 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExpanding LLM Agent Boundaries with Strategy-Guided Exploration
Mar 02, 2026Reinforcement learning (RL) has demonstrated notable success in post-training large language models (LLMs) as agents for tasks such as computer use, tool calling, and coding. However, exploration remains a central challenge in RL for LLM agents, especially as they operate in language-action spaces with complex observations and sparse outcome rewards. In this work, we address exploration for LLM agents by leveraging the ability of LLMs to plan and reason in language about the environment to shift exploration from low-level actions to higher-level language strategies. We thus propose Strategy-Guided Exploration (SGE), which first generates a concise natural-language strategy that describes what to do to make progress toward the goal, and then generates environment actions conditioned on that strategy. By exploring in the space of strategies rather than the space of actions, SGE induces structured and diverse exploration that targets different environment outcomes. To increase strategy diversity during RL, SGE introduces mixed-temperature sampling, which explores diverse strategies in parallel, along with a strategy reflection process that grounds strategy generation on the outcomes of previous strategies in the environment. Across UI interaction, tool-calling, coding, and embodied agent environments, SGE consistently outperforms exploration-focused RL baselines, improving both learning efficiency and final performance. We show that SGE enables the agent to learn to solve tasks too difficult for the base model.
LaCy: What Small Language Models Can and Should Learn is Not Just a Question of Loss
Feb 13, 2026Language models have consistently grown to compress more world knowledge into their parameters, but the knowledge that can be pretrained into them is upper-bounded by their parameter size. Especially the capacity of Small Language Models (SLMs) is limited, leading to factually incorrect generations. This problem is often mitigated by giving the SLM access to an outside source: the ability to query a larger model, documents, or a database. Under this setting, we study the fundamental question of \emph{which tokens an SLM can and should learn} during pretraining, versus \emph{which ones it should delegate} via a \texttt{<CALL>} token. We find that this is not simply a question of loss: although the loss is predictive of whether a predicted token mismatches the ground-truth, some tokens are \emph{acceptable} in that they are truthful alternative continuations of a pretraining document, and should not trigger a \texttt{<CALL>} even if their loss is high. We find that a spaCy grammar parser can help augment the loss signal to decide which tokens the SLM should learn to delegate to prevent factual errors and which are safe to learn and predict even under high losses. We propose LaCy, a novel pretraining method based on this token selection philosophy. Our experiments demonstrate that LaCy models successfully learn which tokens to predict and where to delegate for help. This results in higher FactScores when generating in a cascade with a bigger model and outperforms Rho or LLM-judge trained SLMs, while being simpler and cheaper.
Learning Unmasking Policies for Diffusion Language Models
Dec 12, 2025Diffusion (Large) Language Models (dLLMs) now match the downstream performance of their autoregressive counterparts on many tasks, while holding the promise of being more efficient during inference. One particularly successful variant is masked discrete diffusion, in which a buffer filled with special mask tokens is progressively replaced with tokens sampled from the model's vocabulary. Efficiency can be gained by unmasking several tokens in parallel, but doing too many at once risks degrading the generation quality. Thus, one critical design aspect of dLLMs is the sampling procedure that selects, at each step of the diffusion process, which tokens to replace. Indeed, recent work has found that heuristic strategies such as confidence thresholding lead to both higher quality and token throughput compared to random unmasking. However, such heuristics have downsides: they require manual tuning, and we observe that their performance degrades with larger buffer sizes. In this work, we instead propose to train sampling procedures using reinforcement learning. Specifically, we formalize masked diffusion sampling as a Markov decision process in which the dLLM serves as the environment, and propose a lightweight policy architecture based on a single-layer transformer that maps dLLM token confidences to unmasking decisions. Our experiments show that these trained policies match the performance of state-of-the-art heuristics when combined with semi-autoregressive generation, while outperforming them in the full diffusion setting. We also examine the transferability of these policies, finding that they can generalize to new underlying dLLMs and longer sequence lengths. However, we also observe that their performance degrades when applied to out-of-domain data, and that fine-grained tuning of the accuracy-efficiency trade-off can be challenging with our approach.
