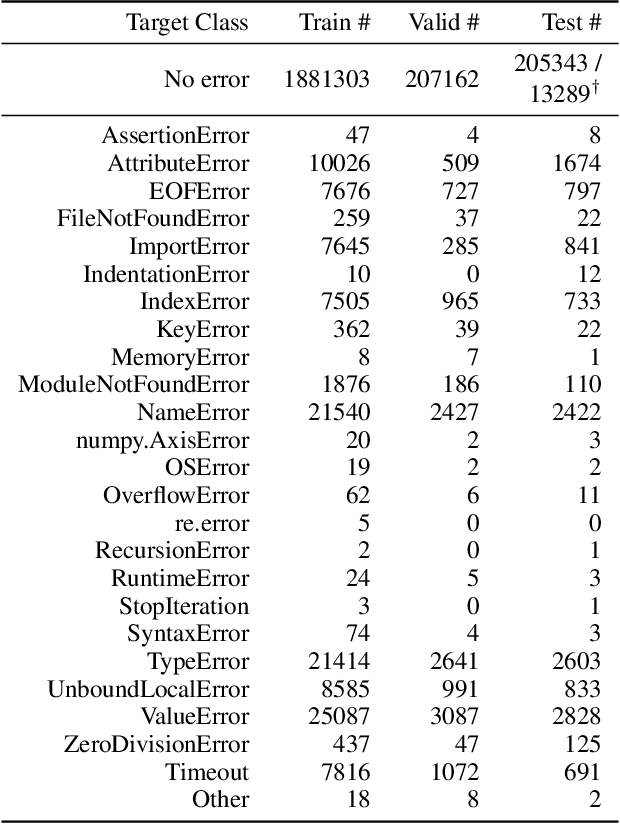

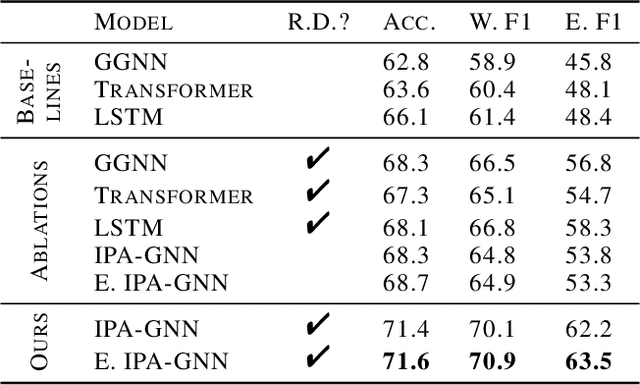
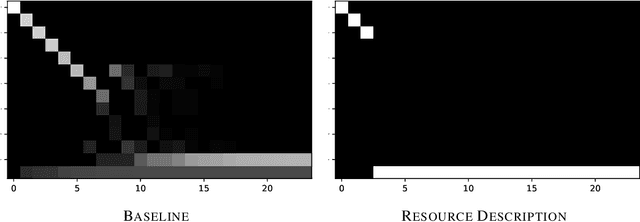
The execution behavior of a program often depends on external resources, such as program inputs or file contents, and so cannot be run in isolation. Nevertheless, software developers benefit from fast iteration loops where automated tools identify errors as early as possible, even before programs can be compiled and run. This presents an interesting machine learning challenge: can we predict runtime errors in a "static" setting, where program execution is not possible? Here, we introduce a real-world dataset and task for predicting runtime errors, which we show is difficult for generic models like Transformers. We approach this task by developing an interpreter-inspired architecture with an inductive bias towards mimicking program executions, which models exception handling and "learns to execute" descriptions of the contents of external resources. Surprisingly, we show that the model can also predict the location of the error, despite being trained only on labels indicating the presence/absence and kind of error. In total, we present a practical and difficult-yet-approachable challenge problem related to learning program execution and we demonstrate promising new capabilities of interpreter-inspired machine learning models for code.
