 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScaling Properties of Continuous Diffusion Spoken Language Models
Apr 27, 2026Speech-only spoken language models (SLMs) lag behind text and text-speech models in performance, with recent discrete autoregressive (AR) SLMs indicating significant computational and data demands to match text models. Since discretizing continuous speech for AR creates bottlenecks, we explore whether continuous diffusion (CD) SLM is more viable. To quantify the SLMs linguistic quality, we introduce the phoneme Jensen-Shannon divergence (pJSD) metric. Our analysis reveals CD SLMs, mirroring AR behavior, exhibit scaling laws for validation loss and pJSD, and show optimal token-to-parameter ratios decreasing as compute scales. However, for the latter, loss becomes insensitive to choice of data and model sizes, showing potential for fast inference. Scaling CD SLMs to 16B parameters with tens of millions of hours of conversational data enables generation of emotive, prosodic, multi-speaker, multilingual speech, though achieving long-form coherence remains a significant challenge.
Self-reflective Uncertainties: Do LLMs Know Their Internal Answer Distribution?
May 26, 2025To reveal when a large language model (LLM) is uncertain about a response, uncertainty quantification commonly produces percentage numbers along with the output. But is this all we can do? We argue that in the output space of LLMs, the space of strings, exist strings expressive enough to summarize the distribution over output strings the LLM deems possible. We lay a foundation for this new avenue of uncertainty explication and present SelfReflect, a theoretically-motivated metric to assess how faithfully a string summarizes an LLM's internal answer distribution. We show that SelfReflect is able to discriminate even subtle differences of candidate summary strings and that it aligns with human judgement, outperforming alternative metrics such as LLM judges and embedding comparisons. With SelfReflect, we investigate a number of self-summarization methods and find that even state-of-the-art reasoning models struggle to explicate their internal uncertainty. But we find that faithful summarizations can be generated by sampling and summarizing. Our metric enables future works towards this universal form of LLM uncertainties.
Poly-View Contrastive Learning
Mar 08, 2024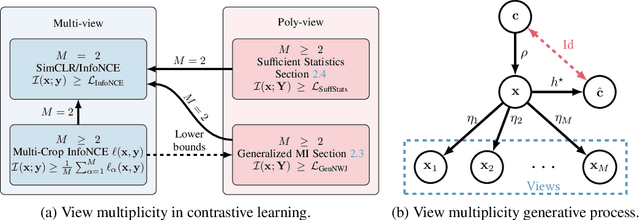

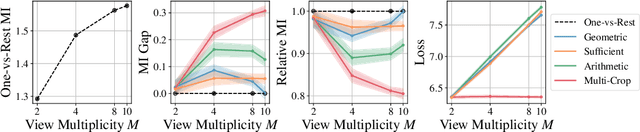
Contrastive learning typically matches pairs of related views among a number of unrelated negative views. Views can be generated (e.g. by augmentations) or be observed. We investigate matching when there are more than two related views which we call poly-view tasks, and derive new representation learning objectives using information maximization and sufficient statistics. We show that with unlimited computation, one should maximize the number of related views, and with a fixed compute budget, it is beneficial to decrease the number of unique samples whilst increasing the number of views of those samples. In particular, poly-view contrastive models trained for 128 epochs with batch size 256 outperform SimCLR trained for 1024 epochs at batch size 4096 on ImageNet1k, challenging the belief that contrastive models require large batch sizes and many training epochs.