Trained on Tokens, Calibrated on Concepts: The Emergence of Semantic Calibration in LLMs
Nov 06, 2025Large Language Models (LLMs) often lack meaningful confidence estimates for their outputs. While base LLMs are known to exhibit next-token calibration, it remains unclear whether they can assess confidence in the actual meaning of their responses beyond the token level. We find that, when using a certain sampling-based notion of semantic calibration, base LLMs are remarkably well-calibrated: they can meaningfully assess confidence in open-domain question-answering tasks, despite not being explicitly trained to do so. Our main theoretical contribution establishes a mechanism for why semantic calibration emerges as a byproduct of next-token prediction, leveraging a recent connection between calibration and local loss optimality. The theory relies on a general definition of "B-calibration," which is a notion of calibration parameterized by a choice of equivalence classes (semantic or otherwise). This theoretical mechanism leads to a testable prediction: base LLMs will be semantically calibrated when they can easily predict their own distribution over semantic answer classes before generating a response. We state three implications of this prediction, which we validate through experiments: (1) Base LLMs are semantically calibrated across question-answering tasks, (2) RL instruction-tuning systematically breaks this calibration, and (3) chain-of-thought reasoning breaks calibration. To our knowledge, our work provides the first principled explanation of when and why semantic calibration emerges in LLMs.
BED-LLM: Intelligent Information Gathering with LLMs and Bayesian Experimental Design
Aug 28, 2025We propose a general-purpose approach for improving the ability of Large Language Models (LLMs) to intelligently and adaptively gather information from a user or other external source using the framework of sequential Bayesian experimental design (BED). This enables LLMs to act as effective multi-turn conversational agents and interactively interface with external environments. Our approach, which we call BED-LLM (Bayesian Experimental Design with Large Language Models), is based on iteratively choosing questions or queries that maximize the expected information gain (EIG) about the task of interest given the responses gathered previously. We show how this EIG can be formulated in a principled way using a probabilistic model derived from the LLM's belief distribution and provide detailed insights into key decisions in its construction. Further key to the success of BED-LLM are a number of specific innovations, such as a carefully designed estimator for the EIG, not solely relying on in-context updates for conditioning on previous responses, and a targeted strategy for proposing candidate queries. We find that BED-LLM achieves substantial gains in performance across a wide range of tests based on the 20-questions game and using the LLM to actively infer user preferences, compared to direct prompting of the LLM and other adaptive design strategies.
The Geometries of Truth Are Orthogonal Across Tasks
Jun 10, 2025Large Language Models (LLMs) have demonstrated impressive generalization capabilities across various tasks, but their claim to practical relevance is still mired by concerns on their reliability. Recent works have proposed examining the activations produced by an LLM at inference time to assess whether its answer to a question is correct. Some works claim that a "geometry of truth" can be learned from examples, in the sense that the activations that generate correct answers can be distinguished from those leading to mistakes with a linear classifier. In this work, we underline a limitation of these approaches: we observe that these "geometries of truth" are intrinsically task-dependent and fail to transfer across tasks. More precisely, we show that linear classifiers trained across distinct tasks share little similarity and, when trained with sparsity-enforcing regularizers, have almost disjoint supports. We show that more sophisticated approaches (e.g., using mixtures of probes and tasks) fail to overcome this limitation, likely because activation vectors commonly used to classify answers form clearly separated clusters when examined across tasks.
Position: Uncertainty Quantification Needs Reassessment for Large-language Model Agents
May 28, 2025Large-language models (LLMs) and chatbot agents are known to provide wrong outputs at times, and it was recently found that this can never be fully prevented. Hence, uncertainty quantification plays a crucial role, aiming to quantify the level of ambiguity in either one overall number or two numbers for aleatoric and epistemic uncertainty. This position paper argues that this traditional dichotomy of uncertainties is too limited for the open and interactive setup that LLM agents operate in when communicating with a user, and that we need to research avenues that enrich uncertainties in this novel scenario. We review the literature and find that popular definitions of aleatoric and epistemic uncertainties directly contradict each other and lose their meaning in interactive LLM agent settings. Hence, we propose three novel research directions that focus on uncertainties in such human-computer interactions: Underspecification uncertainties, for when users do not provide all information or define the exact task at the first go, interactive learning, to ask follow-up questions and reduce the uncertainty about the current context, and output uncertainties, to utilize the rich language and speech space to express uncertainties as more than mere numbers. We expect that these new ways of dealing with and communicating uncertainties will lead to LLM agent interactions that are more transparent, trustworthy, and intuitive.
Self-reflective Uncertainties: Do LLMs Know Their Internal Answer Distribution?
May 26, 2025To reveal when a large language model (LLM) is uncertain about a response, uncertainty quantification commonly produces percentage numbers along with the output. But is this all we can do? We argue that in the output space of LLMs, the space of strings, exist strings expressive enough to summarize the distribution over output strings the LLM deems possible. We lay a foundation for this new avenue of uncertainty explication and present SelfReflect, a theoretically-motivated metric to assess how faithfully a string summarizes an LLM's internal answer distribution. We show that SelfReflect is able to discriminate even subtle differences of candidate summary strings and that it aligns with human judgement, outperforming alternative metrics such as LLM judges and embedding comparisons. With SelfReflect, we investigate a number of self-summarization methods and find that even state-of-the-art reasoning models struggle to explicate their internal uncertainty. But we find that faithful summarizations can be generated by sampling and summarizing. Our metric enables future works towards this universal form of LLM uncertainties.