Learning Generalized Gumbel-max Causal Mechanisms
Nov 11, 2021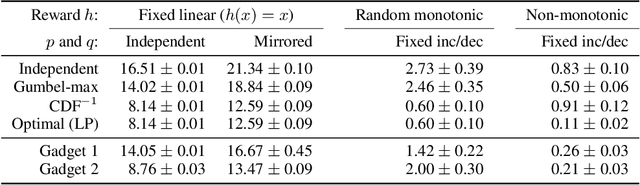
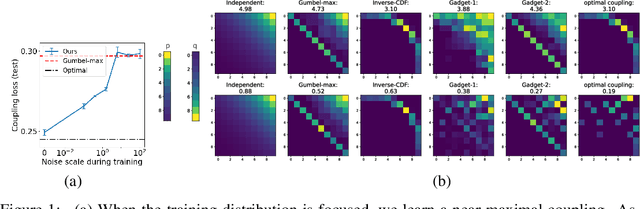

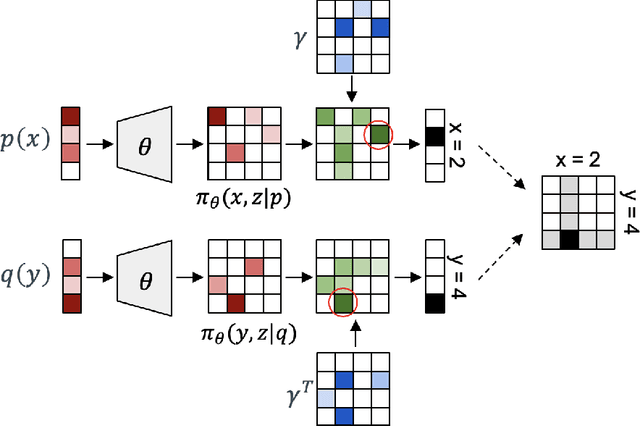
To perform counterfactual reasoning in Structural Causal Models (SCMs), one needs to know the causal mechanisms, which provide factorizations of conditional distributions into noise sources and deterministic functions mapping realizations of noise to samples. Unfortunately, the causal mechanism is not uniquely identified by data that can be gathered by observing and interacting with the world, so there remains the question of how to choose causal mechanisms. In recent work, Oberst & Sontag (2019) propose Gumbel-max SCMs, which use Gumbel-max reparameterizations as the causal mechanism due to an intuitively appealing counterfactual stability property. In this work, we instead argue for choosing a causal mechanism that is best under a quantitative criteria such as minimizing variance when estimating counterfactual treatment effects. We propose a parameterized family of causal mechanisms that generalize Gumbel-max. We show that they can be trained to minimize counterfactual effect variance and other losses on a distribution of queries of interest, yielding lower variance estimates of counterfactual treatment effect than fixed alternatives, also generalizing to queries not seen at training time.
Beyond In-Place Corruption: Insertion and Deletion In Denoising Probabilistic Models
Jul 16, 2021
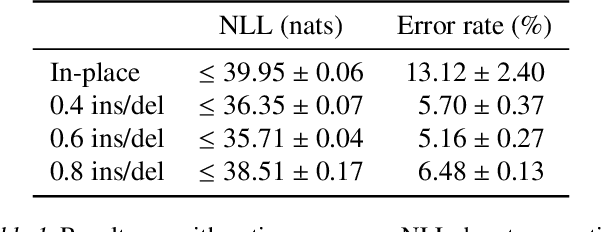
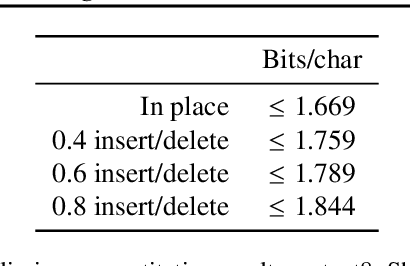
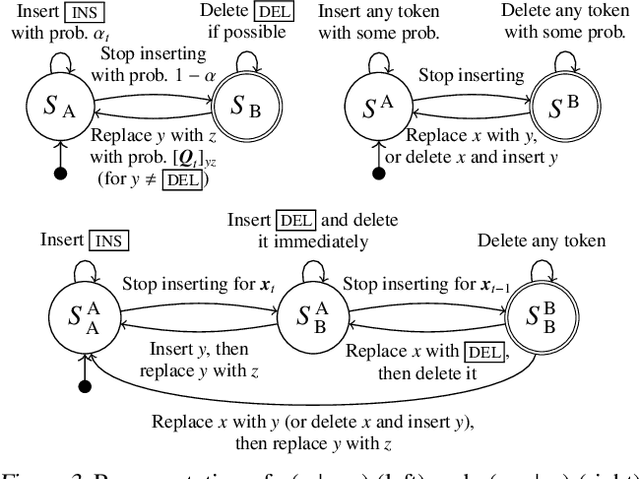
Denoising diffusion probabilistic models (DDPMs) have shown impressive results on sequence generation by iteratively corrupting each example and then learning to map corrupted versions back to the original. However, previous work has largely focused on in-place corruption, adding noise to each pixel or token individually while keeping their locations the same. In this work, we consider a broader class of corruption processes and denoising models over sequence data that can insert and delete elements, while still being efficient to train and sample from. We demonstrate that these models outperform standard in-place models on an arithmetic sequence task, and that when trained on the text8 dataset they can be used to fix spelling errors without any fine-tuning.