 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTransfer Learning by Modeling a Distribution over Policies
Paper and Code
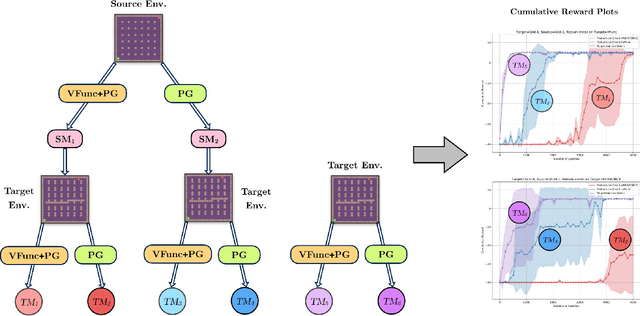
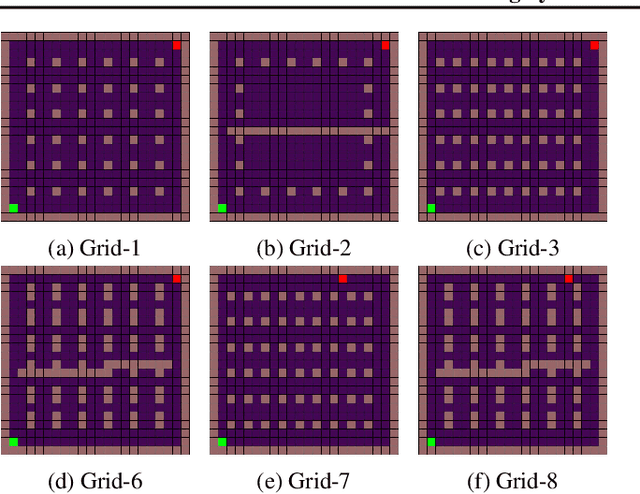
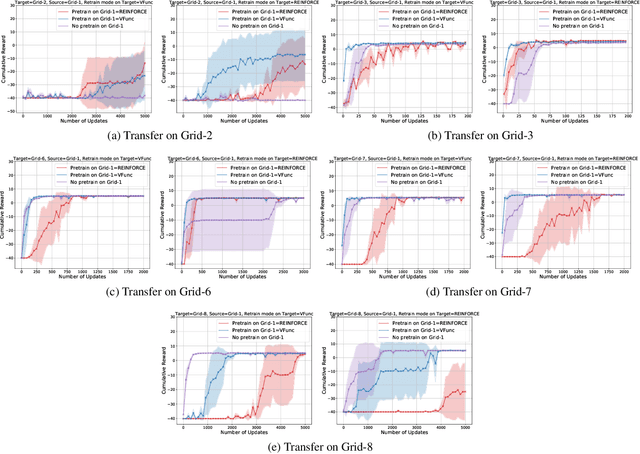

Exploration and adaptation to new tasks in a transfer learning setup is a central challenge in reinforcement learning. In this work, we build on the idea of modeling a distribution over policies in a Bayesian deep reinforcement learning setup to propose a transfer strategy. Recent works have shown to induce diversity in the learned policies by maximizing the entropy of a distribution of policies (Bachman et al., 2018; Garnelo et al., 2018) and thus, we postulate that our proposed approach leads to faster exploration resulting in improved transfer learning. We support our hypothesis by demonstrating favorable experimental results on a variety of settings on fully-observable GridWorld and partially observable MiniGrid (Chevalier-Boisvert et al., 2018) environments.