Revisiting Uncertainty Quantification Evaluation in Language Models: Spurious Interactions with Response Length Bias Results
Apr 18, 2025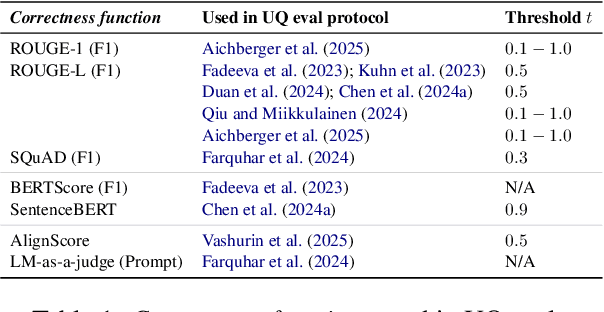
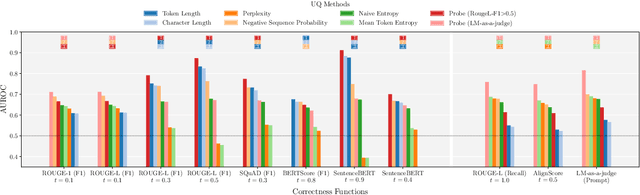
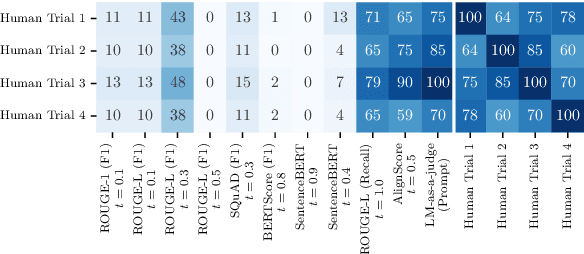
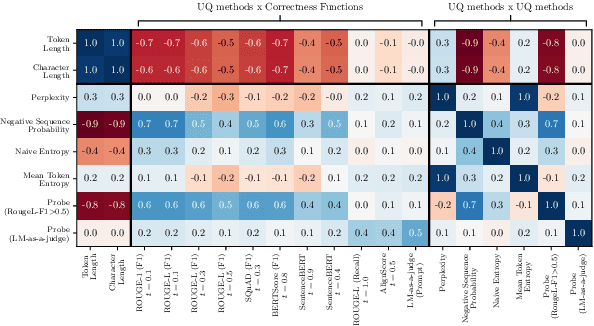
Uncertainty Quantification (UQ) in Language Models (LMs) is crucial for improving their safety and reliability. Evaluations often use performance metrics like AUROC to assess how well UQ methods (e.g., negative sequence probabilities) correlate with task correctness functions (e.g., ROUGE-L). In this paper, we show that commonly used correctness functions bias UQ evaluations by inflating the performance of certain UQ methods. We evaluate 7 correctness functions -- from lexical-based and embedding-based metrics to LLM-as-a-judge approaches -- across 4 datasets x 4 models x 6 UQ methods. Our analysis reveals that length biases in the errors of these correctness functions distort UQ assessments by interacting with length biases in UQ methods. We identify LLM-as-a-judge approaches as among the least length-biased choices and hence a potential solution to mitigate these biases.
Humanity's Last Exam
Jan 24, 2025Benchmarks are important tools for tracking the rapid advancements in large language model (LLM) capabilities. However, benchmarks are not keeping pace in difficulty: LLMs now achieve over 90\% accuracy on popular benchmarks like MMLU, limiting informed measurement of state-of-the-art LLM capabilities. In response, we introduce Humanity's Last Exam (HLE), a multi-modal benchmark at the frontier of human knowledge, designed to be the final closed-ended academic benchmark of its kind with broad subject coverage. HLE consists of 3,000 questions across dozens of subjects, including mathematics, humanities, and the natural sciences. HLE is developed globally by subject-matter experts and consists of multiple-choice and short-answer questions suitable for automated grading. Each question has a known solution that is unambiguous and easily verifiable, but cannot be quickly answered via internet retrieval. State-of-the-art LLMs demonstrate low accuracy and calibration on HLE, highlighting a significant gap between current LLM capabilities and the expert human frontier on closed-ended academic questions. To inform research and policymaking upon a clear understanding of model capabilities, we publicly release HLE at https://lastexam.ai.