How to Scale Your EMA
Jul 27, 2023



Preserving training dynamics across batch sizes is an important tool for practical machine learning as it enables the trade-off between batch size and wall-clock time. This trade-off is typically enabled by a scaling rule, for example, in stochastic gradient descent, one should scale the learning rate linearly with the batch size. Another important tool for practical machine learning is the model Exponential Moving Average (EMA), which is a model copy that does not receive gradient information, but instead follows its target model with some momentum. This model EMA can improve the robustness and generalization properties of supervised learning, stabilize pseudo-labeling, and provide a learning signal for Self-Supervised Learning (SSL). Prior works have treated the model EMA separately from optimization, leading to different training dynamics across batch sizes and lower model performance. In this work, we provide a scaling rule for optimization in the presence of model EMAs and demonstrate its validity across a range of architectures, optimizers, and data modalities. We also show the rule's validity where the model EMA contributes to the optimization of the target model, enabling us to train EMA-based pseudo-labeling and SSL methods at small and large batch sizes. For SSL, we enable training of BYOL up to batch size 24,576 without sacrificing performance, optimally a 6$\times$ wall-clock time reduction.
Elastic Weight Consolidation Improves the Robustness of Self-Supervised Learning Methods under Transfer
Oct 28, 2022Self-supervised representation learning (SSL) methods provide an effective label-free initial condition for fine-tuning downstream tasks. However, in numerous realistic scenarios, the downstream task might be biased with respect to the target label distribution. This in turn moves the learned fine-tuned model posterior away from the initial (label) bias-free self-supervised model posterior. In this work, we re-interpret SSL fine-tuning under the lens of Bayesian continual learning and consider regularization through the Elastic Weight Consolidation (EWC) framework. We demonstrate that self-regularization against an initial SSL backbone improves worst sub-group performance in Waterbirds by 5% and Celeb-A by 2% when using the ViT-B/16 architecture. Furthermore, to help simplify the use of EWC with SSL, we pre-compute and publicly release the Fisher Information Matrix (FIM), evaluated with 10,000 ImageNet-1K variates evaluated on large modern SSL architectures including ViT-B/16 and ResNet50 trained with DINO.
Transfer Learning by Modeling a Distribution over Policies
Jun 09, 2019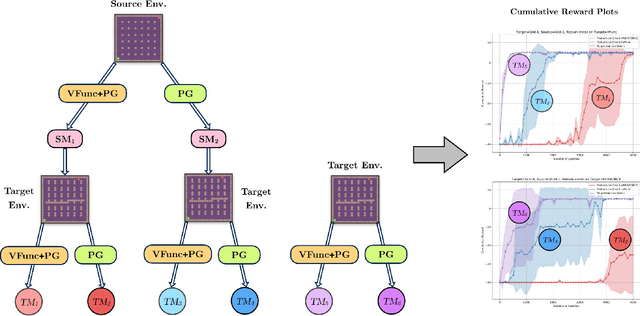
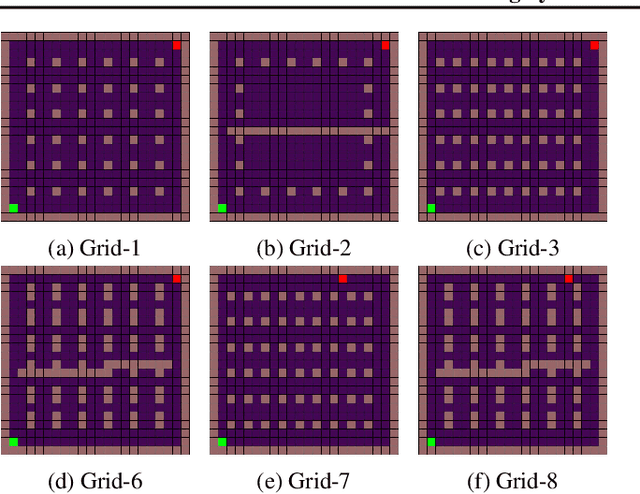
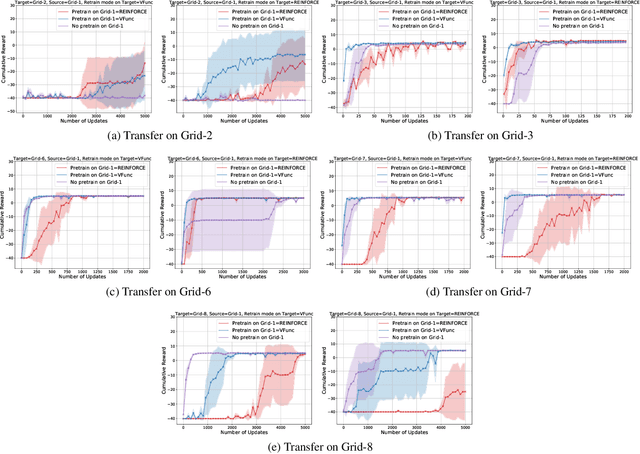

Exploration and adaptation to new tasks in a transfer learning setup is a central challenge in reinforcement learning. In this work, we build on the idea of modeling a distribution over policies in a Bayesian deep reinforcement learning setup to propose a transfer strategy. Recent works have shown to induce diversity in the learned policies by maximizing the entropy of a distribution of policies (Bachman et al., 2018; Garnelo et al., 2018) and thus, we postulate that our proposed approach leads to faster exploration resulting in improved transfer learning. We support our hypothesis by demonstrating favorable experimental results on a variety of settings on fully-observable GridWorld and partially observable MiniGrid (Chevalier-Boisvert et al., 2018) environments.
Learning Affective Correspondence between Music and Image
Apr 17, 2019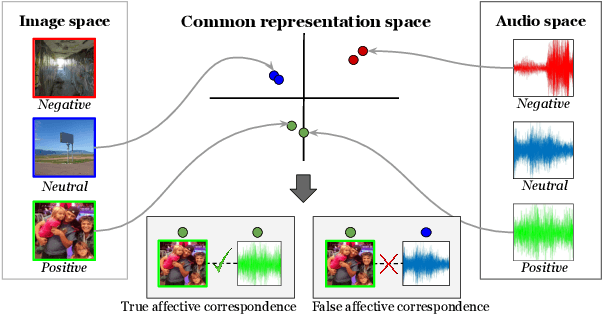


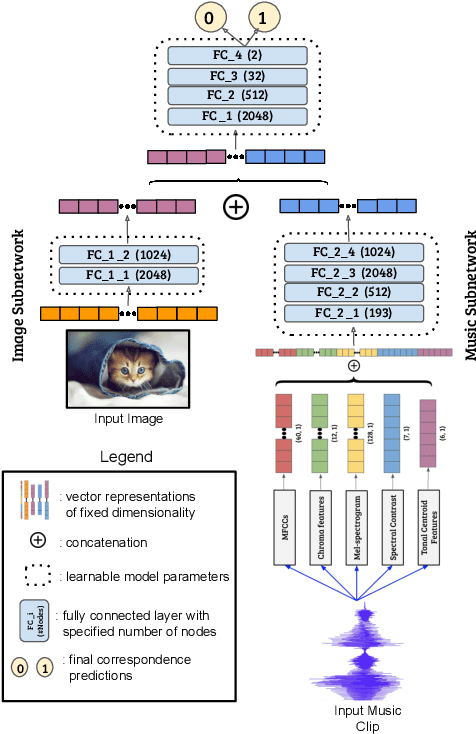
We introduce the problem of learning affective correspondence between audio (music) and visual data (images). For this task, a music clip and an image are considered similar (having true correspondence) if they have similar emotion content. In order to estimate this crossmodal, emotion-centric similarity, we propose a deep neural network architecture that learns to project the data from the two modalities to a common representation space, and performs a binary classification task of predicting the affective correspondence (true or false). To facilitate the current study, we construct a large scale database containing more than $3,500$ music clips and $85,000$ images with three emotion classes (positive, neutral, negative). The proposed approach achieves $61.67\%$ accuracy for the affective correspondence prediction task on this database, outperforming two relevant and competitive baselines. We also demonstrate that our network learns modality-specific representations of emotion (without explicitly being trained with emotion labels), which are useful for emotion recognition in individual modalities.